RocketMQ 的架构是怎么样的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
全局架构认知:面试官不仅仅是想知道 RocketMQ 有几个组件,更是想知道你是否理解各组件的职责边界和协作关系,能否从宏观角度把握整个消息系统的设计。
-
设计思想理解:考察你是否理解 RocketMQ 为什么这么设计——比如为什么用
NameServer而不是 ZooKeeper、为什么 Broker 要分 Master/Slave、Topic 和 Queue 的关系是什么。懂 "为什么" 比 "是什么" 更重要。 -
高可用感知:架构设计的核心目标之一是高可用,面试官想看你是否知道 RocketMQ 是如何通过架构保证高可用的(主从切换、消息重试、故障隔离等)。
核心答案
RocketMQ 的整体架构由 四大核心组件 构成,采用去中心化的设计理念:
| 组件 | 角色 | 类比 | 核心职责 |
|---|---|---|---|
| NameServer | 路由注册与发现 | 注册中心 | 管理 Broker 路由信息,无状态,互相独立 |
| Broker | 消息存储与转发 | 消息服务器 | 接收、存储、投递消息,分 Master/Slave |
| Producer | 消息发送者 | 寄件人 | 发送消息,支持多种发送方式 |
| Consumer | 消息消费者 | 收件人 | 拉取/推送消息,支持集群/广播消费 |
一句话总结:Producer 和 Consumer 通过 NameServer 发现 Broker 地址,Broker 负责消息的存储和转发,NameServer 各节点独立、无状态,整体架构去中心化、高可用。
深度解析
一、整体架构全景图
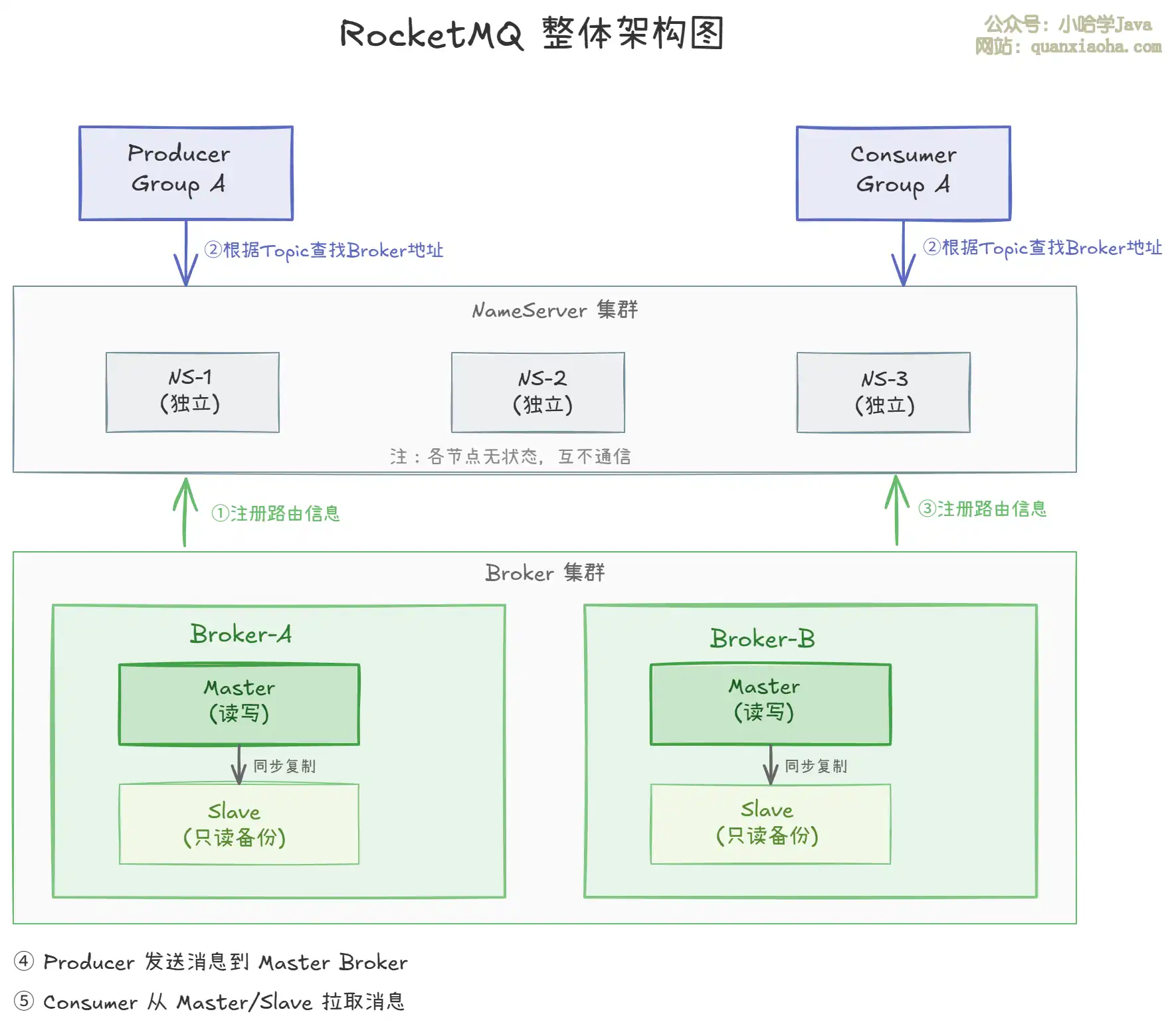
上图展示了 RocketMQ 的完整架构,整体分为以下几层:
- 接入层:
Producer负责发送消息,Consumer负责消费消息,它们都是客户端。 - 路由层:
NameServer集群充当路由注册中心,每个节点独立运行,互不通信,无状态设计。 - 存储层:
Broker集群负责消息的存储和转发,每个Broker分Master(主)和Slave(从),通过同步/异步复制保证数据可靠性。
消息流转路径:Producer → NameServer(获取路由)→ Master Broker(存储消息)→ Consumer(拉取消费)。
二、四大组件深度剖析
1. NameServer——轻量级注册中心
// NameServer 核心数据结构(源码简化)
public class RouteInfoManager {
// Topic → QueueData 的映射(一个 Topic 分布在哪些 Broker 上)
HashMap<String/* topic */, Map<String /* brokerName */, QueueData>> topicQueueTable;
// Broker 地址信息
HashMap<String/* brokerName */, BrokerData> brokerAddrTable;
// Broker 存活信息(心跳检测)
HashMap<String/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
}
NameServer 的核心特点:
- 无状态:各 NameServer 节点之间互不通信,不需要选举,不存在集群一致性问题
- 轻量级:不需要 ZooKeeper 那样的 Paxos/Raft 共识算法,启动快、资源占用少
- 心跳机制:Broker 每 30 秒向所有 NameServer 发送心跳,NameServer 超过 120 秒未收到心跳则剔除该 Broker
- AP 模型:追求可用性(Availability)而非强一致性,Broker 可能短暂向不同 NameServer 注册了不同状态
为什么不用 ZooKeeper?
| 对比维度 | NameServer | ZooKeeper |
|---|---|---|
| 设计理念 | 极简,只做路由 | 通用协调服务 |
| 一致性协议 | 无(各自独立) | ZAB 协议 |
| 性能 | 极高 | 受限于 Leader 选举 |
| 运维复杂度 | 低 | 高(需要集群选举) |
| 适用场景 | 消息路由发现 | 分布式锁、配置管理 |
核心原因:RocketMQ 的路由信息天然具有最终一致性的特点——Producer 发消息时即使拿到略微过期的路由,大不了发一次失败,重试即可。不需要 ZooKeeper 那样的强一致性保证,所以选择了更轻量的自研 NameServer。
2. Broker——消息存储服务器
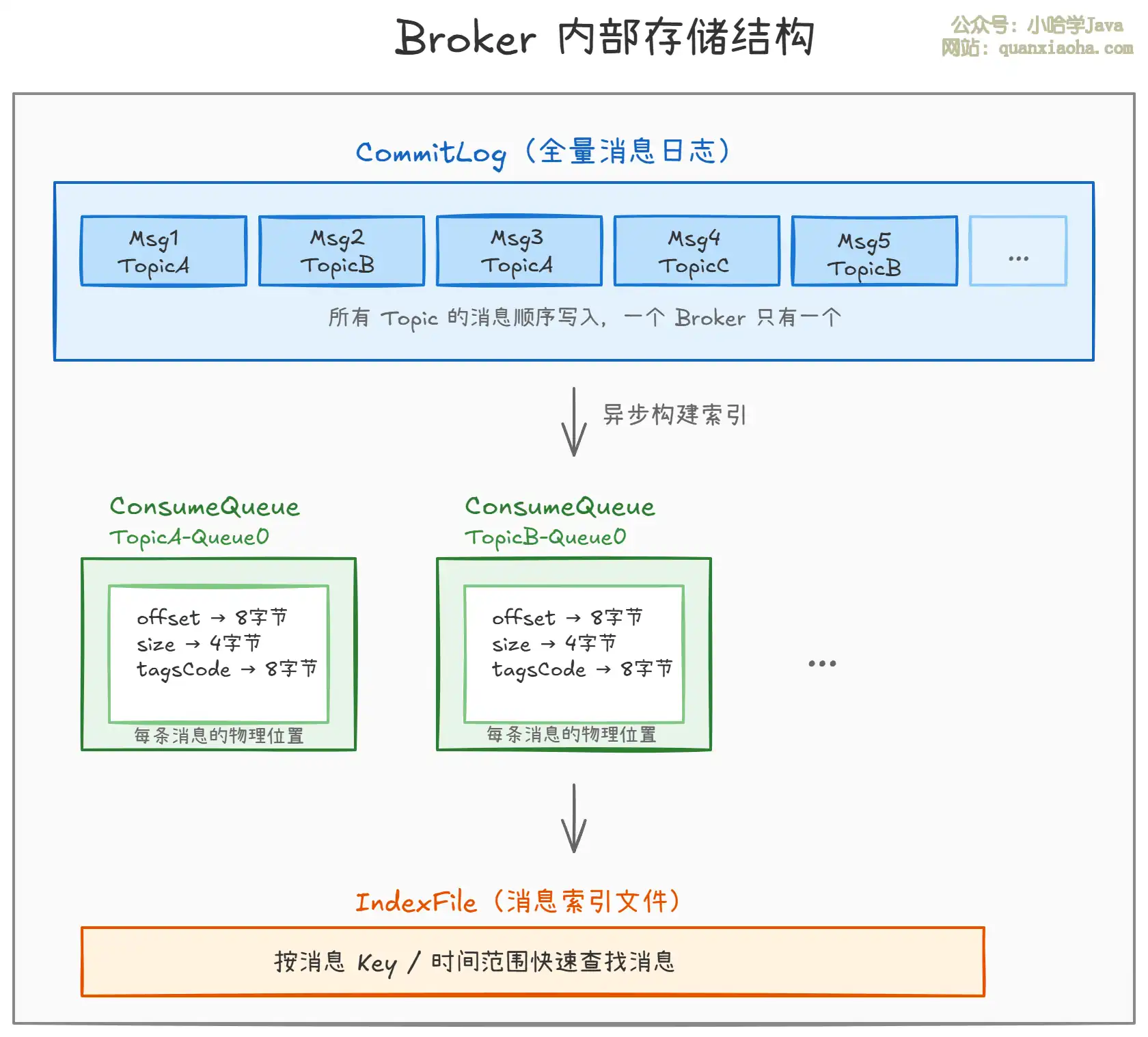
上图展示了 Broker 内部的核心存储结构,关键设计如下:
- CommitLog:所有 Topic 的消息混合顺序写入同一个物理文件。这是 RocketMQ 高吞吐的关键——顺序写磁盘的性能接近内存写,随机写磁盘则慢几个数量级。一个 Broker 实例只有一个
CommitLog。 - ConsumeQueue:消息的逻辑队列,相当于
CommitLog的索引。每条记录固定 20 字节(8 字节 offset + 4 字节 size + 8 字节 tag hash),指向CommitLog中真实消息的物理位置。Consumer 先读ConsumeQueue定位消息,再去CommitLog取消息体。 - IndexFile:可选的消息索引文件,支持按消息 Key 和时间范围快速查询。
为什么 CommitLog 要混合存储?
顺序写是磁盘 I/O 的最高性能模式。如果把每个 Topic 单独一个文件,就会有多个文件的随机写,性能急剧下降。混合写入后,所有消息追加到同一个文件,磁盘顺序写 TPS 可达 10 万+。
Master 与 Slave 的关系:
| 维度 | Master | Slave |
|---|---|---|
| 角色 | 主节点,负责读写 | 从节点,只读备份 |
| 编号 | brokerId = 0 | brokerId > 0 |
| 数据来源 | 接收 Producer 消息 | 从 Master 同步复制 |
| 消费 | Consumer 可从 Master 拉取 | Consumer 可从 Slave 拉取(Master 压力大时分担读负载) |
| 故障处理 | 宕机后 Slave 可接管(Dledger 模式自动选举) | — |
3. Producer——消息发送者
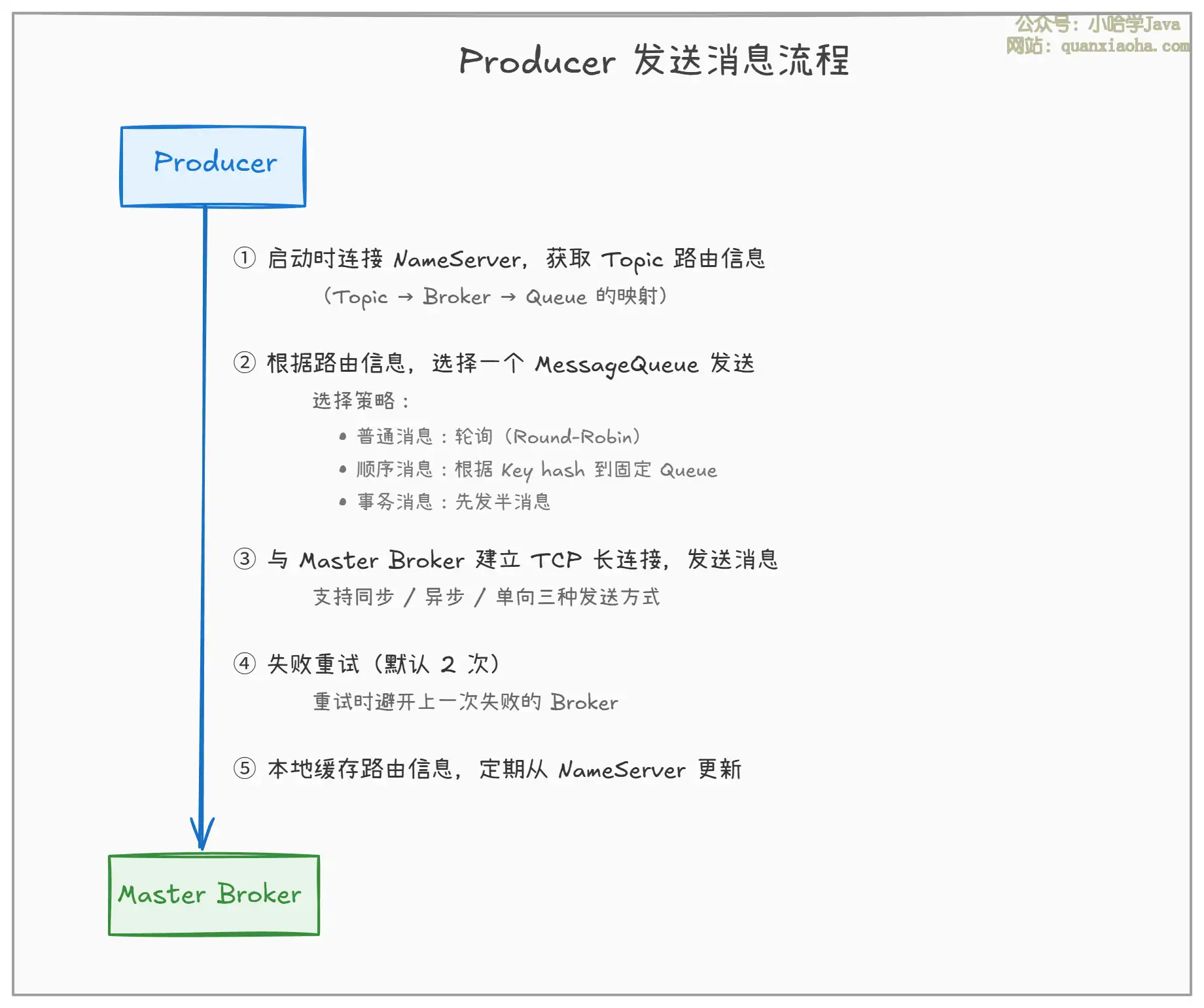
上图展示了 Producer 发送消息的完整流程:
- 步骤一(路由获取):Producer 启动时连接
NameServer,获取指定Topic的路由信息(即该Topic分布在哪些Broker的哪些Queue上)。 - 步骤二(Queue 选择):根据发送策略选择目标
MessageQueue。普通消息轮询分发到不同Queue,保证负载均衡;顺序消息根据Keyhash 到固定Queue。 - 步骤三(发送消息):与
Master Broker建立 TCP 长连接(Netty),发送消息。 - 步骤四(失败重试):发送失败默认重试 2 次,且重试时会避开上次失败的
Broker,提高成功率。 - 步骤五(路由更新):Producer 本地缓存路由信息,定期从
NameServer更新,感知Broker上下线变化。
4. Consumer——消息消费者
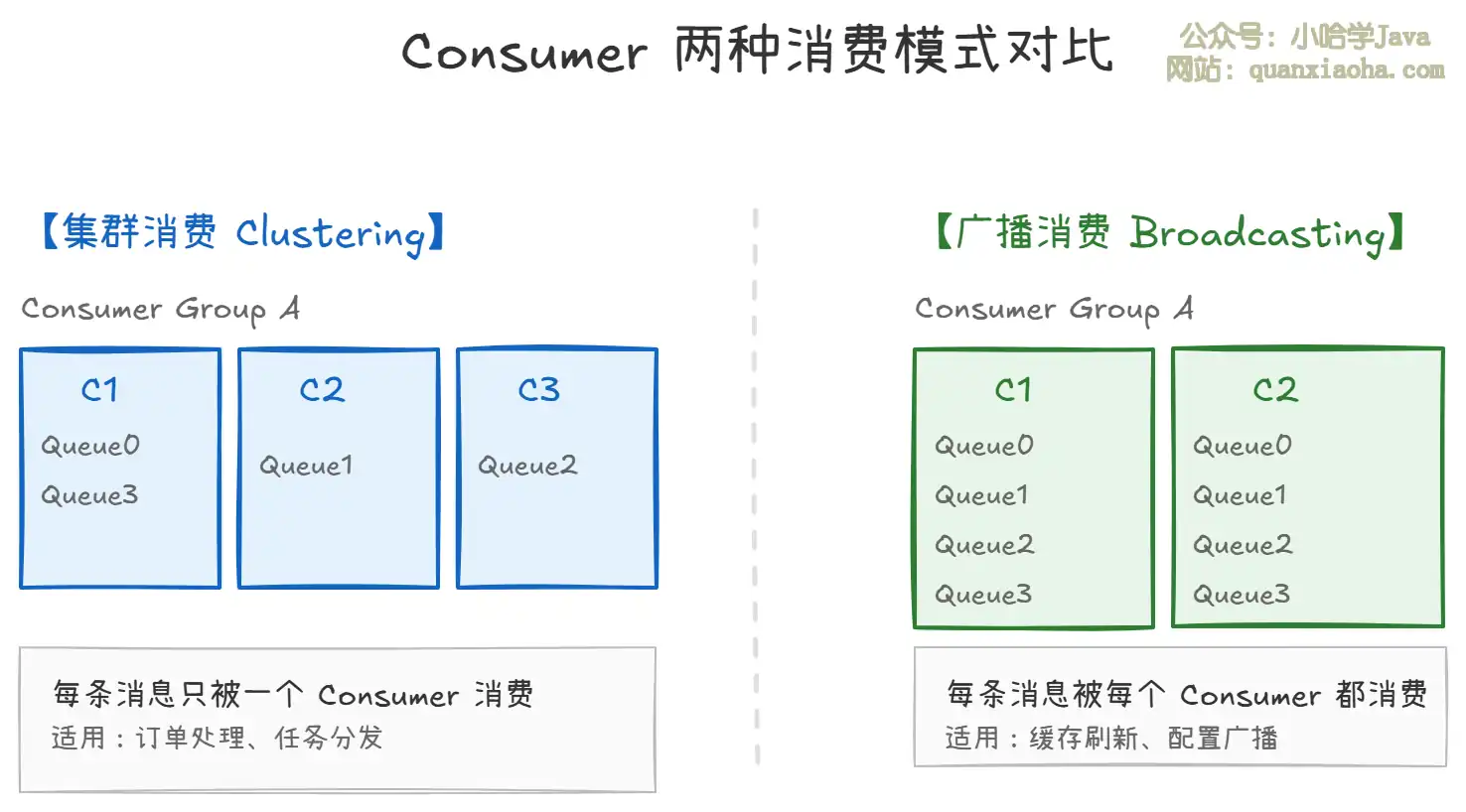
上图展示了 Consumer 的两种消费模式:
- 集群消费(Clustering):同一个 Consumer Group 下的多个 Consumer 分摊消费 Queue,每条消息只会被 Group 中的一个 Consumer 消费。这是默认模式,适用于大部分业务场景(如订单处理)。Consumer 数量不要超过 Queue 数量,否则多余的 Consumer 会空闲。
- 广播消费(Broadcasting):每条消息会被 Group 中的所有 Consumer 都消费一遍。适用于缓存刷新、配置广播等需要 "全量通知" 的场景。
三、一条消息的完整生命周期
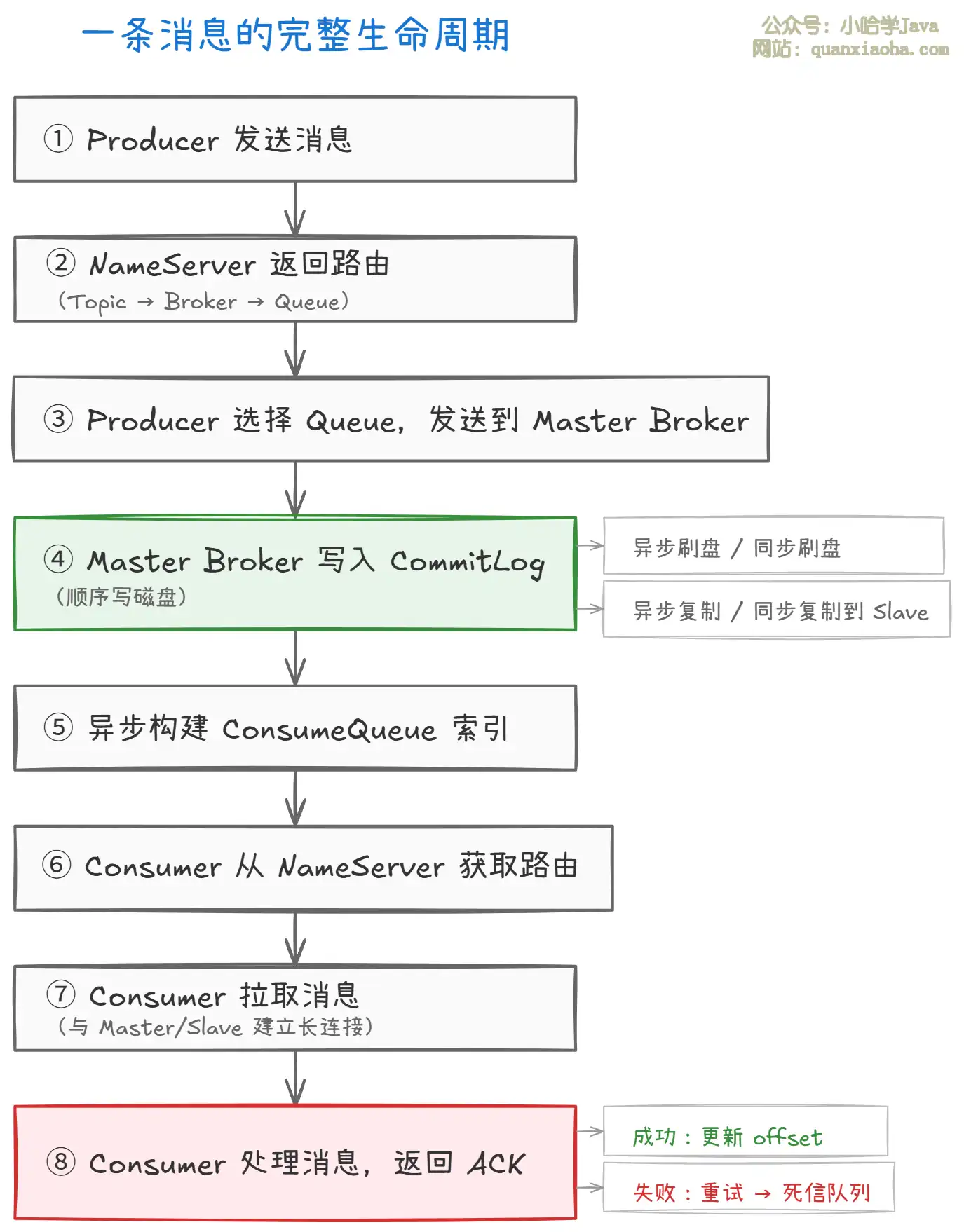
上图展示了一条消息从发送到消费的完整生命周期,共 8 个阶段:
- 阶段一(①②③):Producer 查询 NameServer 获取路由,选择目标 Queue,将消息发送到 Master Broker。
- 阶段二(④⑤):Broker 将消息顺序写入
CommitLog,根据刷盘策略(同步/异步)持久化,并根据复制策略(同步/异步)同步到 Slave。同时异步构建ConsumeQueue索引。 - 阶段三(⑥⑦⑧):Consumer 从 NameServer 获取路由后,与 Broker 建立长连接拉取消息。处理成功则更新消费进度;失败则进入重试机制,最多重试 16 次,仍未成功则进入死信队列(DLQ)。
四、Topic 与 MessageQueue 的关系
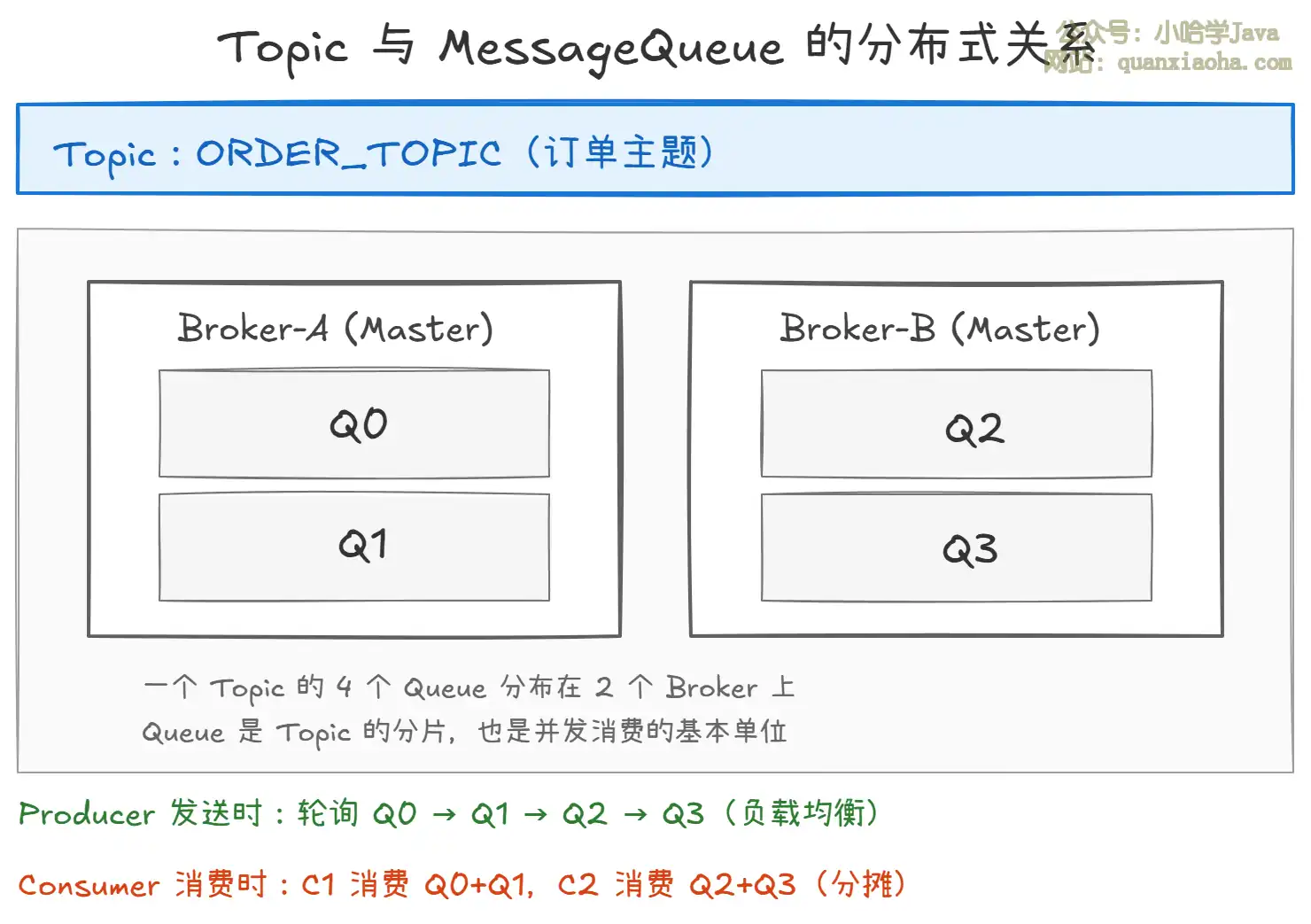
上图展示了 Topic 与 MessageQueue 的关系:
- Topic 是逻辑上的消息主题,比如 "订单 Topic"。
- MessageQueue(Queue) 是 Topic 的物理分片,是消息存储和并发消费的最小单位。
- 一个 Topic 可以有多个 Queue,分布在不同 Broker 上,实现分布式存储和并行消费。
- Queue 数量决定了最大并发消费能力——Consumer 数量超过 Queue 数量后,多余的 Consumer 将无法分配到 Queue,处于空闲状态。
面试高频追问
-
追问一:NameServer 挂了一台怎么办?
- 不影响。各 NameServer 节点独立运行,Producer/Consumer/Broker 同时连接所有 NameServer。挂掉一台后,客户端自动切换到其他存活的 NameServer 节点。
-
追问二:Broker 的 Master 挂了怎么办?
- Slave 可以继续提供消息消费(只读),但不能接收新消息。配合 Dledger 组件或 Controller 模式(5.0),可以实现 Slave 自动晋升为 Master,完成故障自动切换。
-
追问三:为什么 RocketMQ 用 NameServer 而不是 ZooKeeper?
- 路由信息天然适合最终一致性,不需要 ZK 的强一致性;NameServer 无状态、无选举,性能更高、运维更简单;阿里实践表明 ZK 在大规模 Topic 场景下性能瓶颈明显。
-
追问四:CommitLog 和 ConsumeQueue 是什么关系?
CommitLog存储所有消息的完整内容(物理存储),一个 Broker 只有一个;ConsumeQueue是CommitLog的逻辑索引,按 Topic + QueueId 组织,Consumer 通过它快速定位消息。
常见面试变体
- 变体一:"介绍一下 RocketMQ 的整体架构设计"
- 变体二:"RocketMQ 有哪些核心组件?各自的作用是什么?"
- 变体三:"RocketMQ 的 NameServer 和 ZooKeeper 有什么区别?"
- 变体四:"RocketMQ 的 Broker 是怎么存储消息的?"
记忆口诀
四大组件:Name(路由)、Broker(存储)、Producer(发)、Consumer(收)。
存储模型:CommitLog(一锅炖)→ ConsumeQueue(分盘索引)→ IndexFile(按 Key 查)。
设计哲学:顺序写提升吞吐,混合存减少随机 I/O,去中心化提升可用性。
总结
RocketMQ 架构由 NameServer(路由)、Broker(存储)、Producer(发送)、Consumer(消费) 四大组件构成。核心设计亮点有三:一是采用轻量级 NameServer 替代 ZooKeeper,去中心化、无状态、高可用;二是 Broker 内部通过 CommitLog 顺序写 + ConsumeQueue 异步索引实现高吞吐存储;三是 Master/Slave 主从复制保证消息可靠性。面试时建议从四大组件入手,再展开存储模型和高可用机制,展现对架构设计的深度理解。