为什么在 Jdk 8 中 HashMap 要转成红黑树?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
性能优化意识:面试官不仅仅是想知道 "用了红黑树" 这个事实,更是想知道你是否理解链表查询 O(n) 的性能瓶颈,以及红黑树 O(log n) 的优化意义。
-
数据结构掌握:考察你是否了解红黑树的特点(自平衡、查询效率稳定),以及为什么选择红黑树而不是 AVL 树或 B+ 树。
-
安全防护认知:是否了解 HashDoS 攻击(恶意构造哈希冲突),以及红黑树如何作为防御手段。
核心答案
JDK 8 引入红黑树是为了 解决极端哈希冲突情况下链表查询性能退化的问题,将查询复杂度从 O(n) 优化到 O(log n):
| 对比项 | 链表 | 红黑树 |
|---|---|---|
| 查询复杂度 | O(n) | O(log n) |
| 插入复杂度 | O(1)(头插/尾插) | O(log n) |
| 空间开销 | 每节点 1 个 next 指针 | 每节点 left、right、parent、color |
| 适用场景 | 数据量小、冲突少 | 数据量大、冲突多 |
| 8 个元素查询 | 最坏 8 次 | 最多 3 次 |
一句话总结:红黑树是 HashMap 在极端冲突场景下的 "保底方案",防止查询性能从 O(1) 退化为 O(n)。
深度解析
一、链表的性能瓶颈
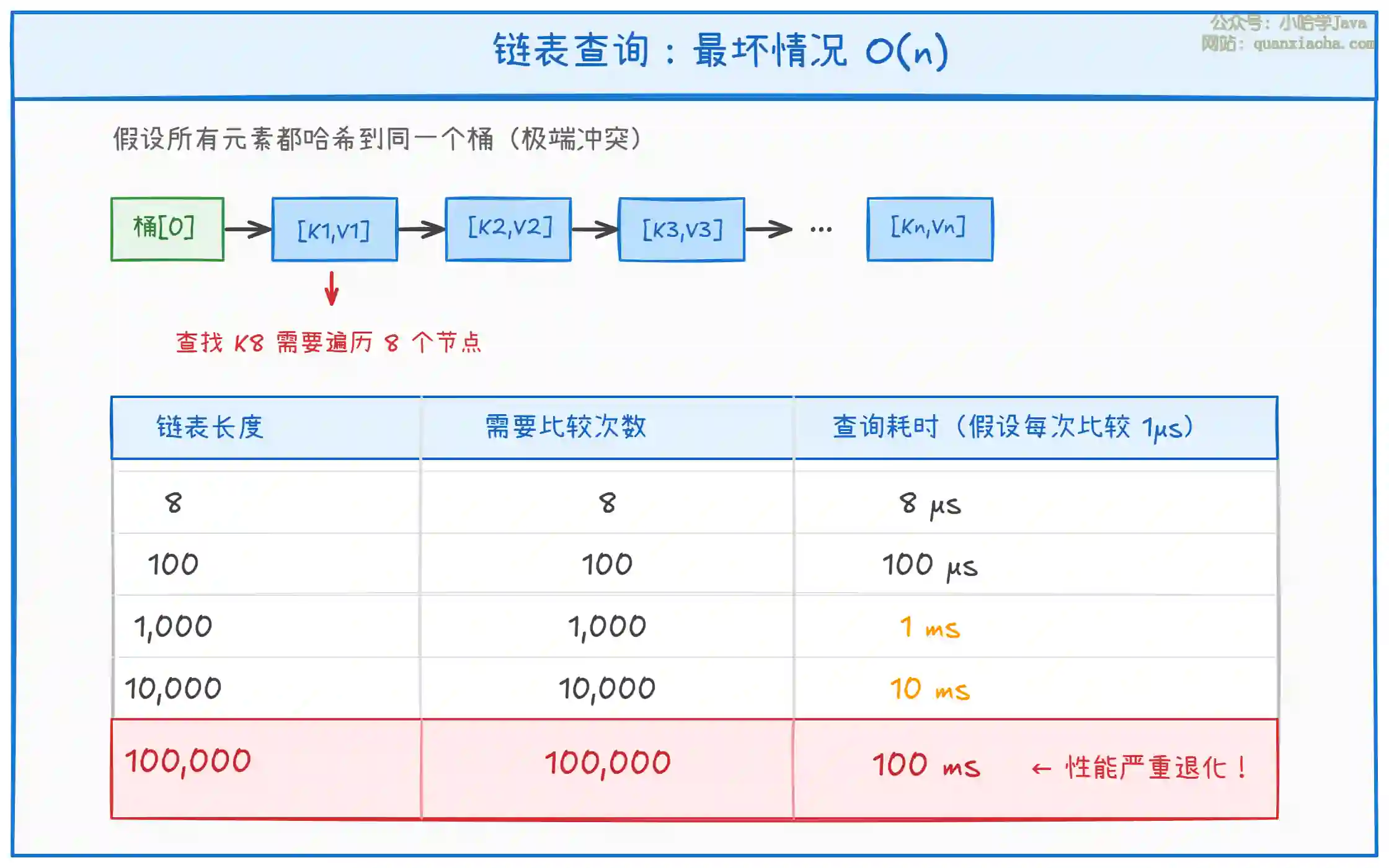
上图展示了链表在极端哈希冲突场景下的性能问题。关键点:
- 正常情况:哈希分布均匀,每个桶只有 0-2 个元素,查询接近 O(1)
- 极端情况:所有元素哈希到同一个桶,链表长度 = 元素总数,查询退化为 O(n)
- 现实场景:HashDoS 攻击、糟糕的哈希函数、特定数据分布都可能导致这种情况
二、红黑树的优化效果
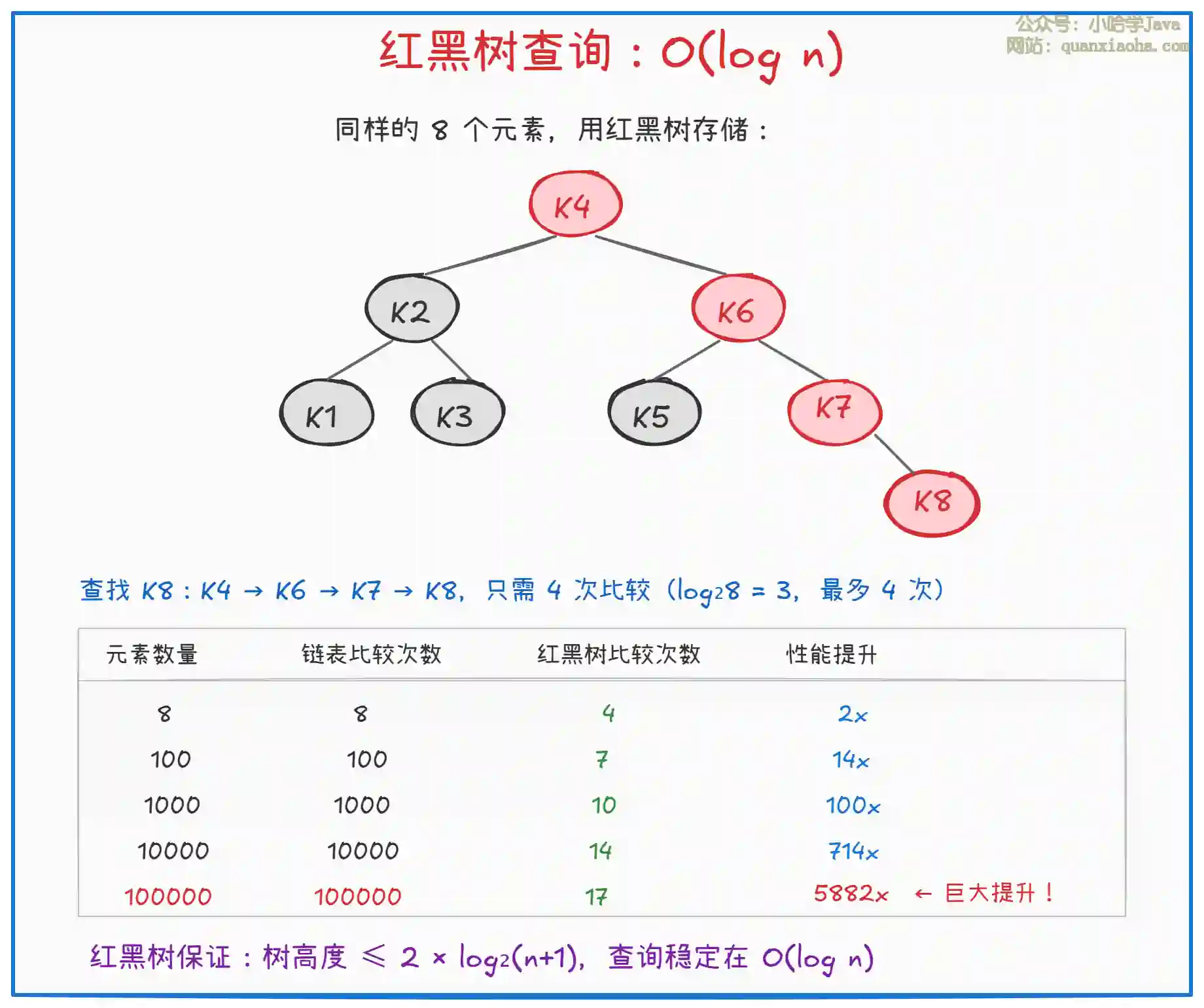
上图对比了链表和红黑树的查询效率差异。核心优势:
- 数量级提升:10 万元素的查询,从 10 万次比较降到 17 次,性能提升约 6000 倍
- 稳定可预测:红黑树是自平衡二叉搜索树,不会退化为链表
- 代价可控:虽然插入稍慢(需要旋转和变色),但查询是 HashMap 的核心操作
三、为什么选择红黑树而不是其他数据结构?
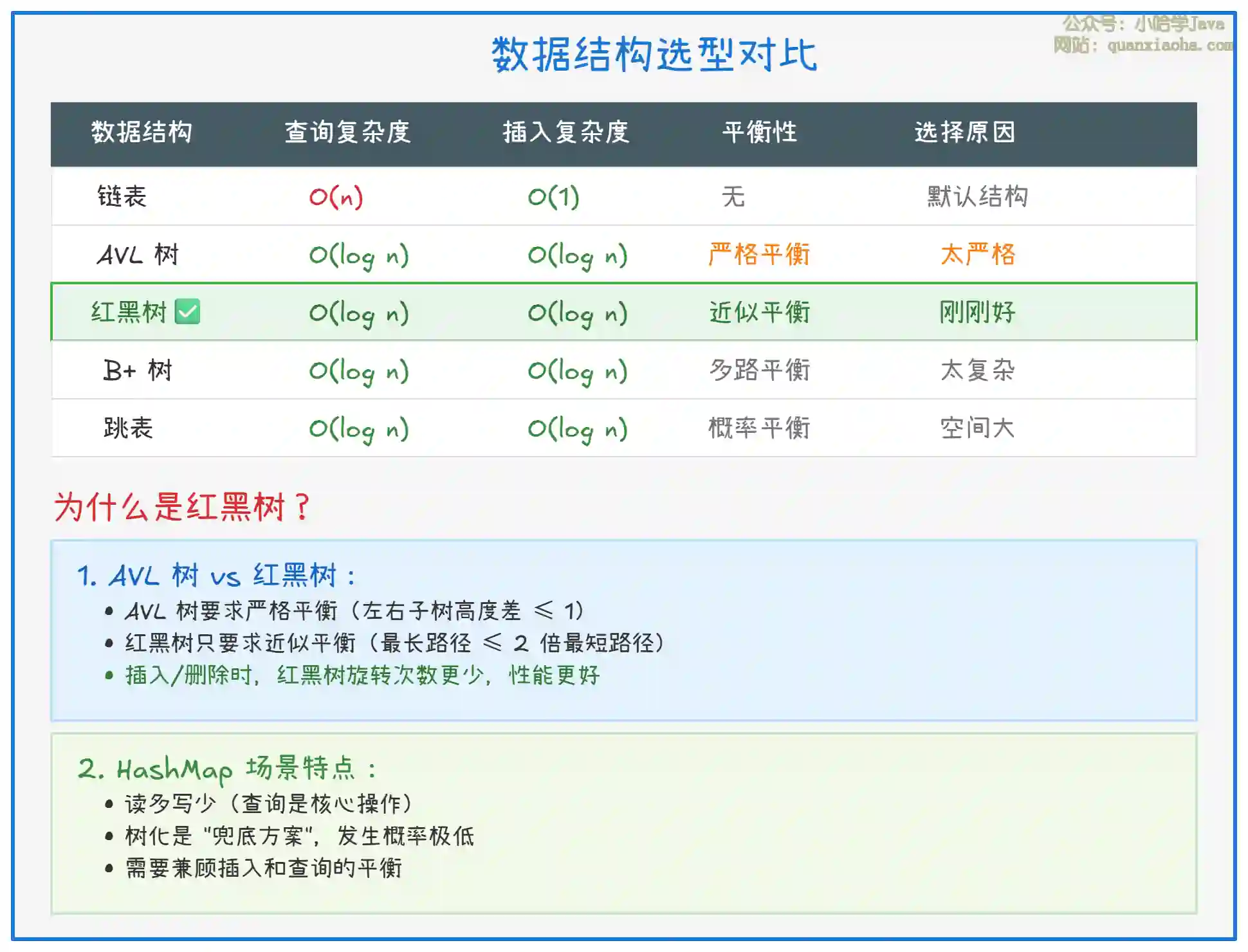
上图解释了为什么红黑树是最佳选择。关键理由:
- AVL 树太严格:每次插入/删除可能需要多次旋转,维护成本高
- 红黑树更实用:近似平衡已经够用,旋转次数有上限(插入最多 2 次旋转)
- 工程实践验证:红黑树在 C++ STL、Linux 内核等广泛使用,成熟稳定
四、树化的触发条件
// HashMap 源码中的树化条件
static final int TREEIFY_THRESHOLD = 8; // 链表 → 红黑树阈值
static final int MIN_TREEIFY_CAPACITY = 64; // 最小容量要求
// putVal 方法中的树化逻辑
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表长度达到 8 时,尝试树化
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// ...
}
// treeifyBin 方法
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 注意:如果容量 < 64,优先扩容而不是树化!
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// ... 转换为红黑树
}
}
两个条件必须同时满足:
| 条件 | 值 | 原因 |
|---|---|---|
| 链表长度 ≥ 8 | TREEIFY_THRESHOLD |
此时链表查询效率已经明显下降 |
| 数组容量 ≥ 64 | MIN_TREEIFY_CAPACITY |
容量小时,扩容比树化更有效 |
为什么容量 < 64 时优先扩容?
- 扩容可以将元素分散到更多桶中,从根本上减少冲突
- 树化增加了空间开销和代码复杂度,应该作为最后手段
- 小容量时,扩容的性价比更高
五、树化与退树
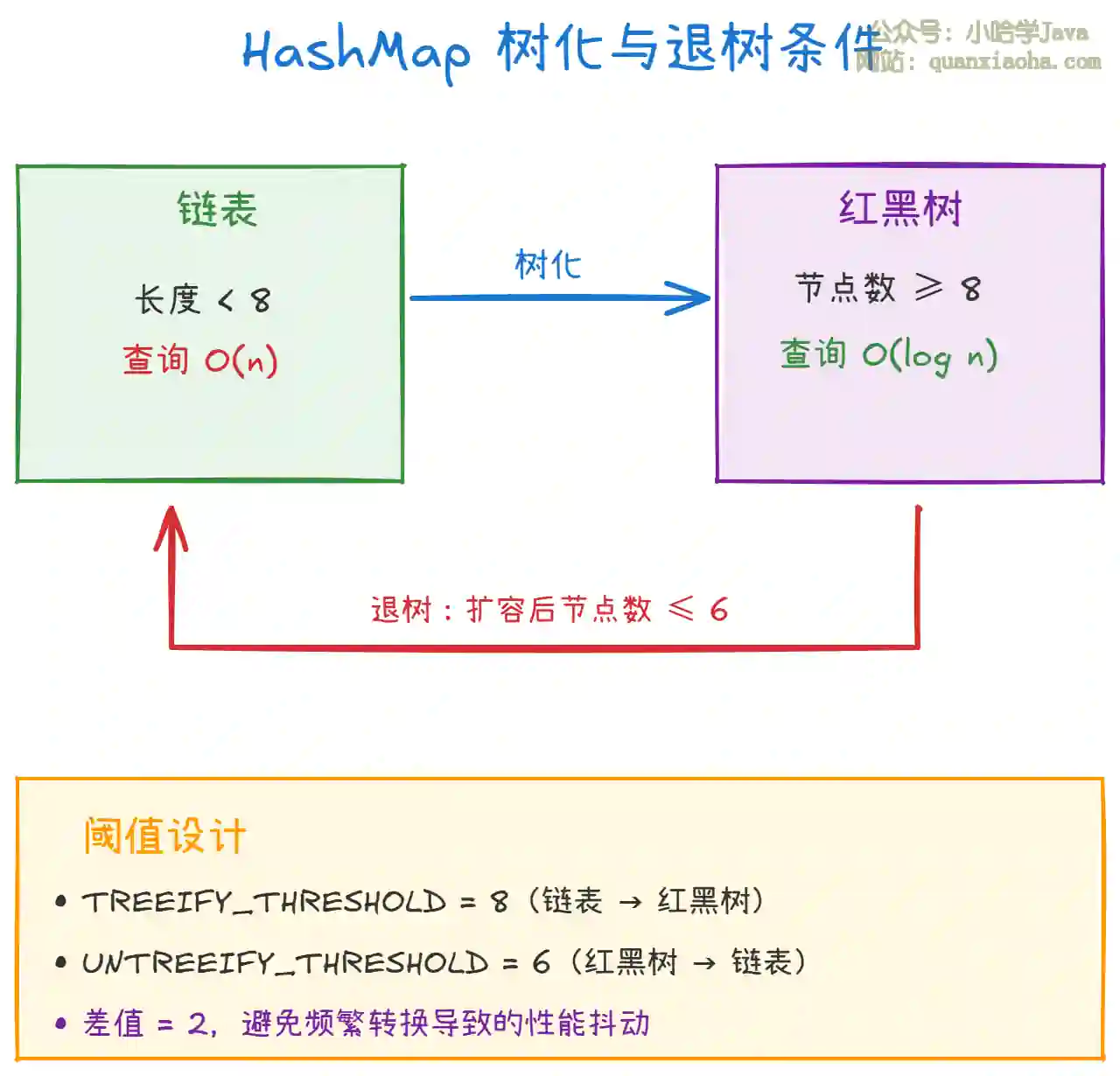
上图展示了树化和退树的转换条件。设计亮点:
- 滞后设计:阈值差 2,避免链表长度在 7-8 之间反复横跳
- 类似思想:ArrayList 扩容 1.5 倍、线程池核心线程回收,都有类似的滞后设计
六、防御 HashDoS 攻击
这是红黑树引入的安全意义:
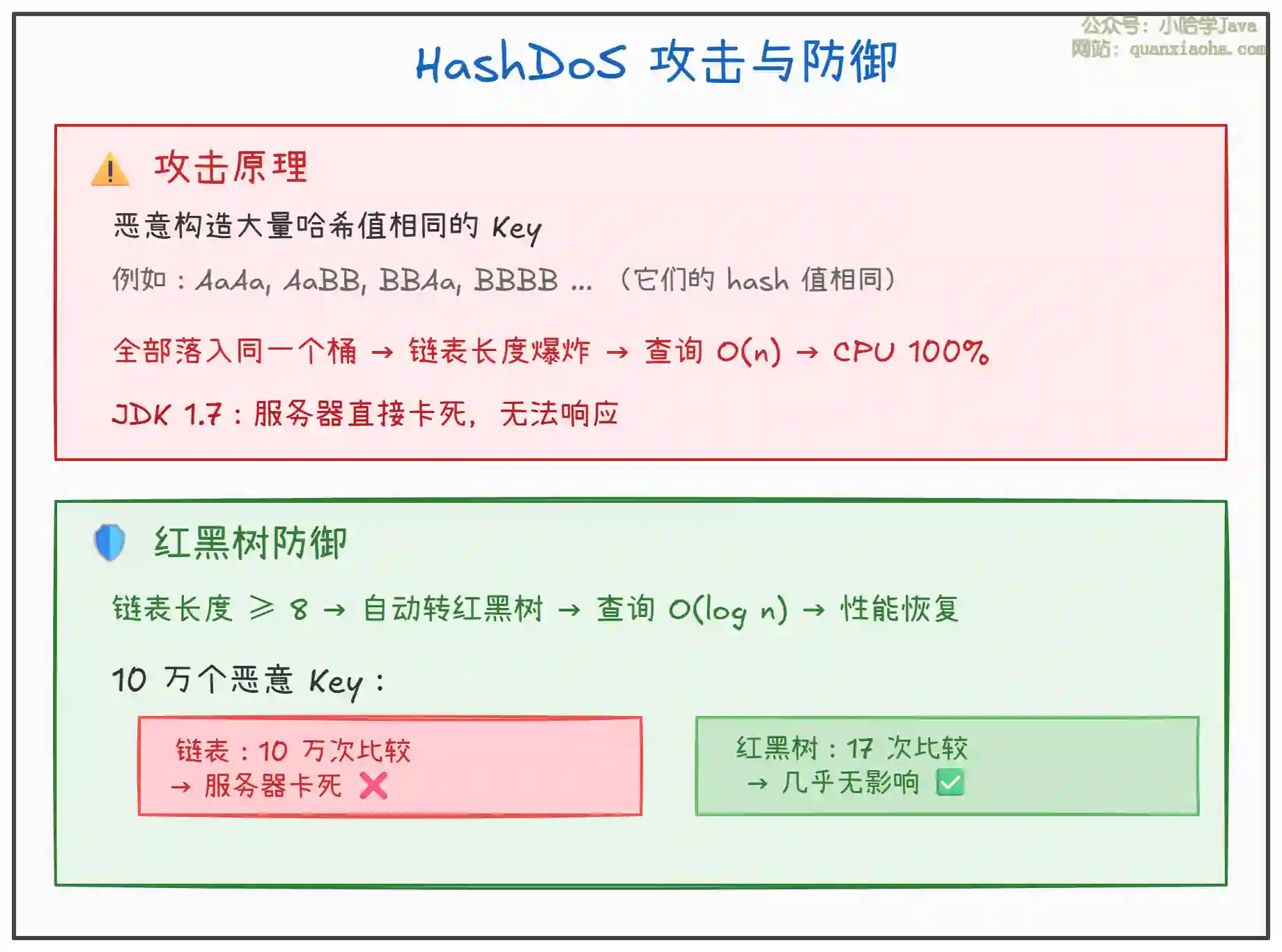
上图解释了红黑树的安全价值。关键点:
- HashDoS 攻击:2011-2012 年流行的攻击方式,针对哈希表算法复杂度漏洞
- JDK 1.7 的脆弱性:完全依赖链表,攻击者可以让服务器 CPU 100%
- JDK 1.8 的防御:红黑树将攻击影响从 O(n) 降到 O(log n),攻击成本提高数千倍
面试高频追问
-
为什么树化阈值是 8,退树阈值是 6?
- 8 是泊松分布下概率约千万分之一的值,说明已经异常
- 差 2 是为了避免频繁转换的性能抖动
-
为什么不用 AVL 树?
- AVL 树平衡要求更严格,插入/删除时旋转次数更多
- 红黑树的近似平衡对查询性能影响很小,但维护成本更低
-
容量小于 64 时为什么优先扩容而不是树化?
- 扩容可以从根本上减少冲突
- 树化有额外空间开销,应该作为最后手段
常见面试变体
- "HashMap 中链表转红黑树的条件是什么?"
- "红黑树和 AVL 树有什么区别?为什么 HashMap 选红黑树?"
- "什么是 HashDoS 攻击?HashMap 如何防御?"
记忆口诀
树化条件:链表 8、容量 64,两个条件要记牢。
性能提升:链表 O(n) 太慢了,红黑树 O(log n) 救场,HashDoS 也不慌。
总结
JDK 8 引入红黑树是为了解决极端哈希冲突导致的链表查询性能退化问题,将复杂度从 O(n) 优化到 O(log n)。树化需要满足链表长度 ≥ 8 且容量 ≥ 64 两个条件。红黑树相比 AVL 树维护成本更低,同时还能有效防御 HashDoS 攻击。记住:树化是兜底方案,不是常规优化。