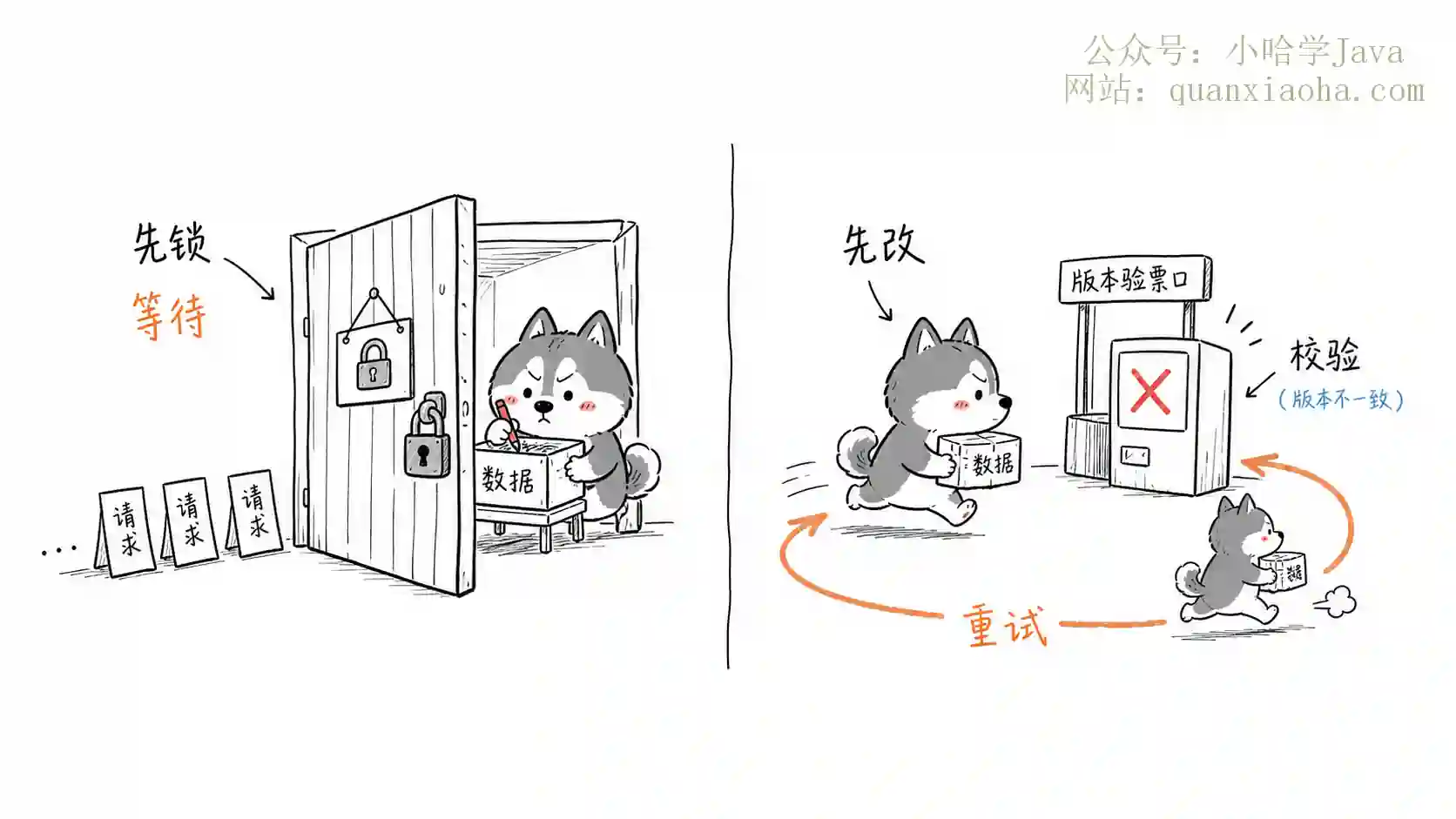
高并发场景中,乐观锁和悲观锁哪个更适合?
高并发场景下乐观锁和悲观锁怎么选?本文深度解析两者底层原理与适用场景。核心结论:写冲突低用乐观锁(CAS或版本号),冲突高用悲观锁(FOR UPDATE),秒杀扣库存等超高并发热点写需结合Redis预扣与分桶方案。助你彻底搞懂锁选型与面试实战,轻松应对高并发架构设计。
2026/8/1Java面试八股文
高并发场景下乐观锁和悲观锁怎么选?本文深度解析两者底层原理与适用场景。核心结论:写冲突低用乐观锁(CAS或版本号),冲突高用悲观锁(FOR UPDATE),秒杀扣库存等超高并发热点写需结合Redis预扣与分桶方案。助你彻底搞懂锁选型与面试实战,轻松应对高并发架构设计。
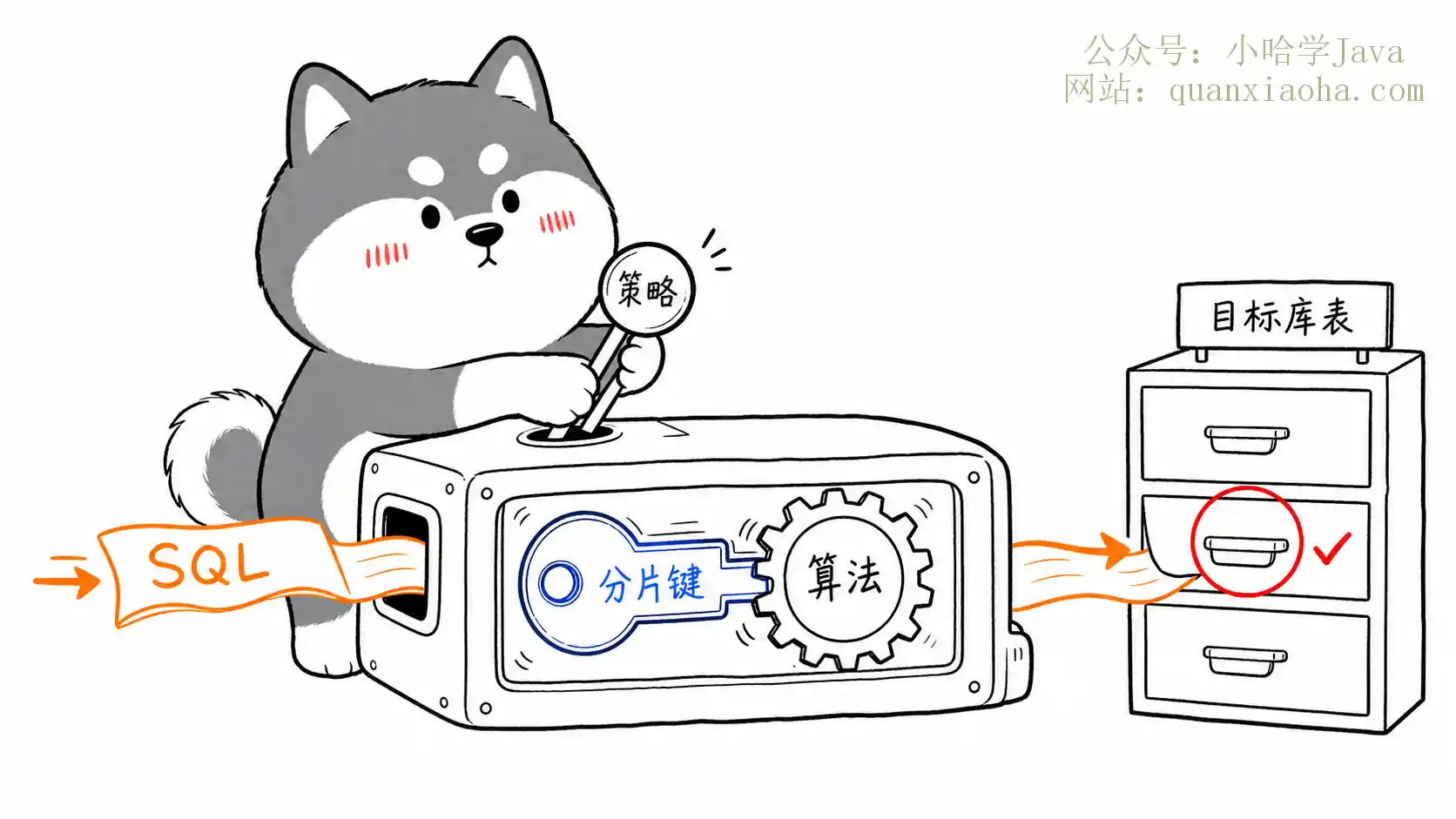
ShardingJDBC 分片策略怎么选?本文深度解析行表达式、标准、复合、Hint及不分片5大核心分片策略与分片算法的底层原理。结合订单系统实战经验,教你如何精准选择分片键,避免全路由广播,轻松应对面试追问与项目选型。
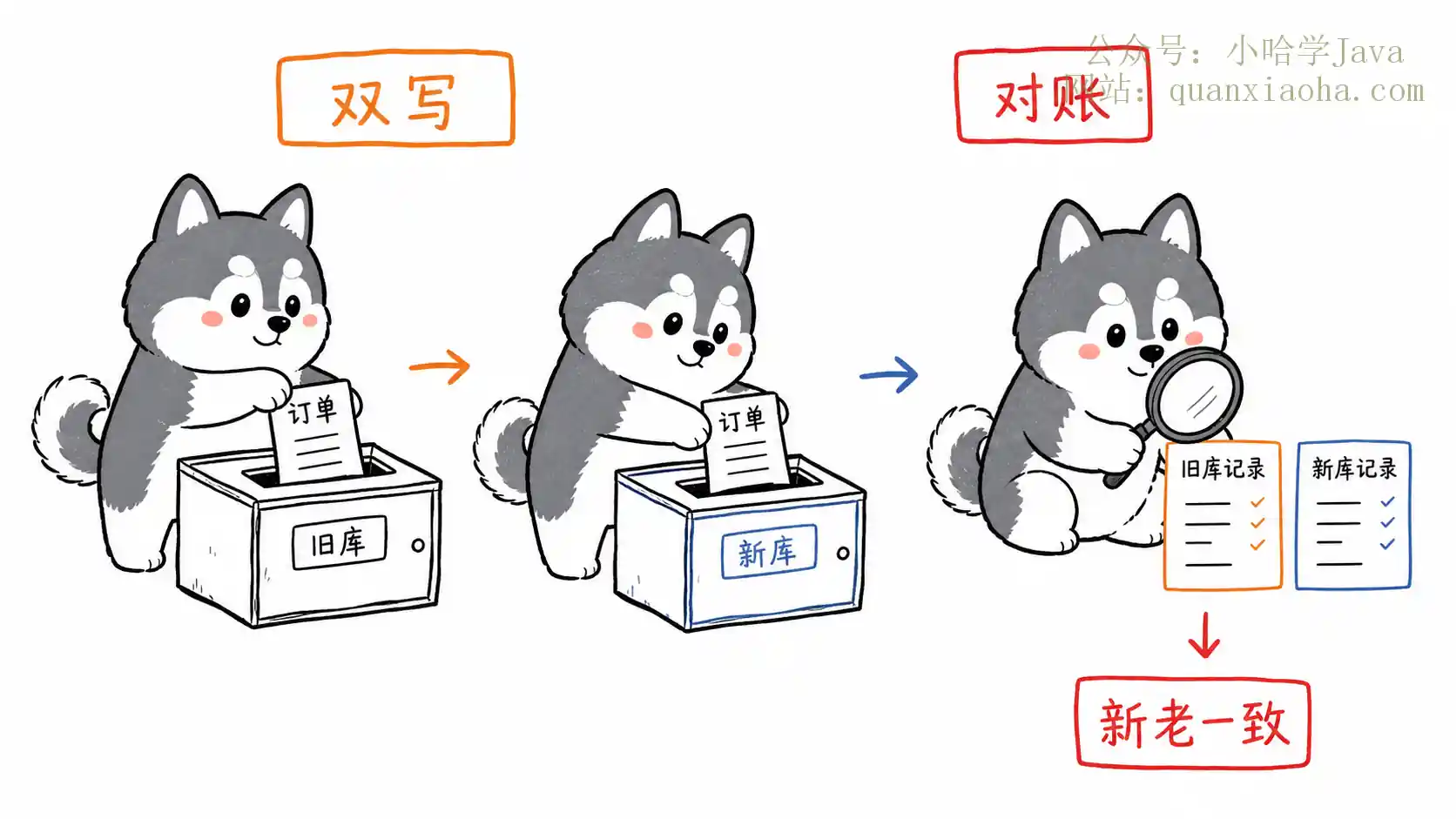
分库分表后如何平滑扩容与数据迁移?本文深度解析降低迁移难度的核心方案:设计阶段遵循一次分够、选择稳定分片键、应用虚拟槽或一致性哈希预留扩容余地;迁移阶段采用双写、对账与灰度切流,保障数据一致性,实现不停机平滑扩容,轻松应对大厂面试。
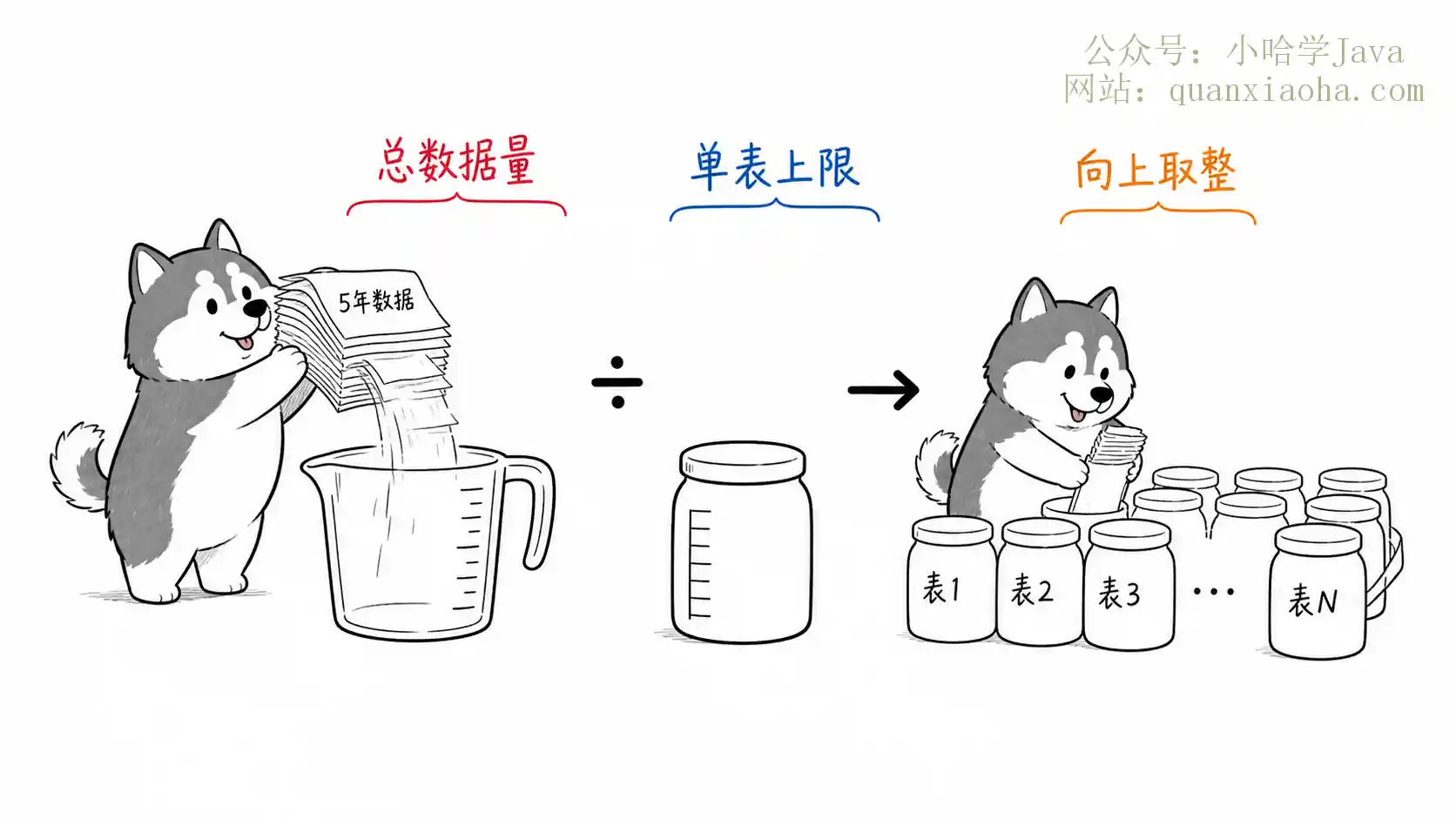
分库分表数量怎么预估?本文提供一套实用的容量规划公式:按未来3-5年数据量÷单表上限(1000万)估算分表数,按系统峰值并发÷单库TPS(1500)估算分库数,且结果需向上取2的幂以降低扩容成本。深入解析分片数计算逻辑与避坑指南,助你搞定面试与生产架构设计。

分库分表后怎么做跨库Join查询?本文深度解析绑定表、全局表、字段冗余、应用层组装与数据同步ES等6大主流解决方案。结合ShardingSphere实战与架构权衡,讲透跨库关联查询的代价与选型决策,助你轻松应对面试与真实业务场景!

本教程提供最新的 Pycharm 2026.2.0.1 破解版安装与激活图文指南。内含详细的 Windows 与 Mac 系统破解补丁安装步骤、激活码获取方法,亲测可成功将 Pycharm 激活至 2099 年。附赠常见问题解决办法,助你轻松完成 Pycharm 破解,快来获取专属激活码吧!
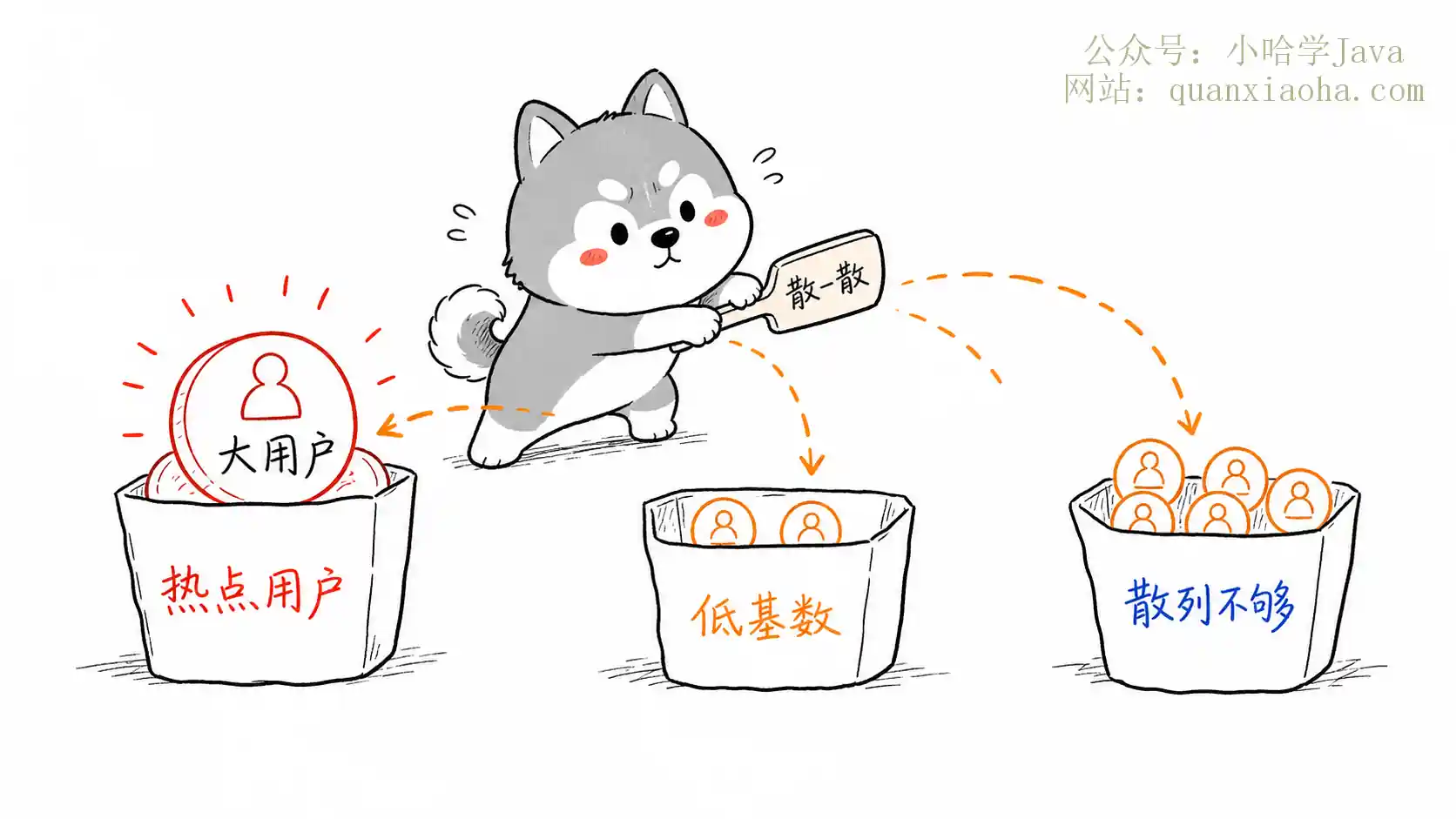
分库分表取模分片看似数学上均匀,但常因分片键分布不均、扩容方式不当或业务热点引发数据倾斜。本文深度解析倾斜来源,并从选对分片键、优化Hash算法(如MD5/MurmurHash)、2的幂翻倍扩容(或一致性哈希)、热点数据特殊治理等四个维度,提供避免数据倾斜的核心策略与实战经验,助你轻松应对面试与生产难题。
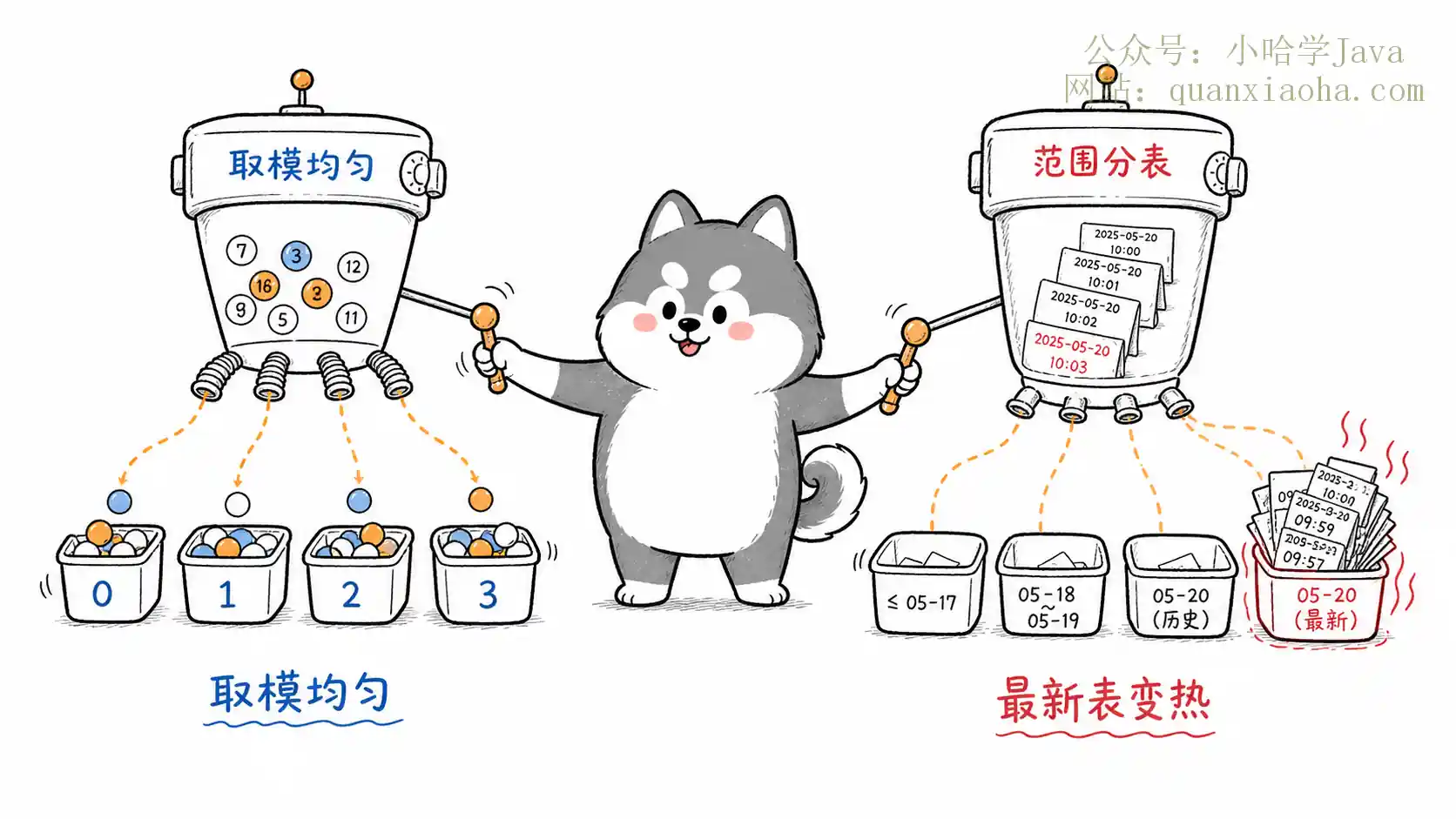
面试常考的分表算法有哪些?本文全面解析取模、范围、一致性哈希、路由表和基因法这五大主流分库分表算法。深度剖析各自的优缺点、扩容方案及适用场景,并提供ShardingSphere实战经验与选型决策指南,帮你轻松应对分表键选择与数据库扩容等高频面试追问!
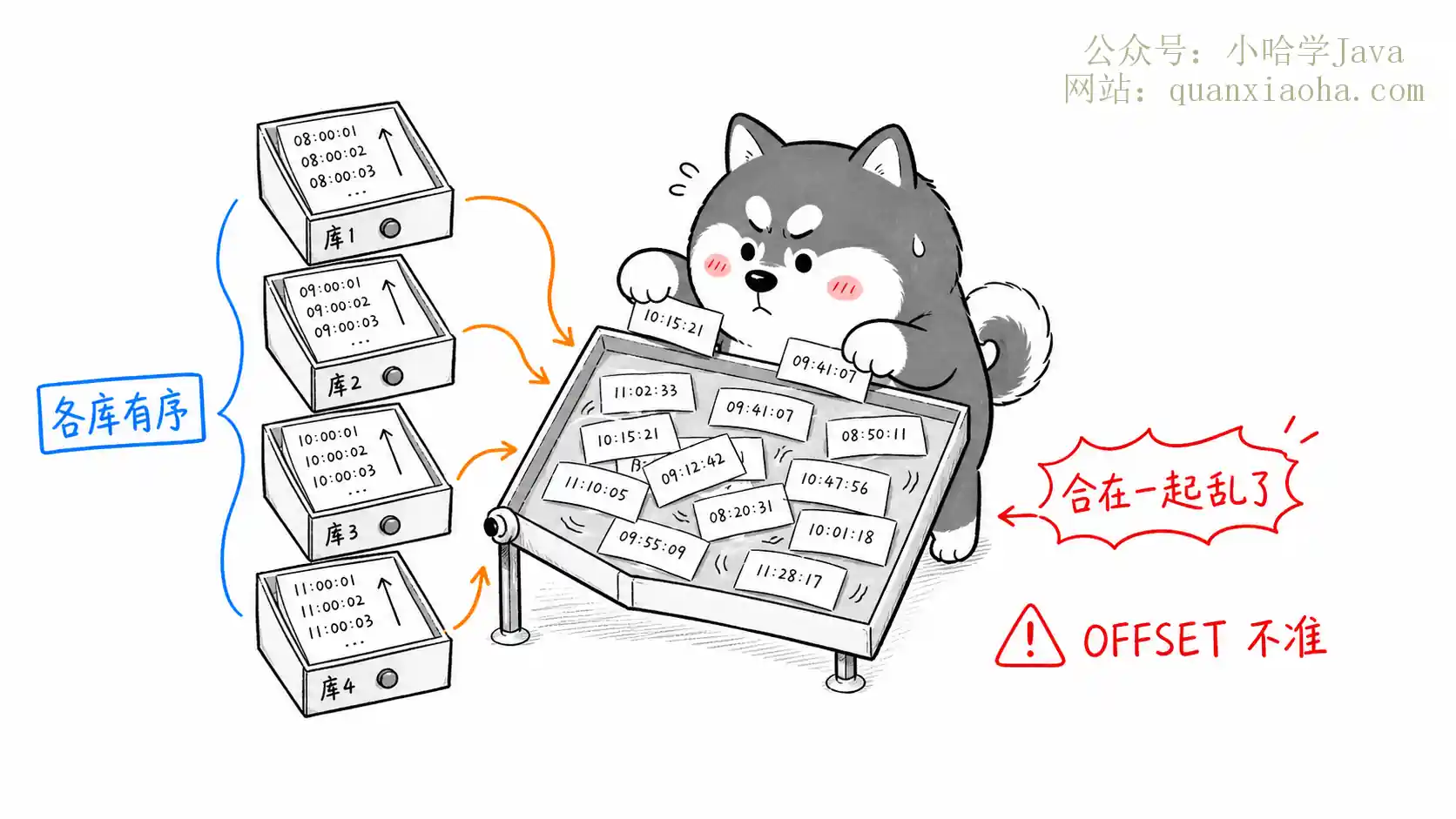
分库分表后如何进行分页查询?本文深入解析跨库深翻页难题,对比游标分页、全局内存合并、二次查询法与ES异构索引四大方案。助你掌握分布式系统架构思维与分页优化技巧,轻松应对面试与生产实战,告别分页查询性能瓶颈。
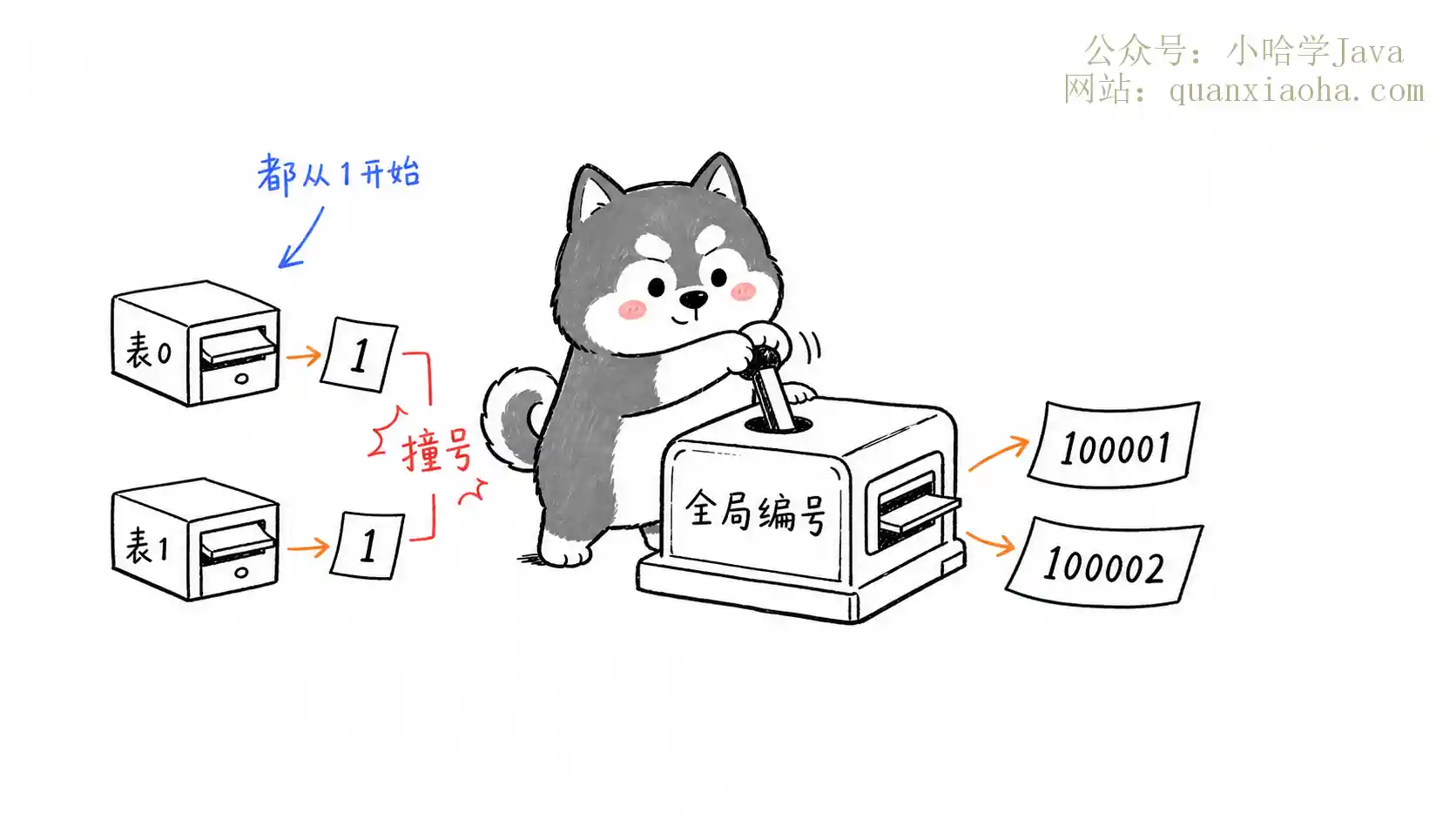
分表后单表自增主键会冲突,必须生成全局唯一ID。本文系统讲解UUID、数据库步长、号段模式、Redis及雪花算法等6大主流分布式ID方案,深度解析Snowflake时钟回拨与美团Leaf选型权衡,助你轻松拿下后端面试!