为什么 Tomcat 默认最大线程数是 200,而不是 N+1?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
为什么 Tomcat 默认最大线程数是 200,而不是 N+1?
面试考察点
-
线程模型理解深度:面试官不仅仅是想知道 Tomcat 的默认配置值,更是想考察你是否理解 "线程数 ≠ CPU 核心数" 这件事背后的本质——Tomcat 处理的是 IO 密集型任务,不是 CPU 密集型任务。
-
理论与实践结合能力:N+1 是 CPU 密集型的经验公式,但 Tomcat 是 Web 服务器,处理的是 HTTP 请求(大量 IO 等待)。面试官想看你是否能区分场景,而不是机械套公式。
-
系统调优意识:进一步考察你对 Tomcat 线程池模型、Connector 架构、以及生产环境如何根据业务特点调优的理解。
核心答案
直接说结论:Tomcat 默认 maxThreads=200,是因为它处理的是 IO 密集型任务,线程大部分时间在等待(等数据库返回、等网络 IO、等下游服务响应),而不是在疯狂吃 CPU。
N+1 那个公式只适用于 CPU 密集型任务。两者的本质区别:
| 维度 | CPU 密集型 | IO 密集型(Tomcat 场景) |
|---|---|---|
| 瓶颈 | CPU 算力 | IO 等待(网络、磁盘、数据库) |
| 线程状态 | 大部分在 RUNNING | 大部分在 WAITING / BLOCKED |
| 线程数经验值 | N+1 | 2N 或更高,甚至几十倍于核心数 |
| 典型场景 | 加密计算、压缩、排序 | Web 请求处理、RPC 调用、文件读写 |
Tomcat 选 200 这个值,是 Apache 团队经过大量压测和线上验证后得出的一个通用安全默认值,适用于绝大多数中等负载的 Web 应用。
深度解析
一、一个请求在 Tomcat 里到底在干嘛?
先搞清楚一件事:Tomcat 里的线程,绝大部分时间并不是在 "跑代码",而是在 "等"。
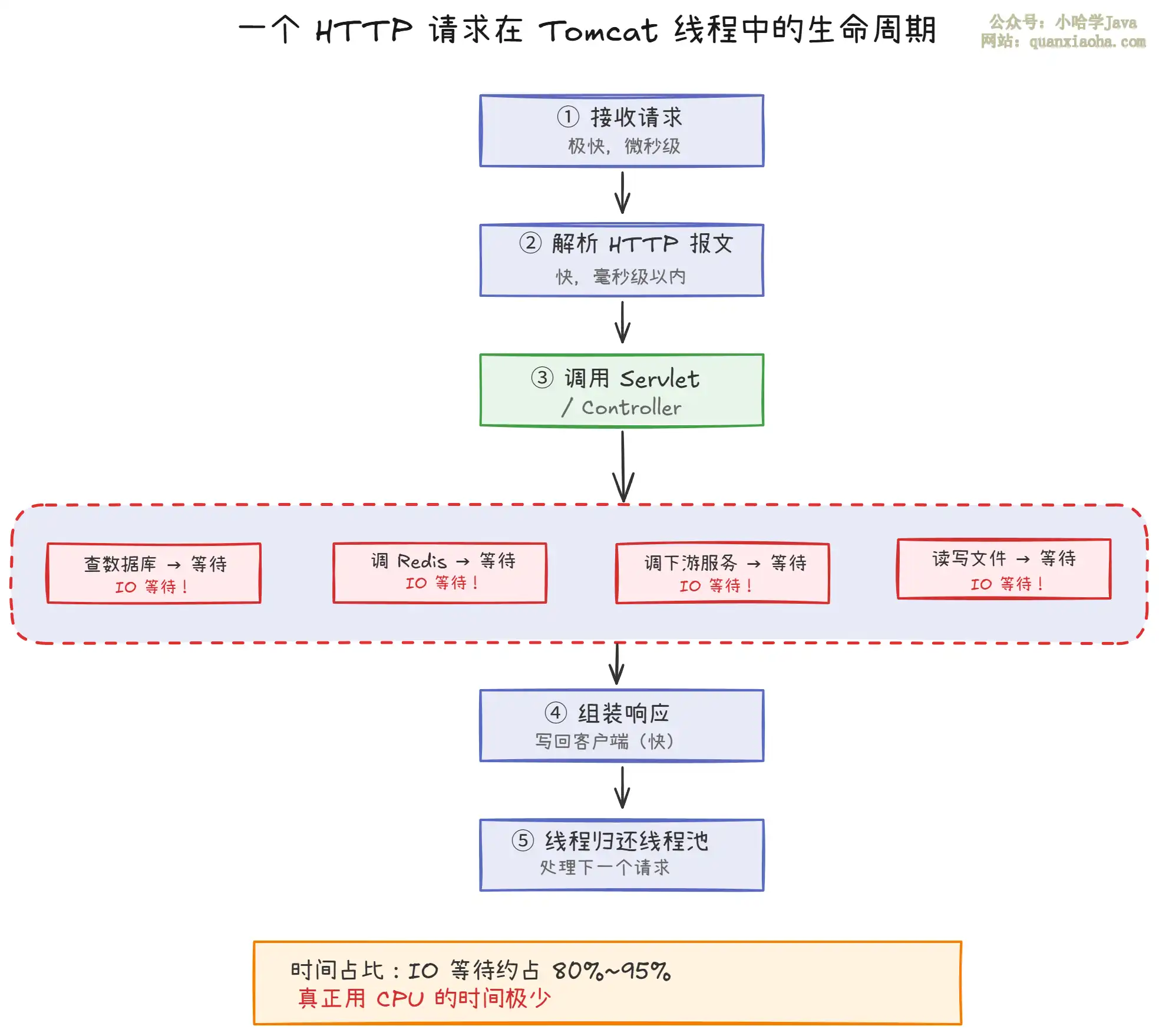
上图展示了一个典型 HTTP 请求的处理过程。关键点:
- 一个请求从进来到响应回去,真正占用 CPU 的时间可能只有几毫秒,但整个请求耗时可能是 50ms、200ms 甚至几秒
- 剩下的时间线程都处于 WAITING 状态(等数据库、等网络、等磁盘),这时候它 不消耗 CPU
- 既然不消耗 CPU,那多开一些线程就不会造成 CPU 争抢,反而能提高吞吐量——一个线程等 IO 的时候,CPU 可以去跑另一个线程的业务逻辑
二、为什么 N+1 在这里不适用?
N+1 的前提假设是:线程几乎一直在用 CPU。比如你用多线程做加密计算、排序、视频编码,线程一刻不停地在算,这时候开太多线程反而有害——线程上下文切换的开销会吃掉 CPU 时间。
但在 Tomcat 里,情况完全不同:
// 一个典型的 Spring Controller 方法
@GetMapping("/user/{id}")
public User getUser(@PathVariable Long id) {
// 线程大部分时间卡在这一行——等数据库返回
// 这期间线程处于 WAITING 状态,不占 CPU
return userService.findById(id);
}
假设一个请求总共耗时 100ms,其中查数据库花了 90ms,真正 CPU 运算只有 10ms。那你 8 核机器开 200 个线程完全没问题——因为同一时刻可能只有十几个线程在用 CPU,剩下 180 多个都在等 IO。
三、200 这个数字怎么来的?
Apache 团队选 200 作为默认值,考虑了这些因素:
- 通用性:作为一个开箱即用的 Web 服务器,默认值要能覆盖绝大多数中等负载场景
- 上下文切换的平衡点:线程数太少,吞吐量上不去;线程数太多,上下文切换开销反而拖慢系统。200 是一个经验上的 "甜点值"
- 内存开销可控:Linux 默认线程栈大小约 1MB,200 个线程约占 200MB 栈内存,对现代服务器来说完全可接受
- 历史经验:这是 Apache HTTP Server、Tomcat 等 Web 服务器多年生产验证的结果
当然,200 不是万能的。如果你的应用是 CPU 密集型(比如在 Servlet 里做大量计算),那 200 就太多了;如果你的应用 IO 等待非常严重(比如每次请求要调 5 个下游服务,每个耗时 500ms),那 200 可能还不够。
四、Tomcat 线程模型 vs JDK 线程池
这里有个很容易忽略的点:Tomcat 的线程池(org.apache.tomcat.util.threads.ThreadPoolExecutor)和 JDK 的 java.util.concurrent.ThreadPoolExecutor 不一样。

上图对比了两种线程池的核心差异。关键区别在于:
- JDK 线程池:核心线程满了 → 先塞队列 → 队列满了才创建非核心线程。这意味着如果用了无界队列(比如
LinkedBlockingQueue),最大线程数形同虚设,永远不会创建非核心线程 - Tomcat 线程池:核心线程满了 → 先塞队列 → 队列满了立刻创建非核心线程(重写了
execute()方法)。这样能更快地利用空闲线程处理突发流量
这个设计差异的背后逻辑是:JDK 线程池是通用设计,面向的是任务提交者;Tomcat 线程池是专门为 HTTP 请求设计的,面向的是高并发短任务场景,需要更积极的线程创建策略。
五、生产环境怎么调?
别迷信任何公式,压测才是王道。但可以参考以下思路:
<!-- server.xml 中的 Connector 配置 -->
<Connector port="8080"
protocol="HTTP/1.1"
minSpareThreads="10" <!-- 最小空闲线程数 -->
maxThreads="200" <!-- 最大线程数,根据压测调整 -->
acceptCount="100" <!-- 等待队列长度 -->
connectionTimeout="20000"
maxConnections="8192" <!-- 最大连接数,默认 8192(NIO)-->
/>
| 场景 | 建议配置 | 理由 |
|---|---|---|
| CPU 密集型接口 | maxThreads = 2N ~ 4N |
计算密集,线程不宜过多 |
| 普通 CRUD 业务 | maxThreads = 200 ~ 500 |
默认值即可,IO 等待占比高 |
| 重 IO 接口(调多个下游) | maxThreads = 500 ~ 1000 |
等待时间长,需要更多线程支撑吞吐量 |
| 低延迟要求 | 配合异步 Servlet | 用 NIO + 异步处理减少线程占用 |
面试高频追问
-
追问一:Tomcat 的
maxConnections和maxThreads有什么区别?maxConnections是 Tomcat 在 TCP 层面能同时接受的最大连接数(NIO 模式默认 8192),而maxThreads是实际处理业务逻辑的线程数。一个连接建立后,如果所有线程都在忙,就会放进acceptCount队列里等着。所以maxConnections≥maxThreads是合理配置。 -
追问二:如果线程数设太小会有什么问题?
请求会在
acceptCount队列里堆积,队列也满了就直接返回连接被拒绝。监控上会看到响应时间飙升、吞吐量上不去。所以核心思路是:通过压测找到吞吐量和响应时间的最佳平衡点。 -
追问三:Tomcat 支持 NIO 之后,线程模型有什么变化?
NIO 模式下(
protocol="org.apache.coyote.http11.Http11NioProtocol"),Tomcat 用少量的 Acceptor 线程 + Poller 线程来处理连接和 IO 读写,只有当请求需要交给 Servlet 处理时才从线程池取一个业务线程。这样进一步降低了线程和连接的 1:1 绑定关系,提升了资源利用率。
常见面试变体
- "Tomcat 的
maxThreads设成多少合适?为什么?" - "Web 服务器和计算密集型应用,线程池配置有什么区别?"
- "Tomcat NIO 模式下,连接数可以远大于线程数,原理是什么?"
记忆口诀
CPU 密集 N+1,IO 密集可以高,Tomcat 默认二百够用,生产调优靠压测。
总结
Tomcat 默认 200 个线程,本质上是因为 Web 请求是 IO 密集型任务,线程大部分时间在 "等" 而不是在 "算",所以可以远超 CPU 核心数。N+1 是给 CPU 密集型准备的公式,别乱套。生产环境怎么配?压测说话,别迷信公式。