为什么项目要选择 RocketMQ?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
技术选型能力:面试官不仅仅是想知道 RocketMQ 有什么优点,更是想知道你是否具备多维度对比分析的能力,能否根据业务场景特点给出合理的技术选型依据。
-
消息中间件全局认知:考察你是否了解主流消息队列(RocketMQ、Kafka、RabbitMQ)的定位差异,是否只是 "用过" 还是真正理解各自的设计哲学和适用边界。
-
实践与原理结合:能否结合项目实际需求(如事务消息、顺序消息、高可用等),讲清楚 "为什么 RocketMQ 是最佳选择" 而非泛泛而谈。
核心答案
选择 RocketMQ 的核心原因可以概括为 "三高一丰":
| 维度 | 核心优势 | 对比其他 MQ |
|---|---|---|
| 高吞吐 | 单机 TPS 可达 10 万+ | 优于 RabbitMQ,与 Kafka 接近 |
| 高可靠 | 同步双写 + 同步刷盘,消息零丢失 | 优于 Kafka(异步刷盘可能丢消息) |
| 高一致 | 原生事务消息支持 | Kafka 和 RabbitMQ 均不原生支持 |
| 功能丰富 | 延迟消息、顺序消息、消息回溯、过滤 | 功能维度全面领先 |
一句话总结:如果你的项目是 Java 技术栈、对消息可靠性要求高、需要事务消息或延迟消息等高级特性,RocketMQ 是最优选择。
深度解析
一、主流消息队列横向对比
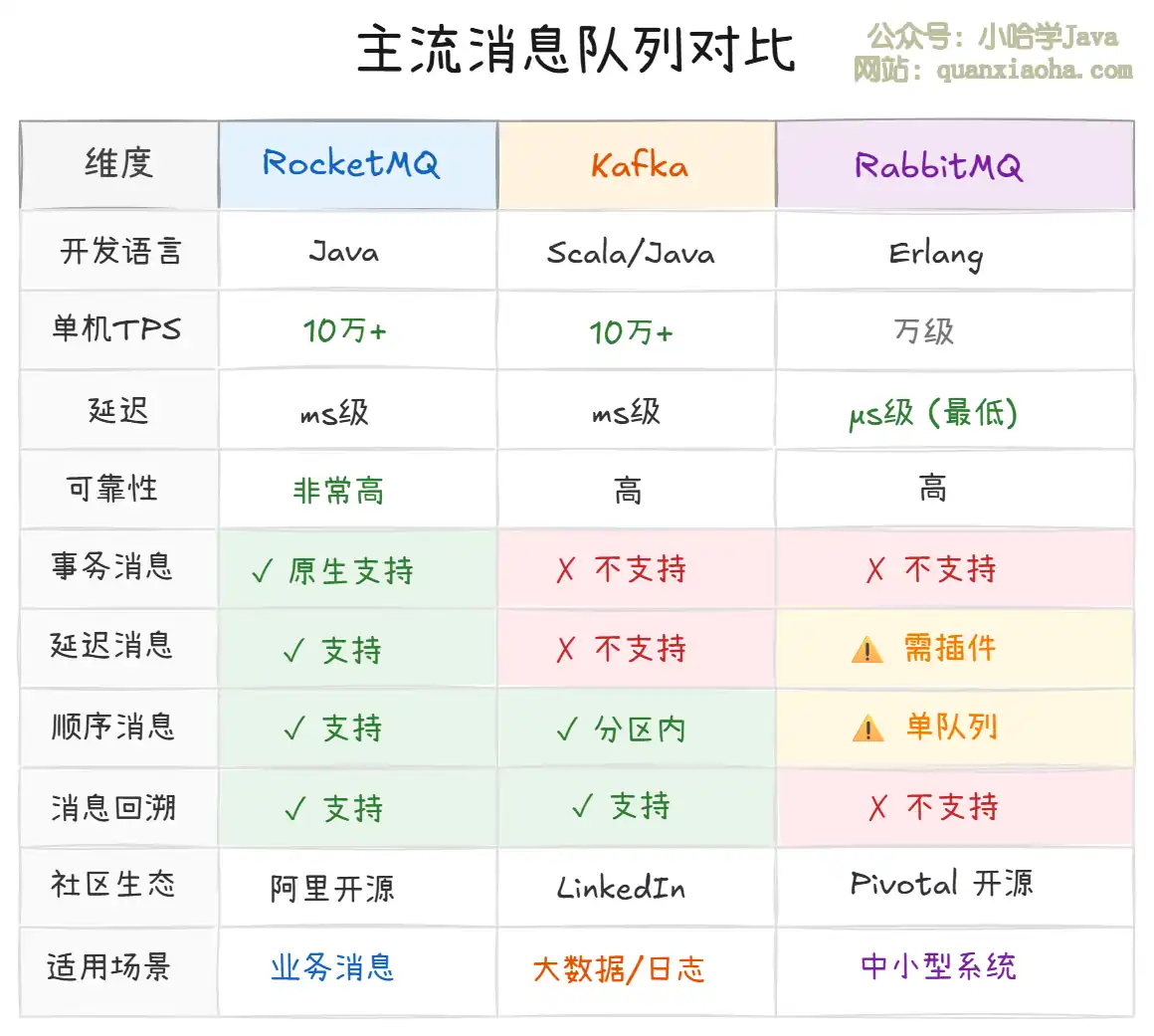
上表展示了三大主流消息队列的核心差异。从对比中可以看出:
- RocketMQ vs Kafka:Kafka 定位是大数据领域的消息流平台,追求极致吞吐,但在业务消息场景(如订单、支付)下的可靠性、功能丰富度不如 RocketMQ。RocketMQ 天生为业务消息而生。
- RocketMQ vs RabbitMQ:RabbitMQ 延迟最低(us 级),但单机吞吐量上限低(万级),且 Erlang 语言栈对 Java 团队不友好,排查问题困难。RocketMQ 吞吐量高出一个数量级,且全 Java 技术栈便于深入定制。
二、选择 RocketMQ 的六大核心理由
理由 1:原生事务消息——分布式事务的优雅方案
这是 RocketMQ 最核心的杀手级特性。以电商下单场景为例:
// ============ 生产者:发送事务消息 ============
TransactionMQProducer producer = new TransactionMQProducer("tx_producer_group");
// 设置事务监听器,用于执行本地事务和回查
producer.setTransactionListener(new TransactionListener() {
// 执行本地事务(比如:扣减库存、创建订单)
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
try {
// 执行本地业务逻辑
orderService.createOrder(parseOrder(msg));
return LocalTransactionState.COMMIT_MESSAGE;
} catch (Exception e) {
return LocalTransactionState.ROLLBACK_MESSAGE;
}
}
// 回查本地事务状态(broker 长时间未收到确认时触发)
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
Order order = orderService.getByOrderId(parseOrderId(msg));
// 订单存在说明本地事务已提交 → 提交消息
return order != null ? LocalTransactionState.COMMIT_MESSAGE
: LocalTransactionState.ROLLBACK_MESSAGE;
}
});
Message msg = new Message("ORDER_TOPIC", orderJson.getBytes());
// 发送事务消息(半消息)
producer.sendMessageInTransaction(msg, null);
工作原理:
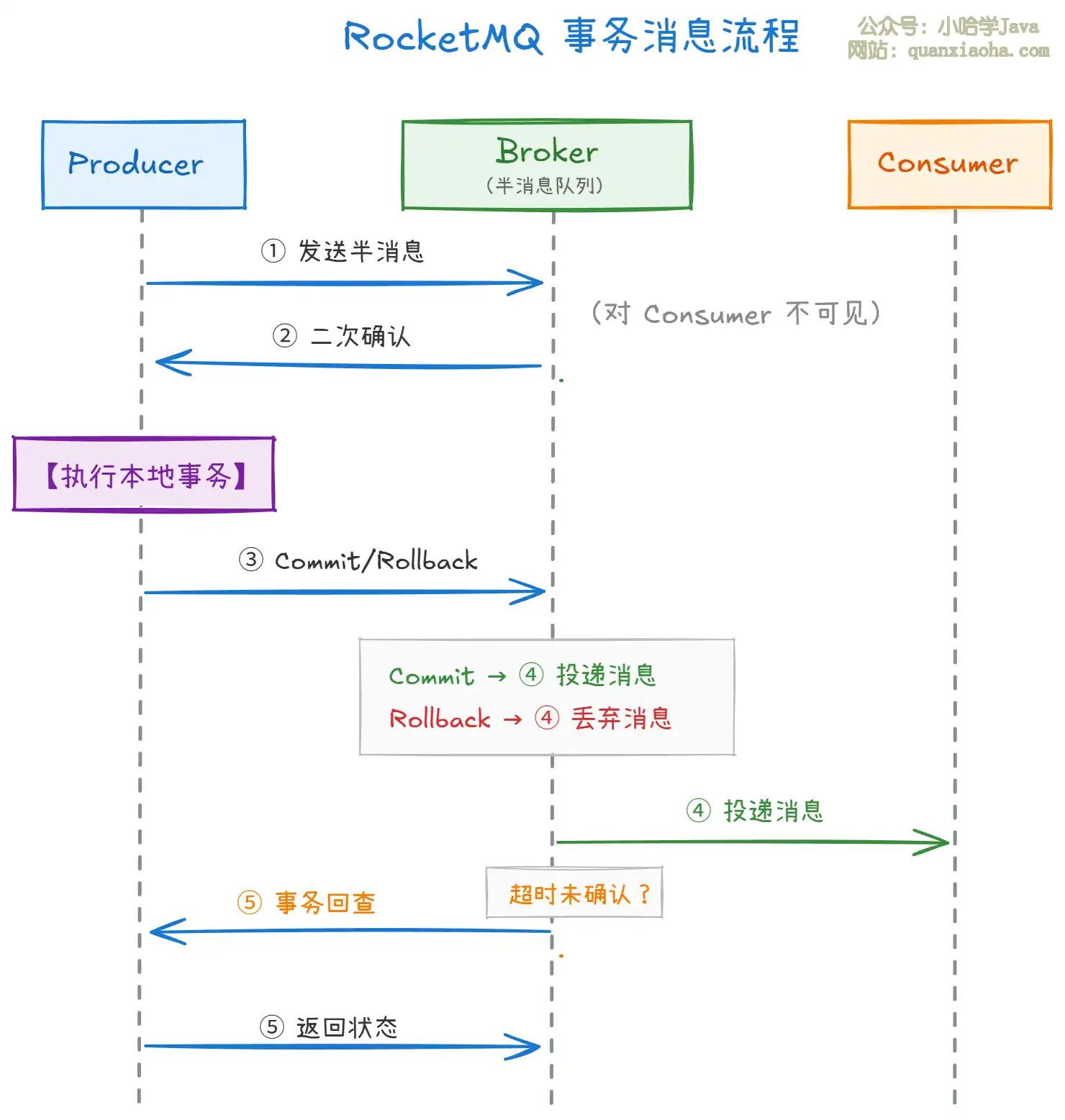
上图展示了 RocketMQ 事务消息的完整流程,核心分为以下几个阶段:
- 阶段一(①②):Producer 发送 "半消息" 到 Broker,半消息对 Consumer 不可见。Broker 收到后返回确认,此时消息处于 "待定" 状态。
- 阶段二(本地事务):Producer 收到确认后执行本地事务(如创建订单、扣减库存),根据本地事务结果决定消息的最终状态。
- 阶段三(③④):Producer 根据本地事务结果发送 Commit 或 Rollback。Commit 后 Broker 才将消息投递给 Consumer;Rollback 则直接丢弃。
- 阶段四(⑤回查):如果 Broker 长时间未收到二次确认(比如 Producer 宕机),会主动回查 Producer 的事务状态,确保消息最终一致性。
关键点在于,半消息机制 + 事务回查保证了分布式场景下的最终一致性,无需引入额外的分布式事务框架(如 Seata),极大降低了系统复杂度。
理由 2:高可靠性——金融级消息不丢失
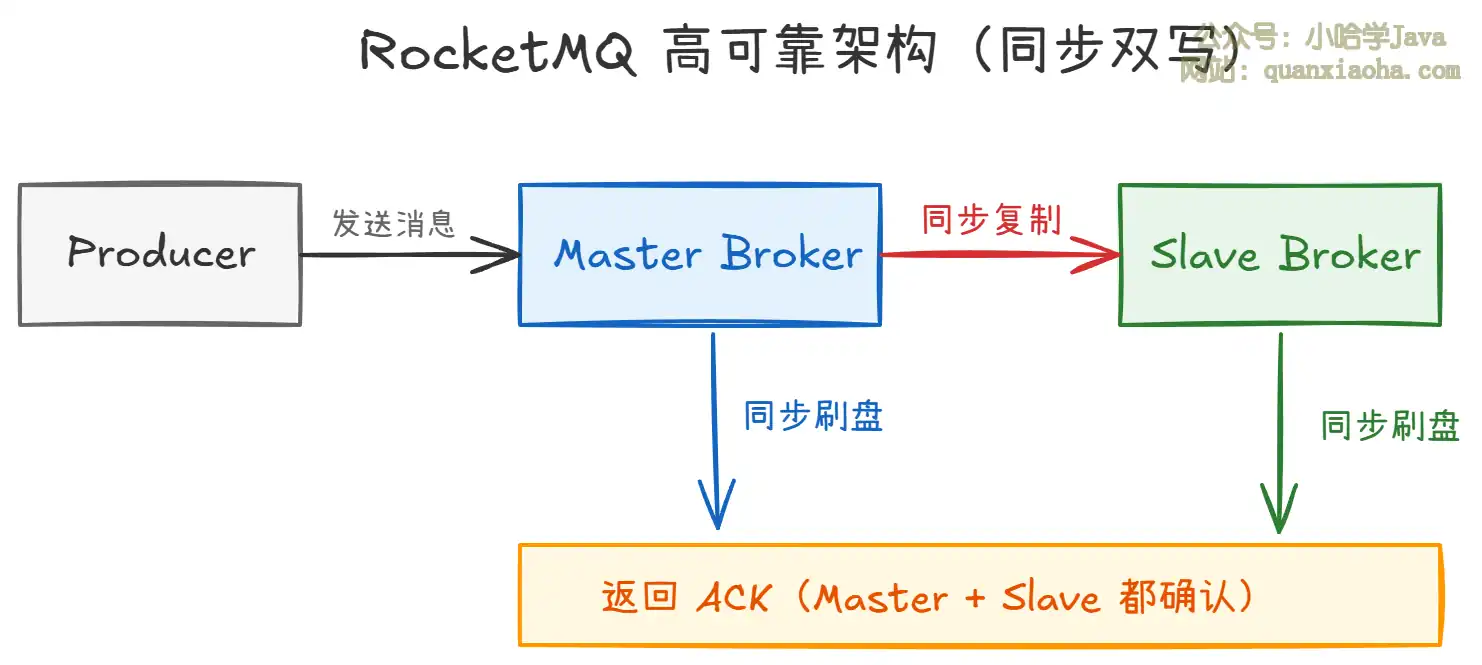
上图展示了 RocketMQ 的同步双写机制:
- 同步刷盘:消息先写入内存(PageCache),再
fsync刷到磁盘后才返回 ACK。即使机器断电,消息也不会丢失。 - 同步复制:Master 将消息同步到 Slave,Slave 确认写入后才返回成功。Master 宕机时 Slave 可以无缝接管。
- 双重保障:同步刷盘 + 同步复制,提供金融级别的消息可靠性保障。
相比之下,Kafka 默认异步刷盘(依赖操作系统 PageCache 刷盘),在 Broker 宕机时可能丢失未刷盘的消息。
理由 3:延迟消息——天然支持定时触发
// RocketMQ 开源版支持 18 个固定延迟等级(5.0 后支持任意延迟)
// 等级:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
Message msg = new Message("ORDER_TOPIC", "订单超时检查", orderJson.getBytes());
// 设置延迟等级为 16,即延迟 30 分钟
msg.setDelayTimeLevel(16);
producer.send(msg);
// RocketMQ 5.0+ 支持任意延迟时间
msg.setDelayTimeSec(600); // 延迟 10 分钟
典型应用场景:
- 订单超时自动取消:下单 30 分钟未支付自动关单
- 延迟通知:用户注册 3 天后发送引导消息
- 重试机制:失败后延迟递增重试
Kafka 不支持延迟消息,需要借助外部定时任务框架(如定时轮询数据库),复杂度倍增。
理由 4:顺序消息——保证消息的消费顺序
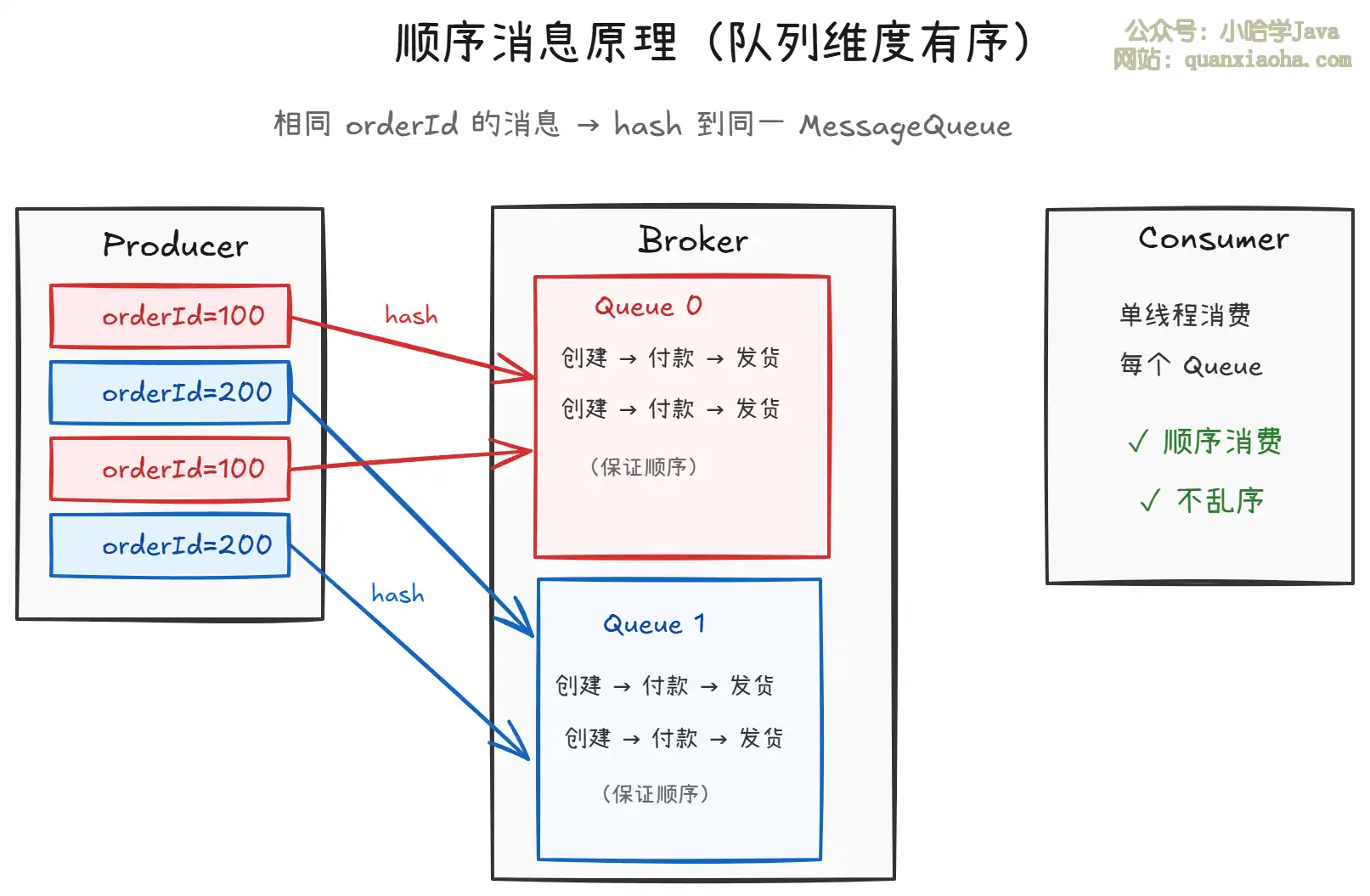
上图展示了 RocketMQ 顺序消息的核心原理:
- 发送端:相同业务 Key(如 orderId)的消息通过
MessageQueueSelector进行 hash 路由,保证同一 Key 的消息进入同一个MessageQueue。 - 消费端:每个
MessageQueue由单线程消费,天然保证同一队列内消息的顺序性。 - 不同 Key 之间:分布在不同队列,可以并行消费,不影响吞吐量。
理由 5:消息过滤——服务端过滤减少网络传输
// 发送消息时设置 Tag 和自定义属性
Message msg = new Message("TRADE_TOPIC", "TAG_PAY", "交易数据".getBytes());
msg.putUserProperty("level", "important");
msg.putUserProperty("region", "east");
// 消费者通过 Tag 过滤(服务端过滤,减少网络传输)
consumer.subscribe("TRADE_TOPIC", "TAG_PAY || TAG_REFUND");
// 通过 SQL92 表达式过滤(更灵活)
consumer.subscribe("TRADE_TOPIC",
MessageSelector.bySql("level = 'important' AND region = 'east'"));
RocketMQ 支持两种过滤方式:
- Tag 过滤:Broker 端直接过滤,只将匹配的消息推送给 Consumer,大幅减少网络传输。
- SQL92 过滤:支持更复杂的条件表达式,适合精细化订阅场景。
对比 Kafka 需要消费者拉取所有消息后自行过滤,浪费带宽和 CPU。
理由 6:全 Java 技术栈——降低运维和排查成本
- 源码纯 Java,团队可以直接阅读源码定位问题
- 可以基于 RocketMQ 做二次开发(如自定义 Broker 插件、消息轨迹等)
- JVM 生态监控工具全面(Arthas、Prometheus + Grafana 等)
- 阿里云商业版(ONS)提供企业级技术支持
三、技术选型决策树
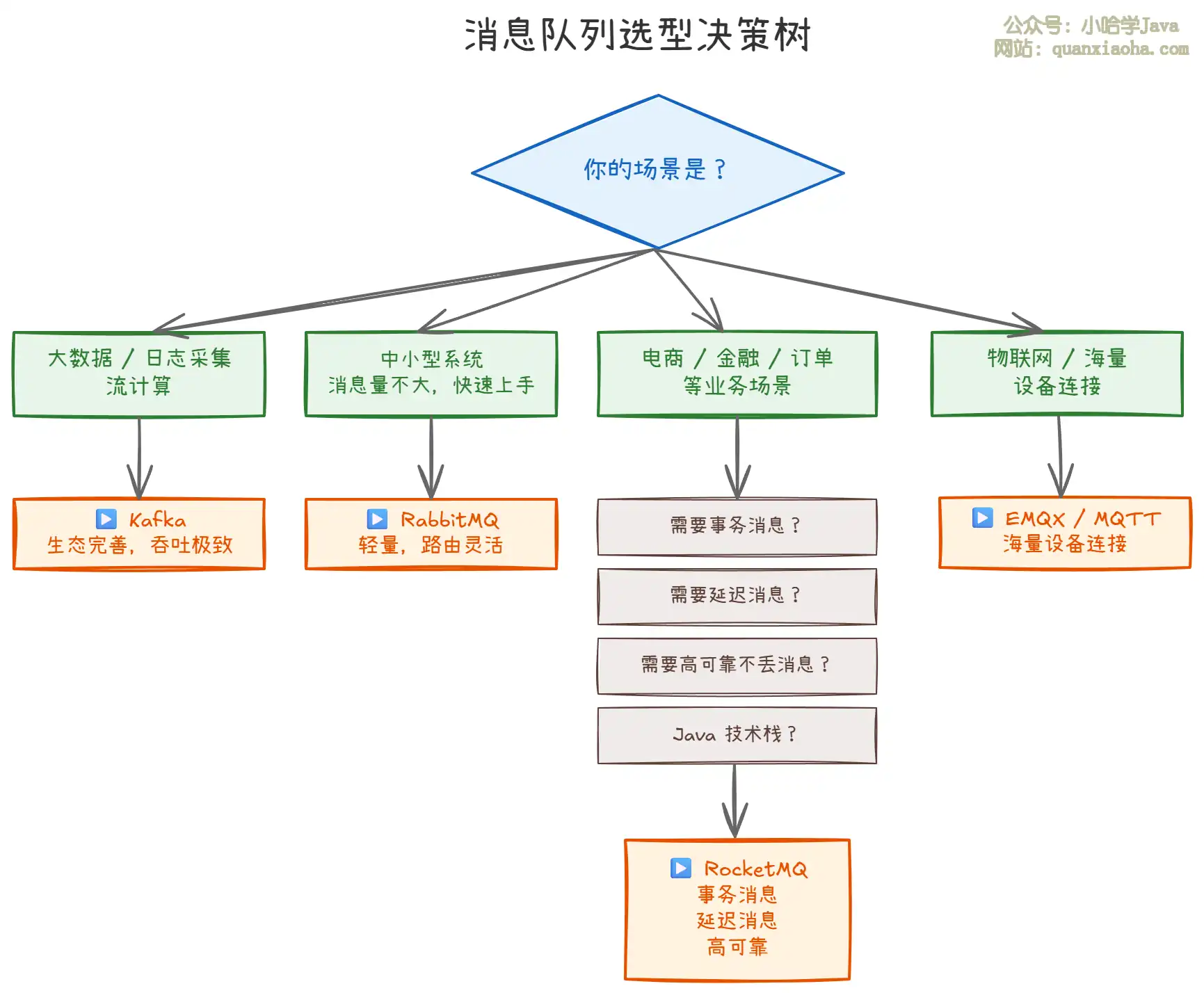
上图展示了一个简化的消息队列选型决策树:
- 大数据场景优先选 Kafka,因为其与 Spark、Flink 等大数据组件深度集成,吞吐量极致。
- 中小型系统选 RabbitMQ,轻量级、开箱即用、路由规则灵活。
- 业务消息场景(电商、金融、订单),只要满足 "事务消息、延迟消息、高可靠、Java 栈" 中任意一个需求,RocketMQ 就是最优解。
面试高频追问
-
追问一:RocketMQ 怎么保证消息不丢失?
- 生产端:同步发送 + 重试机制
- Broker 端:同步刷盘 + 同步复制
- 消费端:手动 ACK,消费失败重试 + 死信队列
-
追问二:RocketMQ 的事务消息原理是什么?
- 半消息 → 本地事务 → 二次确认(Commit/Rollback)→ 事务回查,保证最终一致性
-
追问三:RocketMQ 和 Kafka 的吞吐量差多少?
- 单机差距不大(都是 10 万级 TPS),但 Kafka 在 partition 多、消息量大时更有优势。RocketMQ 在单队列性能上更优(优化了锁粒度)
-
追问四:项目中是怎么用 RocketMQ 的?能举几个实际场景吗?
- 订单超时取消(延迟消息)、分布式事务(事务消息)、异步解耦(普通消息)、数据同步(广播消费)
常见面试变体
- 变体一:"RocketMQ、Kafka、RabbitMQ 有什么区别?怎么选?"
- 变体二:"为什么不用 Kafka 而用 RocketMQ?"
- 变体三:"RocketMQ 有哪些高级特性?项目中用到了哪些?"
- 变体四:"介绍一下你们项目中消息队列的使用场景"
记忆口诀
选型口诀:大数据选 Kafka,轻量选 Rabbit,业务消息选 Rocket。
RocketMQ 优势:事务消息是杀手锏,同步双写保可靠,延迟消息免定时,全 Java 栈好排查。
总结
选择 RocketMQ 的核心逻辑是:在业务消息场景(电商、金融、订单等)下,RocketMQ 提供了事务消息、延迟消息、高可靠同步双写等 Kafka 和 RabbitMQ 不具备或不擅长的特性,同时全 Java 技术栈降低了团队的学习和运维成本。面试时不要泛泛罗列优点,而是要结合项目实际需求(如 "我们订单系统需要 30 分钟超时取消,RocketMQ 原生支持延迟消息"),做到场景驱动选型。