Java 深拷贝和浅拷贝的区别是什么?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础概念理解:面试官不仅仅是想知道 "一个是复制引用,一个是复制对象",更是想考察你是否理解 Java 对象在内存中的存储结构,以及引用类型和基本类型的区别。
-
实现方式掌握:考察你是否知道如何实现深拷贝(
Cloneable、序列化、第三方工具),以及各种方式的优缺点。 -
实战经验:实际开发中何时需要深拷贝?哪些场景下浅拷贝会导致 bug?这反映你的工程经验。
核心答案
浅拷贝只复制对象本身,内部的引用类型成员变量仍然指向原对象;深拷贝会递归复制所有层级的对象,创建完全独立的新对象。
| 对比维度 | 浅拷贝 | 深拷贝 |
|---|---|---|
| 对象本身 | ✅ 复制 | ✅ 复制 |
| 基本类型成员 | ✅ 复制值 | ✅ 复制值 |
| 引用类型成员 | ❌ 只复制引用(共享) | ✅ 递归复制对象 |
| 修改影响 | 修改引用成员会影响原对象 | 完全独立,互不影响 |
| 实现复杂度 | 简单(clone()) |
复杂(递归/序列化/工具) |
深度解析
一、内存结构对比图
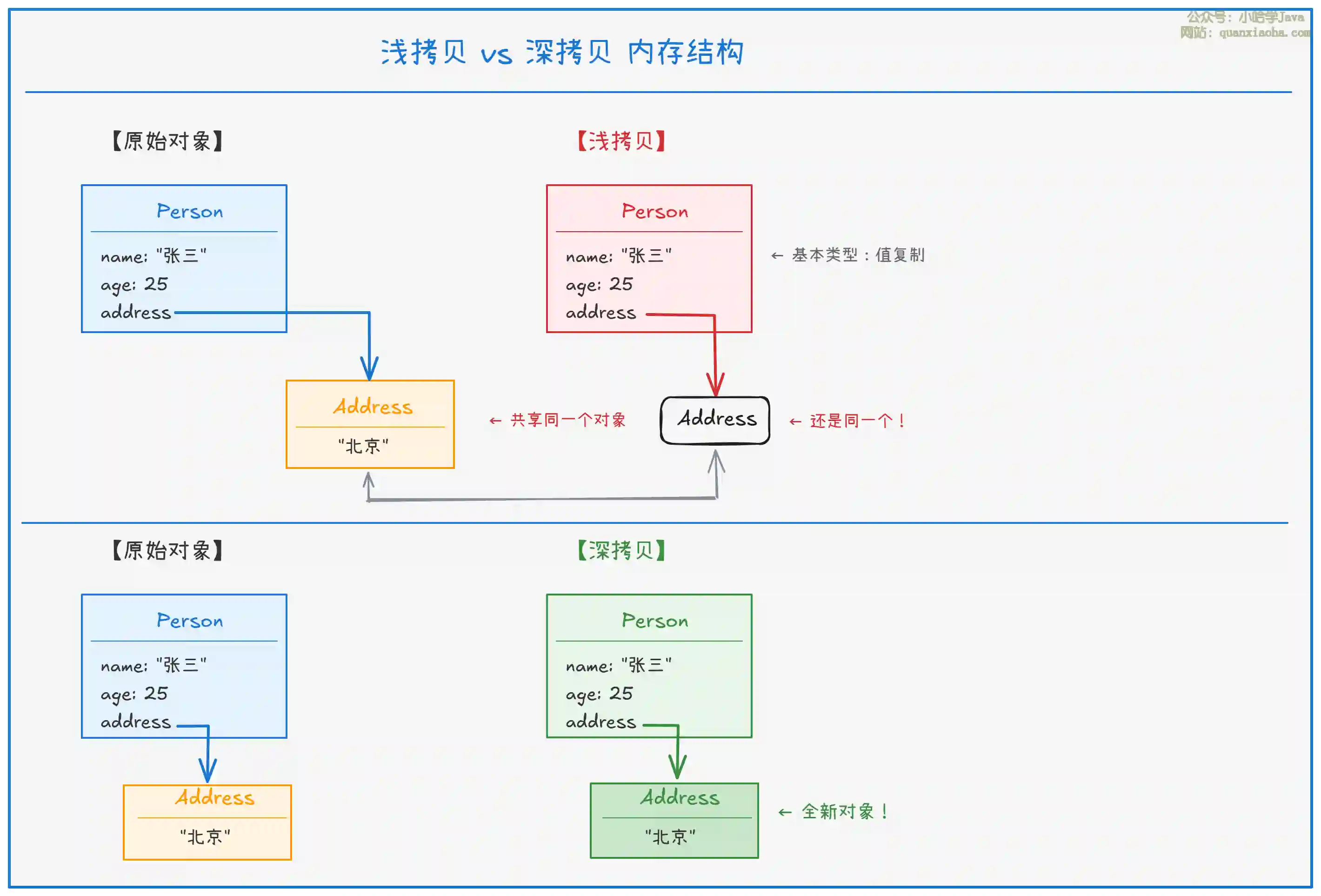
上图清晰展示了浅拷贝和深拷贝在内存中的区别。关键要点:
-
浅拷贝的 "坑":虽然
Person对象复制了一份,但address引用指向的是同一个Address对象。修改拷贝对象的地址,原对象的地址也会跟着变。 -
深拷贝的 "彻底":不仅复制
Person,连Address对象也一起复制,两个对象完全独立,互不影响。
二、代码示例:浅拷贝翻车现场
// 地址类(引用类型成员)
class Address implements Cloneable {
String city;
public Address(String city) {
this.city = city;
}
@Override
protected Address clone() throws CloneNotSupportedException {
return (Address) super.clone();
}
}
// 人员类
class Person implements Cloneable {
String name;
int age; // 基本类型
Address address; // 引用类型
public Person(String name, int age, Address address) {
this.name = name;
this.age = age;
this.address = address;
}
@Override
protected Person clone() throws CloneNotSupportedException {
return (Person) super.clone(); // 浅拷贝:只复制当前对象
}
}
// 测试浅拷贝的问题
public class ShallowCopyDemo {
public static void main(String[] args) throws Exception {
Person original = new Person("张三", 25, new Address("北京"));
// 浅拷贝
Person copy = original.clone();
// 修改拷贝对象的基本类型:不影响原对象
copy.age = 30;
System.out.println(original.age); // 输出: 25(未受影响)
// 修改拷贝对象的引用类型:原对象也被修改了!
copy.address.city = "上海";
System.out.println(original.address.city); // 输出: 上海(被影响了!)
}
}
看到了吗?修改 copy.address.city 后,original.address.city 也变成了 "上海",这就是浅拷贝的 "坑"。
三、深拷贝的三种实现方式
方式一:递归调用 clone()(手动实现)
class Person implements Cloneable {
String name;
int age;
Address address;
@Override
protected Person clone() throws CloneNotSupportedException {
Person cloned = (Person) super.clone();
cloned.address = address.clone(); // 递归克隆引用类型
return cloned;
}
}
// Address 也必须实现 Cloneable
class Address implements Cloneable {
String city;
@Override
protected Address clone() throws CloneNotSupportedException {
return (Address) super.clone();
}
}
缺点:如果对象层级很深,需要每层都实现 Cloneable 并重写 clone(),代码冗余且容易遗漏。
方式二:序列化/反序列化(推荐)
import java.io.*;
class Person implements Serializable {
String name;
int age;
Address address;
// 深拷贝方法
public Person deepCopy() {
try {
// 序列化到字节流
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
// 从字节流反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Person) ois.readObject();
} catch (Exception e) {
throw new RuntimeException("深拷贝失败", e);
}
}
}
// 所有引用类型成员都必须实现 Serializable
class Address implements Serializable {
String city;
}
优点:一行代码搞定,无需手动递归,支持任意深度的对象层级。
缺点:性能相对较差,所有类必须实现 Serializable。
方式三:第三方工具库(生产推荐)
// 使用 Hutool 工具库
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.core.clone.CloneSupport;
// 方式 1:BeanUtil 复制(浅拷贝,但可配置)
Person copy = BeanUtil.copyProperties(original, Person.class);
// 方式 2:JSON 序列化实现深拷贝
import com.fasterxml.jackson.databind.ObjectMapper;
ObjectMapper mapper = new ObjectMapper();
Person deepCopy = mapper.readValue(mapper.writeValueAsString(original), Person.class);
// 方式 3:Gson 实现深拷贝
import com.google.gson.Gson;
Gson gson = new Gson();
Person deepCopy = gson.fromJson(gson.toJson(original), Person.class);
优点:代码简洁,无需实现接口,性能和可维护性都较好。
四、三种方式对比
| 实现方式 | 代码复杂度 | 性能 | 适用场景 |
|---|---|---|---|
递归 clone() |
高(每层都要实现) | 好 | 对象层级浅且固定 |
| 序列化/反序列化 | 低(需 Serializable) |
较差 | 通用场景 |
| JSON 工具 | 低(无需接口) | 中等 | 生产推荐 |
面试高频追问
-
Java 的
Object.clone()是浅拷贝还是深拷贝?默认是浅拷贝。只复制当前对象的基本类型和引用,不会递归复制引用指向的对象。要实现深拷贝,需要在
clone()方法中手动调用引用类型成员的clone()。 -
为什么 Java 设计成默认浅拷贝?
性能考虑。深拷贝需要递归复制整个对象图,如果对象层级很深或包含循环引用,可能导致性能问题或栈溢出。浅拷贝作为默认行为更安全、可控。
-
数组的
clone()是深拷贝还是浅拷贝?对于基本类型数组是深拷贝(值复制),对于引用类型数组是浅拷贝(引用复制)。
常见面试变体
- 变体一:"如何实现一个对象的深拷贝?"
- 变体二:"
clone()方法为什么需要实现Cloneable接口?" - 变体三:"序列化实现深拷贝的原理是什么?"
记忆口诀
浅拷贝:壳子新,芯子旧,引用共享出 bug; 深拷贝:里外新,彻底分,序列化来一键搞。
总结
浅拷贝只复制对象本身,引用类型成员仍然共享;深拷贝递归复制所有层级对象,完全独立。生产环境推荐使用 JSON 工具(Jackson/Gson)或序列化方式实现深拷贝,避免手动递归 clone() 的繁琐和遗漏。