HashMap 在 get 和 put 时,底层流程是怎样的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
核心操作理解:面试官不仅仅是想知道 "put 存数据、get 取数据" 这个表面行为,更是想知道你是否理解底层的数据结构操作,包括哈希计算、桶定位、冲突处理、链表/红黑树遍历等。
-
源码掌握深度:考察你是否读过
putVal()和getNode()的源码,是否理解扰动函数、树化条件、扩容触发等关键逻辑。 -
关联知识串联:能否将 hash 计算、equals 比较、扩容机制、红黑树转换等知识点串联起来,形成完整的认知体系。
核心答案
HashMap 的 get 和 put 操作都遵循 "计算 hash → 定位桶 → 遍历处理" 的核心逻辑:
| 操作 | 核心流程 | 时间复杂度 |
|---|---|---|
put(key, value) |
hash → 定位桶 → 查找/插入 → 更新 size → 检查扩容 | O(1) ~ O(log n) |
get(key) |
hash → 定位桶 → 遍历查找 → 返回 value | O(1) ~ O(log n) |
一句话总结:两者前半段逻辑相同(hash + 定位桶),put 多了插入/更新和扩容检查,get 只做查找返回。
深度解析
一、put 操作完整流程
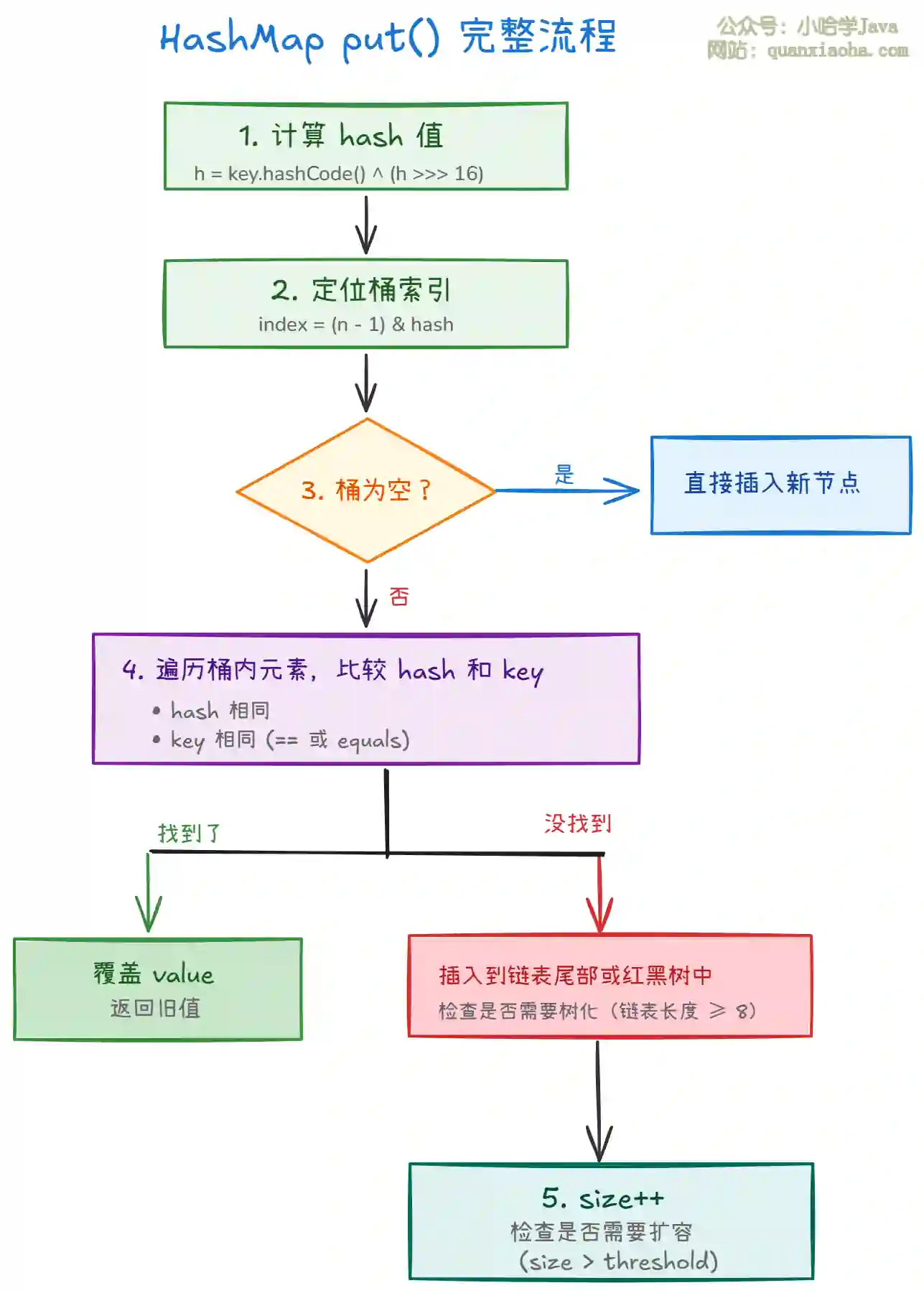
上图展示了 put() 方法的完整执行流程。整体分为 5 个关键步骤:
-
步骤一 - 计算 hash:调用
hash(key)方法,将 key 的hashCode()与其高 16 位异或,产生扰动后的哈希值。目的是让高位也参与运算,减少冲突。 -
步骤二 - 定位桶:通过
(n - 1) & hash计算桶索引。这里用位运算代替取模,效率更高。前提是 n 必须是 2 的幂次方。 -
步骤三 - 空桶检查:如果目标桶为空,直接创建新节点放入,最简单的情况。
-
步骤四 - 遍历处理:桶不为空时,需要遍历链表或红黑树。如果找到相同 key,覆盖旧值;如果没找到,插入新节点。
-
步骤五 - 后处理:
size++后检查是否超过阈值,触发扩容;如果是链表,检查长度是否达到树化阈值。
二、get 操作完整流程
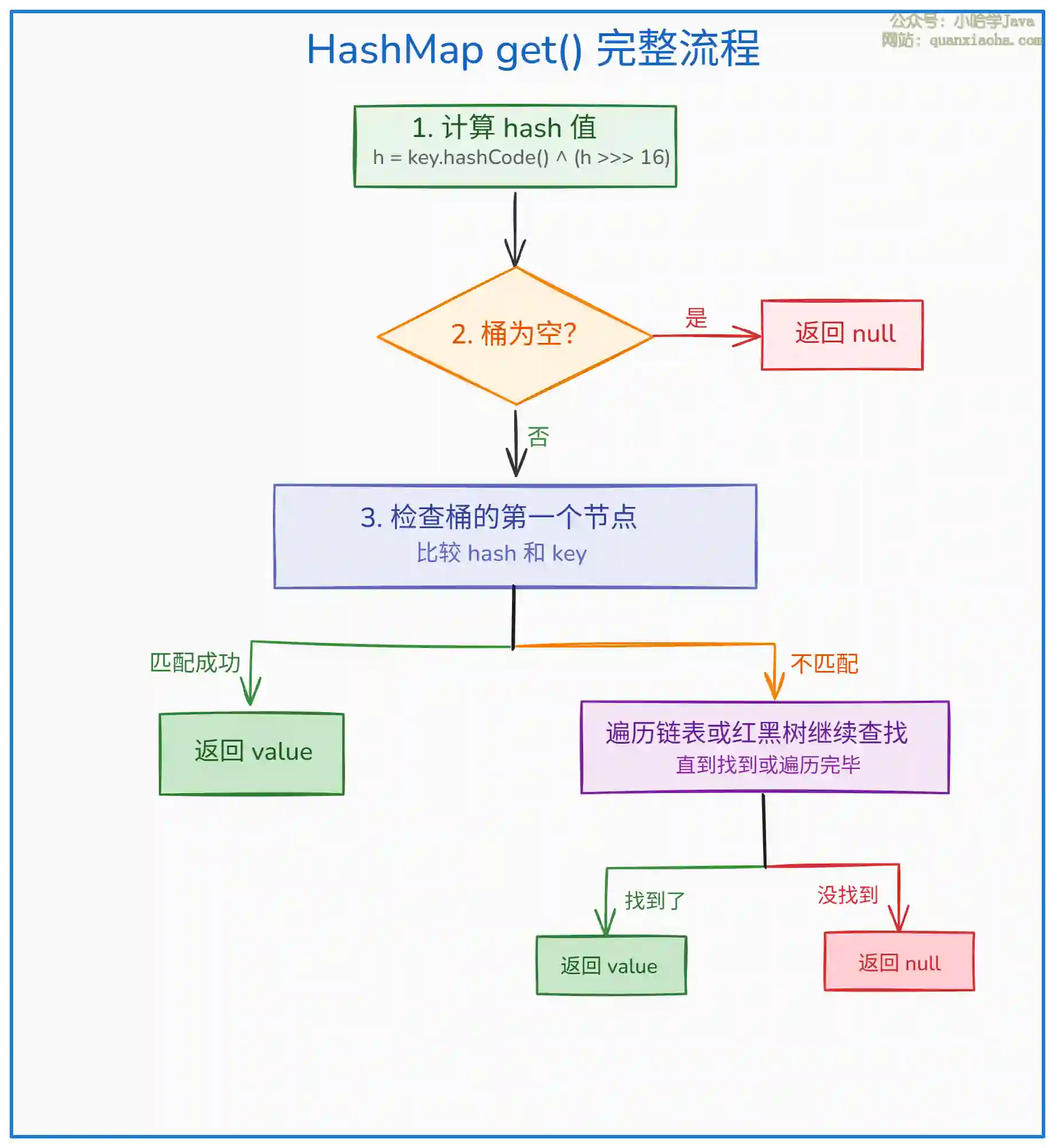
上图展示了 get() 方法的执行流程。与 put 相比,get 更简单:
- 共享步骤:hash 计算和桶定位逻辑完全相同
- 只读操作:不修改任何数据结构,只做查找
- 遍历策略:
- 链表:从头到尾遍历,O(n)
- 红黑树:二分查找,O(log n)
三、核心源码解析
// ==================== put 入口方法 ====================
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 扰动函数:让高位参与运算,减少冲突
static final int hash(Object key) {
int h;
// hashCode 与其高 16 位异或
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// ==================== putVal 核心实现 ====================
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 1. 初始化 table(延迟初始化)
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 2. 定位桶,桶为空则直接插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 3. 检查桶的第一个节点是否匹配
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 4. 红黑树查找/插入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 5. 链表遍历查找/插入
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 尾插法:插入到链表尾部
p.next = newNode(hash, key, value, null);
// 检查是否需要树化
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// 找到相同 key,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 6. 找到已存在的 key,覆盖旧值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // LinkedHashMap 回调
return oldValue;
}
}
// 7. 新插入节点,检查扩容
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict); // LinkedHashMap 回调
return null;
}
// ==================== get 入口方法 ====================
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
// ==================== getNode 核心实现 ====================
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 1. 定位桶
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 2. 检查第一个节点
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 3. 遍历后续节点
if ((e = first.next) != null) {
// 红黑树查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 链表遍历
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
四、hash 计算的奥秘
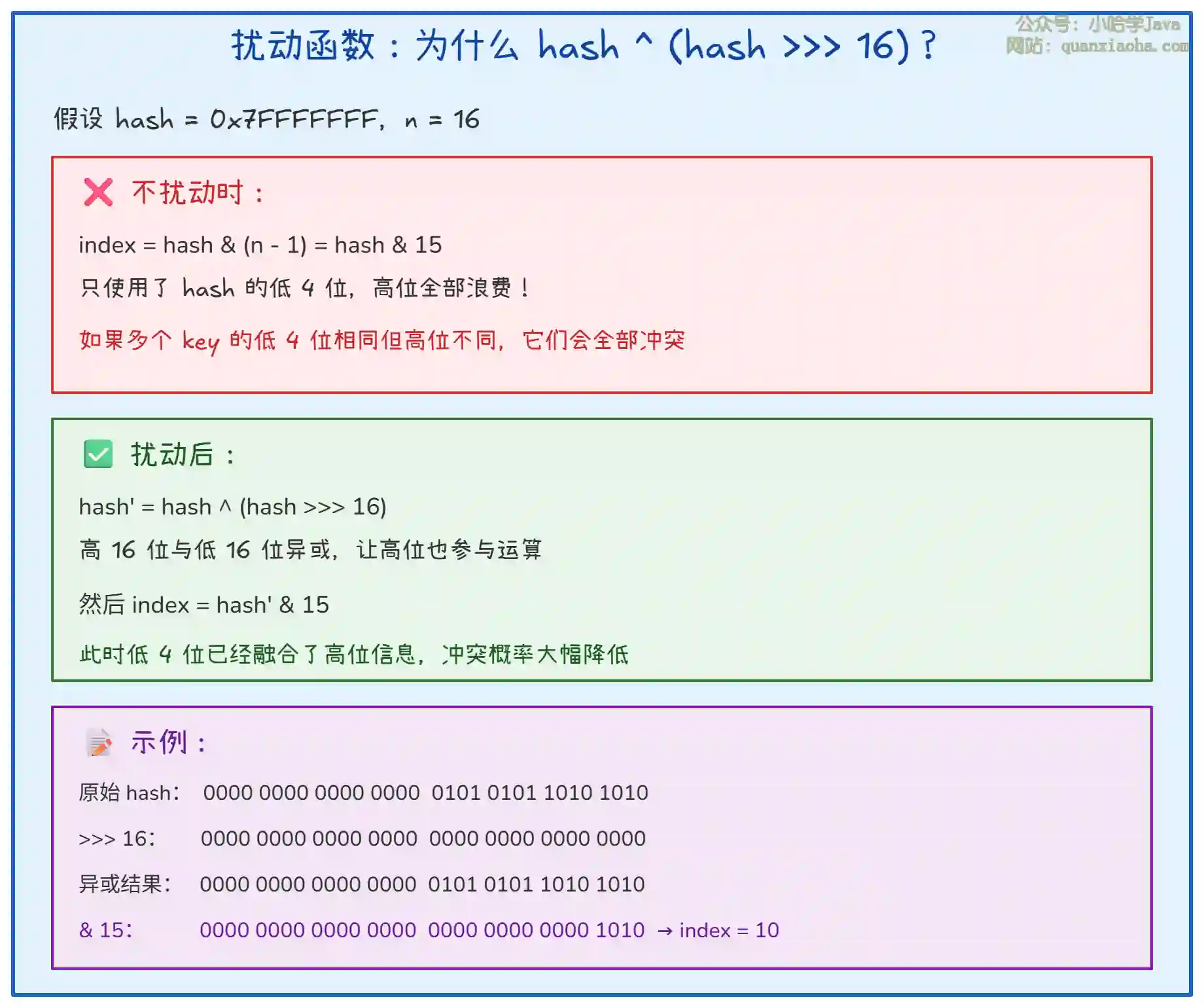
上图解释了扰动函数的设计初衷。关键理解:
- 问题:当 n 较小时(如 16),
(n - 1) & hash只用到 hash 的低 4 位,高位完全浪费 - 解决:
hash ^ (hash >>> 16)让高 16 位与低 16 位异或,相当于把高位信息 "混合" 到低位 - 效果:即使 key 的低位相同,只要高位不同,扰动后的结果也不同,减少冲突
五、put 和 get 的关键差异
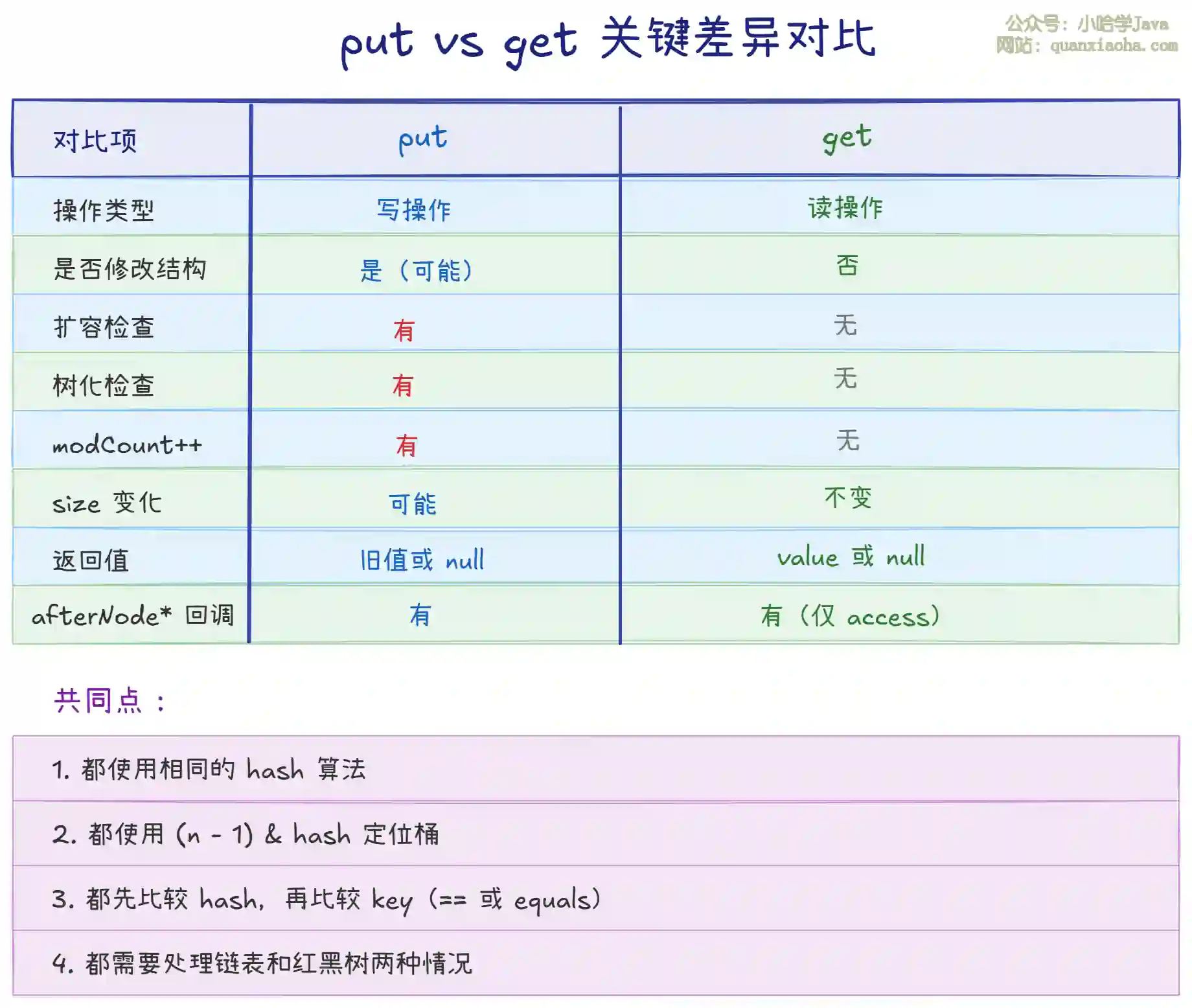
上图对比了 put 和 get 的关键差异。核心要点:
- put 更重:除了查找,还要处理插入、更新、扩容、树化等
- get 更轻:只做查找,不修改任何结构
- 共享逻辑:hash 计算和 key 比较逻辑完全相同,这是正确性的保证
面试高频追问
-
为什么用
(n - 1) & hash而不是hash % n?- 位运算效率远高于取模运算
- 前提是 n 必须是 2 的幂次方,这是 HashMap 容量的约束
-
为什么先比较 hash 再比较 key?
- hash 比较快(整数比较),可以快速过滤不匹配的节点
equals()可能较慢(尤其是复杂对象),放后面减少调用次数
-
put 返回 null 说明什么?
- 可能是新插入的 key(没有旧值)
- 也可能是 key 已存在但旧值为 null
- 需要用
containsKey()区分
常见面试变体
- "HashMap 的 put 流程是怎样的?"
- "HashMap 如何解决哈希冲突?"
- "HashMap 中 hash 函数是如何设计的?"
- "get 和 put 的时间复杂度是多少?"
记忆口诀
put 流程:算 hash、定桶位、空桶插、有桶找、找到换、找不到插尾、检查树化和扩容。
get 流程:算 hash、定桶位、空桶返 null、有桶找、链表遍历红黑树找、找到返值没找到返 null。
共同点:hash 算法一样、桶定位一样、先比 hash 再比 key。
总结
HashMap 的 put 和 get 操作都遵循 "hash → 定位桶 → 遍历处理" 的核心逻辑。put 流程更复杂,包含初始化、插入、更新、树化检查、扩容检查等步骤;get 相对简单,只做查找返回。两者共享 hash 计算和 key 比较逻辑,时间复杂度在理想情况下为 O(1),最坏情况(红黑树)为 O(log n)。