MyBatis 是如何进行分页的?分页插件的原理是什么?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
分页方式认知:面试官不仅仅是想知道你 "用过 PageHelper",更是想考察你是否理解逻辑分页和物理分页的区别,以及为什么生产环境必须用物理分页。
-
插件原理理解:看你能否说清楚 PageHelper 分页插件的底层原理——基于 MyBatis 的
Interceptor机制拦截 SQL,自动改写为分页 SQL。 -
生产实践意识:考察你是否知道分页插件的坑(如
count查询的性能问题、深度分页优化等)。
核心答案
MyBatis 的分页方式分为两种:逻辑分页(内存分页)和 物理分页(数据库分页)。
| 分页方式 | 原理 | 性能 | 生产推荐 |
|---|---|---|---|
| 逻辑分页(RowBounds) | 查出全部数据,内存中截取 | ⭐ 差 | ❌ 不推荐 |
| 物理分页(手写 SQL) | SQL 加 LIMIT 子句 |
⭐⭐⭐ 好 | ✅ 可用 |
| 物理分页(PageHelper) | 插件自动改写 SQL 加 LIMIT |
⭐⭐⭐ 好 | ✅ 推荐 |
| 物理分页(MyBatis-Plus) | 内置分页插件 | ⭐⭐⭐ 好 | ✅ 推荐 |
一句话结论:生产环境使用物理分页,最常用的方案是 PageHelper 或 MyBatis-Plus 分页插件,底层原理是利用 MyBatis 的 Interceptor 拦截 SQL 并自动拼接 LIMIT 语句。
深度解析
一、逻辑分页 vs 物理分页
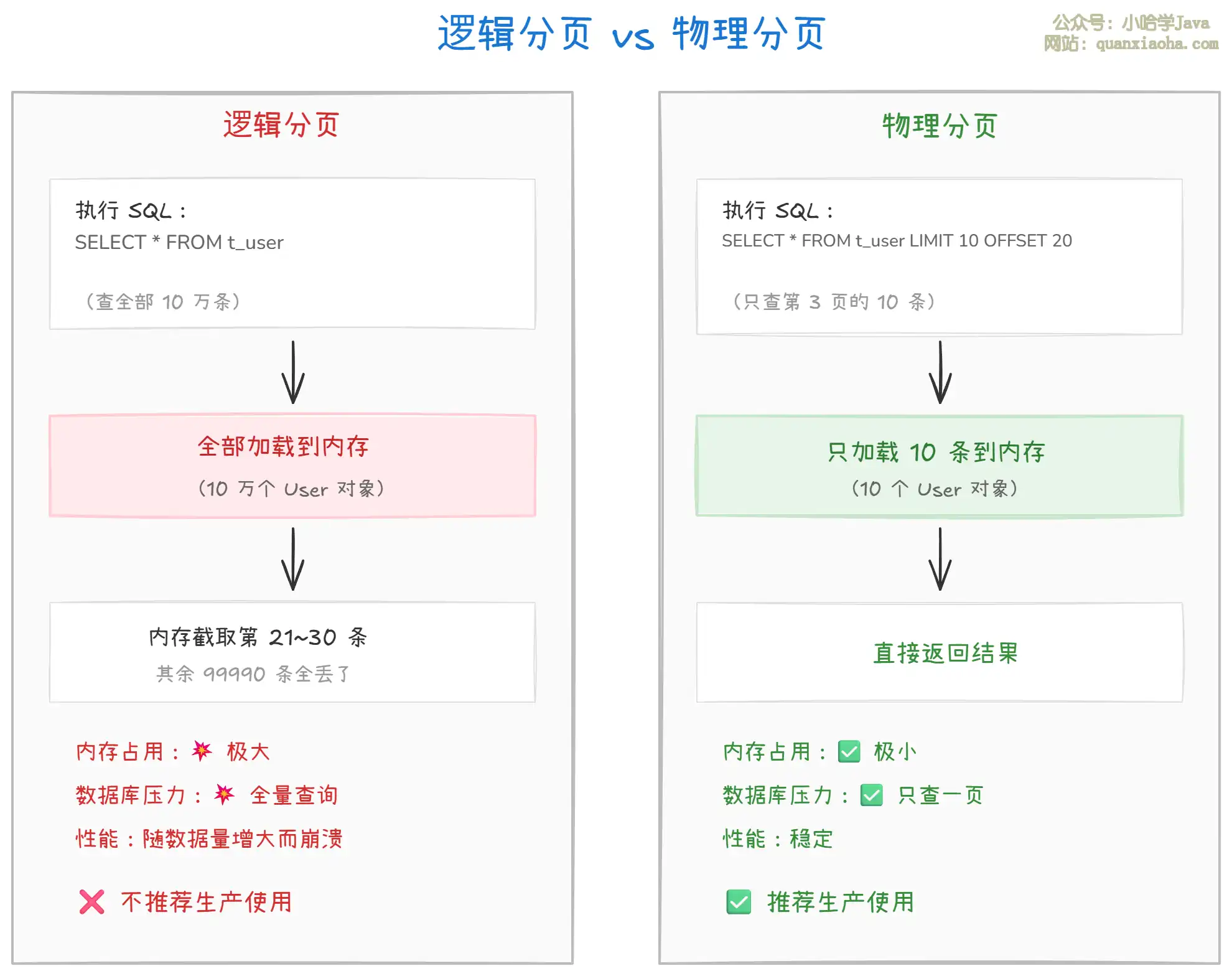
两种分页方式的核心差异在于 数据在哪里被截断:
- 逻辑分页:SQL 不加任何限制,查出全部数据加载到内存,再用
RowBounds在 Java 层截取指定范围的数据。数据量大时内存直接炸掉,绝对不能在生产环境使用。 - 物理分页:SQL 层面就通过
LIMIT/ROWNUM等子句限制返回的数据量,数据库只返回一页的数据。内存占用小,性能稳定。
二、逻辑分页——RowBounds(了解即可)
MyBatis 内置了 RowBounds 支持逻辑分页:
// offset:起始位置(从 0 开始),limit:每页条数
// 查第 3 页,每页 10 条 → offset = 20, limit = 10
List<User> users = sqlSession.selectList(
"com.example.mapper.UserMapper.selectAll",
null,
new RowBounds(20, 10) // 跳过前 20 条,取 10 条
);
底层原理:MyBatis 执行完整的 SQL 查询,将所有结果加载到内存后,通过 DefaultResultHandler 跳过 offset 条记录,只取 limit 条。
致命缺陷:100 万条数据只看 10 条,却要把 100 万条全加载到内存。生产环境绝对不能用。
三、物理分页——手写 SQL
最原始的方式,直接在 SQL 中手写 LIMIT:
<select id="selectByPage" resultType="User">
SELECT * FROM t_user
ORDER BY id DESC
LIMIT #{offset}, #{pageSize}
</select>
// 调用
int pageNum = 3; // 第 3 页
int pageSize = 10; // 每页 10 条
int offset = (pageNum - 1) * pageSize; // 偏移量 = 20
List<User> users = userMapper.selectByPage(offset, pageSize);
缺点:每次分页都要手算 offset,还要单独写 COUNT(*) 查询获取总数,代码重复且容易出错。
四、物理分页——PageHelper 插件(重点)
PageHelper 是国内最流行的 MyBatis 分页插件,使用非常简单:
// 使用 PageHelper 分页
PageHelper.startPage(3, 10); // 第 3 页,每页 10 条
List<User> users = userMapper.selectAll(); // 正常查询,自动分页
PageInfo<User> pageInfo = new PageInfo<>(users);
System.out.println("总记录数:" + pageInfo.getTotal()); // 100
System.out.println("总页数:" + pageInfo.getPages()); // 10
System.out.println("当前页数据:" + pageInfo.getList().size()); // 10
System.out.println("是否有下一页:" + pageInfo.isHasNextPage()); // true
核心 API:
| API | 说明 |
|---|---|
PageHelper.startPage(pageNum, pageSize) |
开启分页,仅对紧随其后的第一条查询生效 |
PageHelper.offsetPage(offset, limit) |
基于 offset 的分页 |
PageInfo |
分页信息封装类,包含总记录数、总页数、页码列表等 |
注意:PageHelper.startPage() 只对紧跟其后的第一条查询生效。这是通过 ThreadLocal 实现的——调用 startPage() 后将分页参数存入 ThreadLocal,下一次查询消费后自动清除。
五、PageHelper 的底层原理
PageHelper 的核心原理是 MyBatis 插件(Interceptor)机制 + SQL 改写:
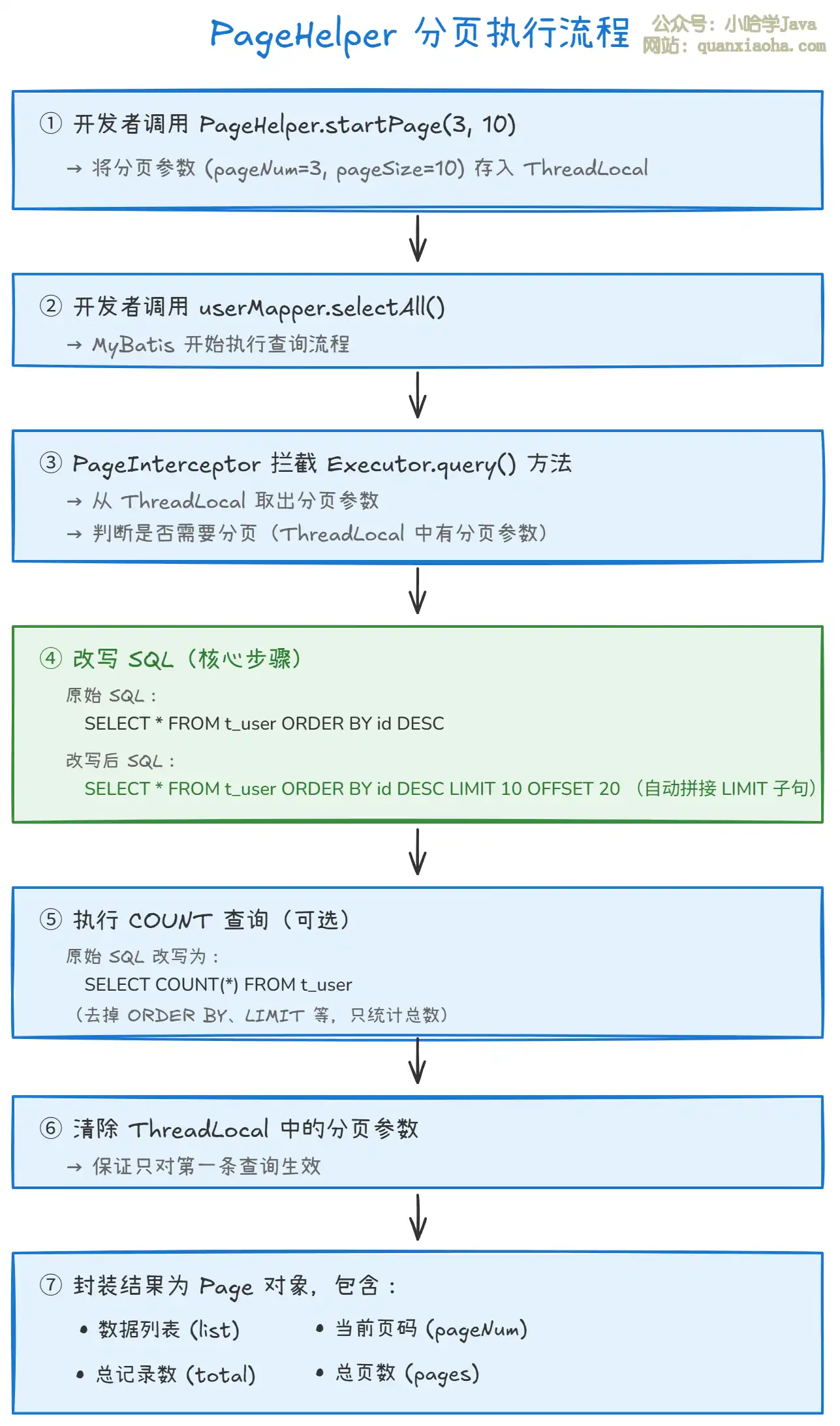
PageHelper 的完整执行流程可以拆解为以下关键步骤:
-
步骤一(设置分页参数):调用
PageHelper.startPage(3, 10),将分页参数封装为Page对象,存入当前线程的ThreadLocal。这一步和查询方法是分开调用的,通过ThreadLocal在两者之间传递分页信息。 -
步骤二(拦截查询):
PageInterceptor实现了 MyBatis 的Interceptor接口,通过@Signature注解拦截了Executor的query方法。当查询执行时,插件介入。 -
步骤三(SQL 改写):这是核心。插件从
ThreadLocal取出分页参数,使用 SQL 解析器(JSqlParser)解析原始 SQL 的 AST(抽象语法树),根据数据库方言自动拼接LIMIT(MySQL)、ROWNUM(Oracle)、TOP(SQL Server)等分页子句。 -
步骤四(COUNT 查询):如果需要总数(默认会查),插件会将原始 SQL 改写为
SELECT COUNT(*) FROM ...的形式,去掉ORDER BY、LIMIT、LEFT JOIN等不影响总数的部分,单独执行一次获取总记录数。 -
步骤五(清理 ThreadLocal):查询完成后,自动清除
ThreadLocal中的分页参数,确保不影响后续查询。
六、SQL 改写的实现细节
PageHelper 使用 JSqlParser 库解析和改写 SQL:
// 简化版 SQL 改写逻辑
public String addLimit(String originalSql, int offset, int limit) {
// 1. 用 JSqlParser 解析 SQL 为 AST
Statement stmt = CCJSqlParserUtil.parse(originalSql);
Select select = (Select) stmt;
// 2. 创建 LIMIT 子句
Limit limitObj = new Limit();
limitObj.setOffset(offset); // 跳过多少条
limitObj.setRowCount(limit); // 取多少条
// 3. 将 LIMIT 设置到 SELECT 语句中
select.getSelectBody().setLimit(limitObj);
// 4. 重新生成 SQL 字符串
return stmt.toString();
}
COUNT 查询的改写:
-- 原始 SQL
SELECT u.id, u.username, d.dept_name
FROM t_user u LEFT JOIN t_dept d ON u.dept_id = d.id
WHERE u.status = 1
ORDER BY u.created_time DESC
-- 改写后的 COUNT SQL
SELECT COUNT(0)
FROM t_user u
WHERE u.status = 1
-- 去掉了 SELECT 的列、LEFT JOIN(不影响行数)、ORDER BY
七、深度分页的性能问题
当 offset 非常大时(比如第 10 万页),LIMIT 的性能会急剧下降:
-- 第 10 万页,每页 10 条
SELECT * FROM t_user ORDER BY id DESC LIMIT 10 OFFSET 999990;
-- MySQL 实际上要先扫描 100 万条记录,再丢弃前 999990 条,只返回最后 10 条
优化方案:
| 方案 | 原理 | 适用场景 |
|---|---|---|
| 游标分页(推荐) | 用 WHERE id > lastMaxId LIMIT 10 替代 OFFSET |
App 无限滚动、瀑布流 |
| 子查询优化 | WHERE id >= (SELECT id FROM t_user ORDER BY id LIMIT 999990, 1) |
传统分页 |
| 延迟关联 | INNER JOIN (SELECT id FROM t_user LIMIT 999990, 10) t |
传统分页 |
八、常见误区
- 误区一:"
PageHelper.startPage()对所有查询都生效"- 不是。它只对紧跟其后的第一条查询生效,查询完成后
ThreadLocal中的分页参数自动清除。这是为了防止分页参数 "污染" 后续的非分页查询。
- 不是。它只对紧跟其后的第一条查询生效,查询完成后
- 误区二:"
PageHelper会自动识别所有查询需要分页"- 不是。必须在查询前显式调用
PageHelper.startPage()。如果没调用,就是普通查询,不会分页。
- 不是。必须在查询前显式调用
- 误区三:"分页插件的
count查询没有性能问题"- 有。
count查询在大表上可能很慢,尤其是有复杂JOIN和WHERE条件时。PageHelper 支持配置countColumn来优化(比如用COUNT(0)替代COUNT(*)),或者手动指定count查询的 SQL。
- 有。
面试高频追问
- 追问一:PageHelper 是怎么保证只对第一条查询生效的?
- 通过
ThreadLocal实现。startPage()将分页参数存入ThreadLocal,查询执行时PageInterceptor消费分页参数后立即从ThreadLocal中移除,后续查询就不会再被分页了。
- 通过
- 追问二:MyBatis-Plus 的分页插件和 PageHelper 有什么区别?
- 原理相同,都是基于 MyBatis 的
Interceptor拦截 SQL 并改写。区别在于:MyBatis-Plus 的分页插件需要传入IPage参数(编译时就能确定分页),而 PageHelper 通过ThreadLocal(运行时绑定)。MyBatis-Plus 的方式更明确,不容易出错。
- 原理相同,都是基于 MyBatis 的
- 追问三:深度分页怎么优化?
- 最推荐的方案是 "游标分页":用
WHERE id > lastMaxId ORDER BY id LIMIT 10替代LIMIT OFFSET,避免扫描和丢弃大量数据。对于必须用传统分页的场景,可以用 "延迟关联" 优化:先通过子查询在索引上定位id,再回表取数据。
- 最推荐的方案是 "游标分页":用
常见面试变体
- 变体一:"MyBatis 的逻辑分页和物理分页有什么区别?"
- 变体二:"说说 PageHelper 分页插件的实现原理?"
- 变体三:"深度分页性能差怎么优化?"
记忆口诀
逻辑分页查全量,物理分页加 LIMIT;PageHelper 拦 Executor,ThreadLocal 传参数,JSqlParser 改写 SQL;深度分页用游标,offset 大了性能崩。
总结
MyBatis 分页分为逻辑分页(RowBounds,内存截取,不能用)和物理分页(LIMIT,数据库层面分页)。生产环境使用 PageHelper 或 MyBatis-Plus 分页插件,底层原理是利用 MyBatis 的 Interceptor 拦截 Executor.query(),通过 JSqlParser 改写 SQL 自动拼接 LIMIT 子句,并通过 ThreadLocal 保证分页参数只对第一条查询生效。