HashMap、Hashtable 和 ConcurrentHashMap 的区别?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
线程安全认知:面试官不仅仅是想知道这三者谁是线程安全的,更是想考察你是否理解不同线程安全实现方式的性能差异,以及为什么
Hashtable已经被淘汰。 -
并发编程深度:考察你是否了解
ConcurrentHashMap的底层实现原理,包括 JDK 7 的分段锁和 JDK 8 的 CAS +synchronized两种方案的演进。 -
生产实践能力:能否根据实际场景(读多写少、高并发等)选择合适的 Map 实现,避免盲目使用导致的性能问题或线程安全隐患。
核心答案
三者都是 Map 接口的实现类,但线程安全性和性能差异显著:
| 特性 | HashMap | Hashtable | ConcurrentHashMap |
|---|---|---|---|
| 线程安全 | ❌ 不安全 | ✅ 安全 | ✅ 安全 |
| 锁粒度 | 无锁 | 整表锁(粗粒度) | 桶级别锁(细粒度) |
| null 键/值 | ✅ 都允许 | ❌ 都不允许 | ❌ 都不允许 |
| 初始容量 | 16 | 11 | 16 |
| 扩容倍数 | 2 倍 | 2n + 1 | 2 倍 |
| 迭代器 | 快速失败 | 快速失败 | 弱一致性 |
| 底层结构(JDK 8) | 数组 + 链表/红黑树 | 数组 + 链表 | 数组 + 链表/红黑树 |
| 性能 | 最高(单线程) | 最低(全表锁) | 高(并发优秀) |
| 适用场景 | 单线程或外部同步 | 已淘汰 | 高并发多线程 |
一句话总结:单线程用 HashMap,多线程用 ConcurrentHashMap,Hashtable 已被淘汰(历史遗留类)。
深度解析
一、线程安全实现对比
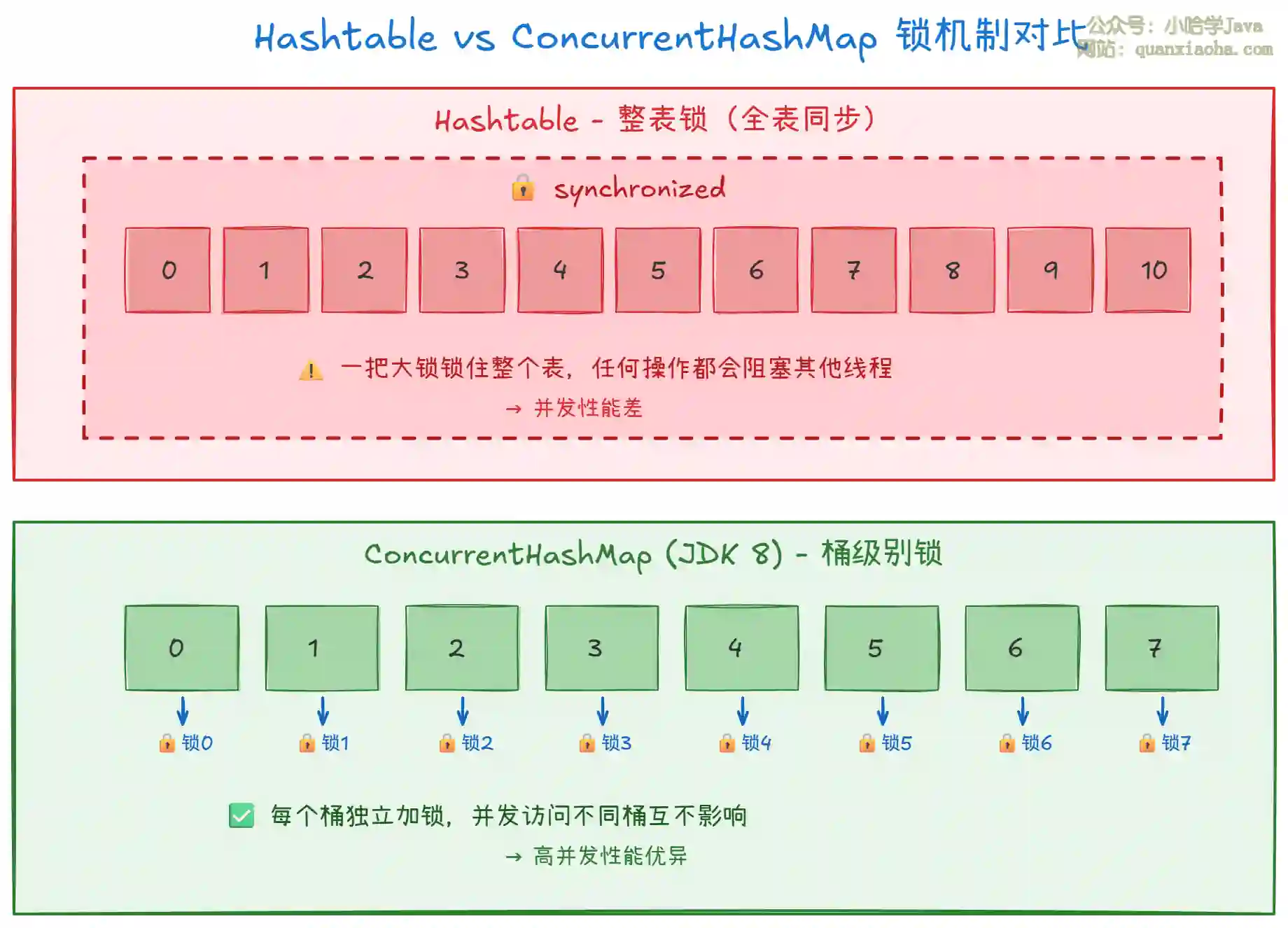
上图展示了两种线程安全实现的核心差异:
-
Hashtable:使用
synchronized修饰几乎所有方法,一把大锁锁住整个哈希表。任何时刻只允许一个线程操作,即使是访问不同位置的元素也会相互阻塞,并发性能极差。 -
ConcurrentHashMap (JDK 8):采用桶级别细粒度锁,每个桶(数组位置)独立加锁。线程 A 操作索引 2 的元素,线程 B 操作索引 5 的元素,两者互不影响,可并发执行。
二、ConcurrentHashMap 的演进
JDK 7:分段锁(Segment)
// JDK 7 的分段锁设计
public class ConcurrentHashMap<K, V> {
final Segment<K,V>[] segments; // 默认 16 个分段
static final class Segment<K,V> extends ReentrantLock {
transient volatile HashEntry<K,V>[] table; // 每个分段维护一个小哈希表
}
}
分段锁将整个 Map 分成多个段(默认 16 个),每段一把 ReentrantLock。并发度最高为分段数。
JDK 8:CAS + synchronized
// JDK 8 的桶级别锁设计
public class ConcurrentHashMap<K, V> {
transient volatile Node<K,V>[] table; // 单一数组,不再分段
// 核心插入逻辑(简化版)
final V putVal(K key, V value, boolean onlyIfAbsent) {
int hash = spread(key.hashCode());
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶为空,CAS 无锁插入
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break;
}
else {
// 桶不为空,synchronized 加锁当前桶
synchronized (f) {
// 链表遍历或红黑树插入...
}
}
}
return null;
}
}
JDK 7 vs JDK 8 对比:
| 对比项 | JDK 7 分段锁 | JDK 8 CAS + synchronized |
|---|---|---|
| 锁粒度 | 分段级别(默认 16 段) | 桶级别(更细) |
| 并发度 | 最大为段数 | 理论上为数组长度 |
| 内存占用 | 高(多个 Segment 对象) | 低(单一数组) |
| 锁类型 | ReentrantLock |
synchronized + CAS |
| 扩容 | 分段独立扩容 | 协同扩容(多线程协助) |
三、HashMap 的线程安全问题
HashMap 在多线程环境下有严重问题:
1. JDK 7 扩容死循环
// JDK 7 扩容时的头插法会导致链表成环
void transfer(Entry[] newTable) {
Entry[] src = table;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
while (null != e) {
Entry<K,V> next = e.next; // 线程切换点
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; // 头插法:后插入的在前面
newTable[i] = e;
e = next;
}
}
}
// 多线程并发扩容时,链表可能形成环,导致 get() 死循环
2. JDK 8 数据丢失
// JDK 8 使用尾插法避免了死循环,但仍存在数据丢失问题
final V putVal(int hash, K key, V value, boolean onlyIfAbsent) {
// 两个线程同时判断桶为空,都执行写入
// 后写入的会覆盖先写入的,导致数据丢失
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); // 非原子操作
}
四、null 键值处理差异
// HashMap - 允许 null
HashMap<String, String> map = new HashMap<>();
map.put(null, "value"); // ✅ 允许
map.put("key", null); // ✅ 允许
// Hashtable / ConcurrentHashMap - 不允许 null
ConcurrentHashMap<String, String> cmap = new ConcurrentHashMap<>();
cmap.put(null, "value"); // ❌ NullPointerException
cmap.put("key", null); // ❌ NullPointerException
为什么不允许 null?
在多线程环境下,get(key) 返回 null 存在二义性:
- key 不存在
- key 存在但 value 为 null
单线程的 HashMap 可以用 containsKey() 判断,但多线程下判断和获取之间存在竞态条件。
五、迭代器特性
// HashMap/Hashtable - 快速失败(Fail-Fast)
HashMap<String, String> map = new HashMap<>();
Iterator<String> it = map.keySet().iterator();
map.put("newKey", "value"); // 结构性修改
it.next(); // 抛出 ConcurrentModificationException
// ConcurrentHashMap - 弱一致性(Weakly Consistent)
ConcurrentHashMap<String, String> cmap = new ConcurrentHashMap<>();
Iterator<String> cit = cmap.keySet().iterator();
cmap.put("newKey", "value"); // 不会抛异常
cit.next(); // 可能反映也可能不反映新数据,但不会抛异常
六、最佳实践
// ❌ 错误:多线程使用 HashMap
Map<String, String> map = new HashMap<>();
// 多线程并发写入可能导致数据丢失、死循环(JDK 7)
// ❌ 错误:使用 Hashtable
Map<String, String> table = new Hashtable<>(); // 性能太差,已淘汰
// ✅ 正确:多线程使用 ConcurrentHashMap
Map<String, String> cmap = new ConcurrentHashMap<>();
// ✅ 进阶:根据并发量调整初始容量
// 避免频繁扩容,预估元素数量 / 负载因子 + 1
Map<String, String> cmap = new ConcurrentHashMap<>(64);
// ✅ 读多写少场景可考虑 CopyOnWrite 方案(但内存开销大)
// 适合配置表、黑白名单等场景
面试高频追问
-
ConcurrentHashMap 在 JDK 7 和 JDK 8 中的实现有什么区别?
- JDK 7:分段锁(
Segment+ReentrantLock),并发度受分段数限制 - JDK 8:CAS +
synchronized桶级别锁,并发度更高,内存占用更低
- JDK 7:分段锁(
-
为什么 ConcurrentHashMap 不允许 null 键和 null 值?
- 多线程环境下
get()返回null存在二义性(不存在 vs 值为 null) - 避免在
containsKey()判断和get()获取之间出现竞态条件
- 多线程环境下
-
ConcurrentHashMap 的扩容是怎样实现的?
- JDK 8 采用多线程协同扩容:每个线程负责一部分桶的迁移
- 通过
transferIndex协调分配任务,支持并发扩容提升效率
常见面试变体
- "HashMap 在多线程环境下会有什么问题?"
- "为什么 Hashtable 被淘汰了?"
- "ConcurrentHashMap 如何保证线程安全?"
记忆口诀
选择口诀:
- 单线程用 HashMap:性能最高,允许 null
- 多线程用 ConcurrentHashMap:细粒度锁,高并发
- Hashtable 别用了:全表锁,已淘汰
锁粒度记忆:
- Hashtable = 大锅饭(一把锁)
- ConcurrentHashMap (JDK 7) = 分餐制(分段锁)
- ConcurrentHashMap (JDK 8) = 自助餐(桶级别锁)
总结
HashMap 非线程安全但性能最高,适合单线程;Hashtable 使用全表 synchronized 锁,性能差已被淘汰;ConcurrentHashMap 是多线程首选,JDK 8 采用 CAS + synchronized 桶级别锁实现高并发,迭代器弱一致性,不允许 null 键值。生产环境多线程场景必须使用 ConcurrentHashMap。