RabbitMQ 如何保证消息不丢失?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
全局视角:面试官不仅仅是想知道你听过 "消息不丢失" 这个概念,更是想知道你是否具备全链路思维——消息从生产到消费,中间会经历哪些环节,每个环节可能出什么问题。
-
实践深度:考察你是否真正在生产环境中配置过 RabbitMQ 的可靠性机制,还是只停留在理论层面。比如你是否知道开启 publisher confirm 后对性能的影响,是否了解集群模式下镜像队列的坑。
-
方案选型能力:能否根据业务场景在 "可靠性" 和 "性能" 之间做出合理权衡,而不是一股脑全开最强可靠性配置。
核心答案
消息从生产到消费,经历 三个阶段,每个阶段都可能出现丢失:
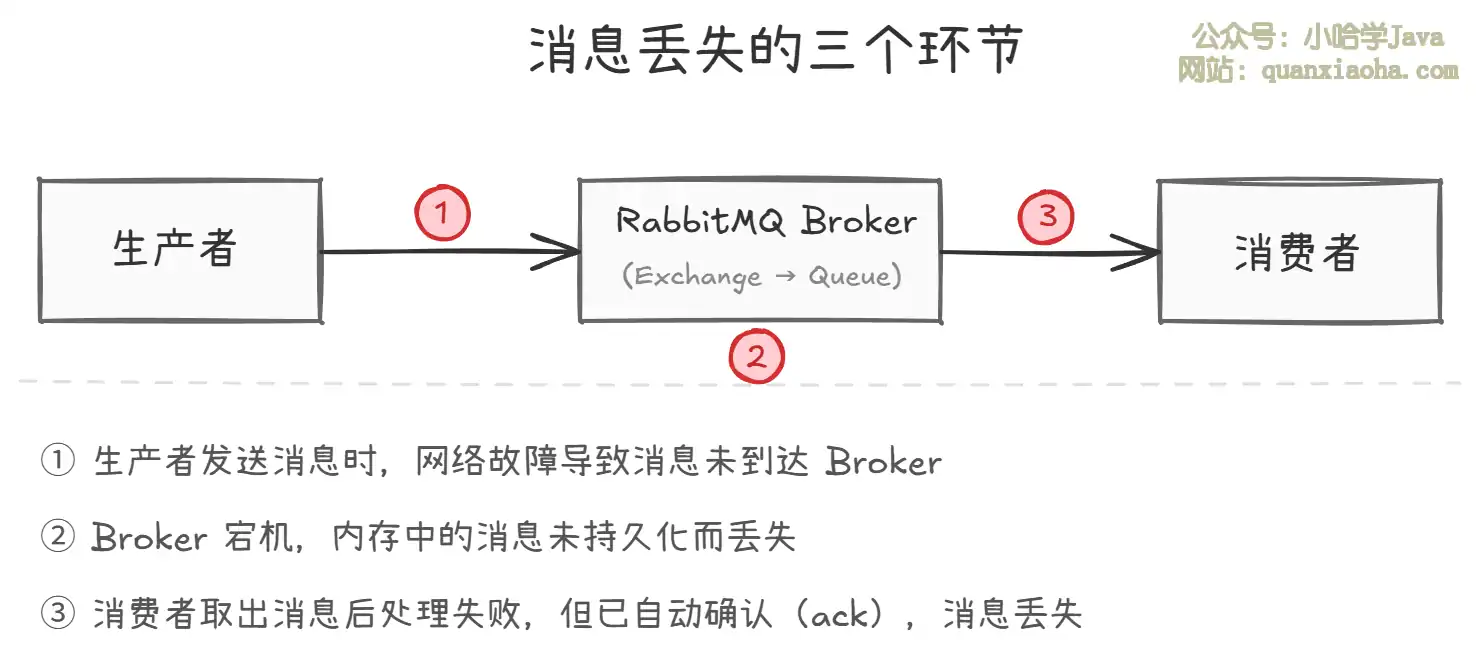
上图展示了消息在整个流转链路中可能丢失的三个关键环节。针对这三个环节,RabbitMQ 提供了对应的可靠性保障机制:
| 丢失环节 | 解决方案 | 核心机制 |
|---|---|---|
| 生产者 → Broker | 生产者确认机制 | Publisher Confirm + Return 机制 |
| Broker 自身 | 消息持久化 | Exchange、Queue、Message 三层持久化 |
| Broker → 消费者 | 消费者手动 ACK | 手动确认 + 消息重试 |
一句话结论:要保证消息不丢失,需要从 生产端确认、Broker 持久化、消费端手动 ACK 三个维度同时发力,缺一不可。
深度解析
一、生产者确认机制(Publisher Confirm)
生产者发送消息后,默认是 "发完就不管了"(fire-and-forget)。如果网络抖动或 Broker 异常,消息就悄悄丢了,生产者完全不知道。
RabbitMQ 提供了两种确认机制:
1. Publisher Confirm(确认消息到达 Broker)
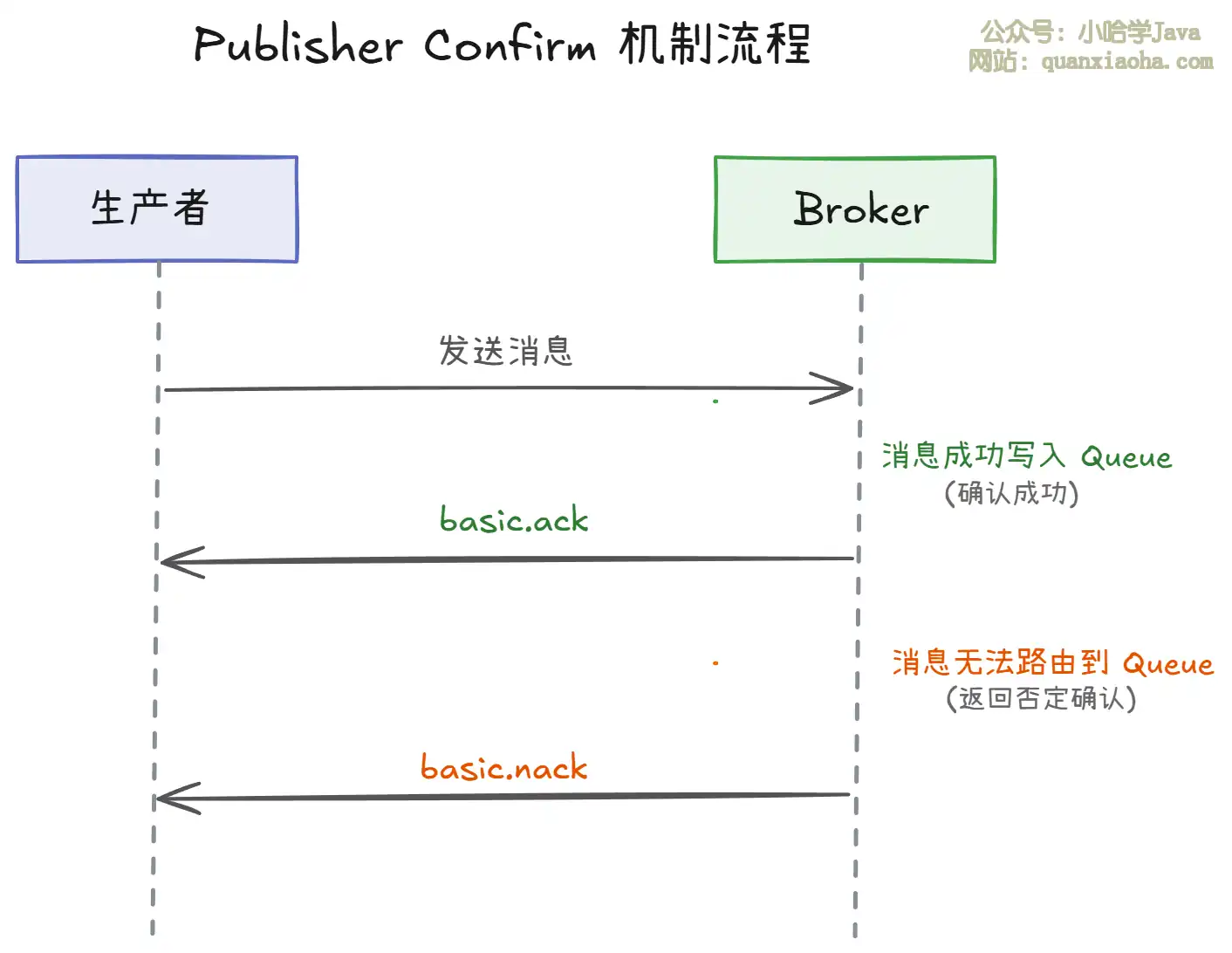
上图展示了 Publisher Confirm 机制的交互流程。核心逻辑是:
- 成功路由:消息成功写入 Queue 后,Broker 向生产者返回
basic.ack,表示 "我收到了" - 路由失败:消息无法路由到任何 Queue 时,Broker 返回
basic.nack,表示 "消息没能投递成功"
Spring Boot 配置示例:
spring:
rabbitmq:
publisher-confirm-type: correlated # 开启发布确认,异步回调
publisher-returns: true # 开启退回模式
@Configuration
public class RabbitConfig {
/**
* 消息到达 Exchange 但无法路由到 Queue 时的回调
* (比如 routing key 写错了,Exchange 找不到匹配的 Queue)
*/
@Bean
public RabbitTemplate.ReturnsCallback returnsCallback() {
return (returned) -> {
log.error("消息路由失败,exchange={}, routingKey={}, msg={}",
returned.getExchange(),
returned.getRoutingKey(),
new String(returned.getMessage().getBody()));
// 可以在这里做重试、记录日志、写入死信队列等
};
}
/**
* 消息确认回调(无论成功或失败都会触发)
*/
@Bean
public RabbitTemplate.ConfirmCallback confirmCallback() {
return (correlationData, ack, cause) -> {
if (ack) {
log.info("消息确认成功");
} else {
log.error("消息确认失败,原因:{}", cause);
// 重发消息或记录到数据库,后续补偿
}
};
}
}
2. 退回模式(Return Mechanism)
当消息成功到达 Exchange,但 Exchange 无法将消息路由到任何 Queue 时,可以通过 Return 机制将消息退回给生产者。注意它和 Confirm 的区别:
| 机制 | 触发条件 | 说明 |
|---|---|---|
| Publisher Confirm | 每条消息都会触发 | 不管消息是否成功路由到 Queue,都会回调 |
| Return | 仅路由失败时触发 | 消息到达了 Exchange 但没找到匹配的 Queue |
二、Broker 消息持久化(Persistence)
即使生产者确认消息发送成功了,如果 RabbitMQ Broker 突然宕机,存在内存中的消息还是会丢失。所以必须开启持久化,让消息写入磁盘。
持久化需要 三个层面 同时配置:
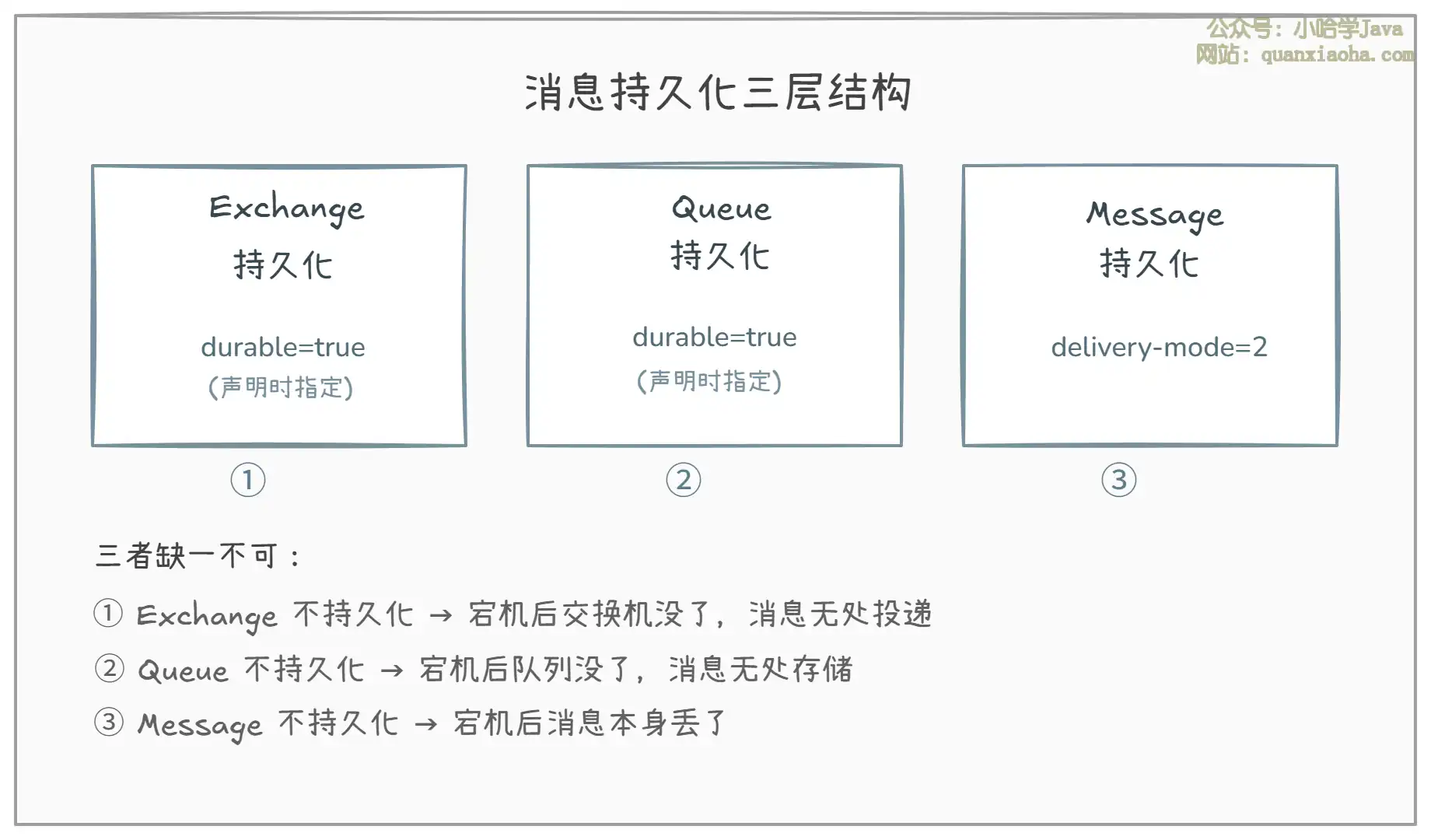
上图展示了消息持久化的三层结构。下面逐一说明:
- Exchange 持久化:声明 Exchange 时设置
durable = true。这样 Broker 重启后 Exchange 还在,否则 Exchange 直接消失,后续消息无法路由 - Queue 持久化:声明 Queue 时同样设置
durable = true。Queue 是消息的实际存储容器,不持久化的话,Broker 重启后整个队列连同消息一起消失 - Message 持久化:发送消息时设置
deliveryMode = 2,表示消息需要写入磁盘。Spring Boot 中默认就是持久化消息
代码示例:
// 1. 声明持久化的 Exchange
@Bean
public DirectExchange durableExchange() {
return ExchangeBuilder.directExchange("order.exchange")
.durable(true) // 持久化
.build();
}
// 2. 声明持久化的 Queue
@Bean
public Queue durableQueue() {
return QueueBuilder.durable("order.queue")
.build();
}
// 3. 发送持久化消息(Spring Boot 默认持久化,无需额外配置)
rabbitTemplate.convertAndSend("order.exchange", "order.create", "订单消息");
注意:持久化不是万无一失的。RabbitMQ 不会每条消息都立即
fsync到磁盘,而是先写入操作系统缓存(Page Cache),再异步刷盘。如果 broker 在刷盘前宕机,理论上仍有极小概率丢失。如果对可靠性要求极高,可以使用 Quorum Queue(仲裁队列),这是 RabbitMQ 3.10+ 引入的基于 Raft 协议的队列类型。
三、消费者手动 ACK(Manual Acknowledgment)
默认情况下,RabbitMQ 的消费者是 自动确认 模式:消息一推送给消费者,Broker 立刻将消息标记为 "已消费" 并删除。如果消费者这时候处理消息失败了(抛异常、宕机),消息就真的丢了——Broker 以为你处理完了。
解决方案:开启 手动确认,消费者处理完业务逻辑后,主动告诉 Broker "我处理完了"。
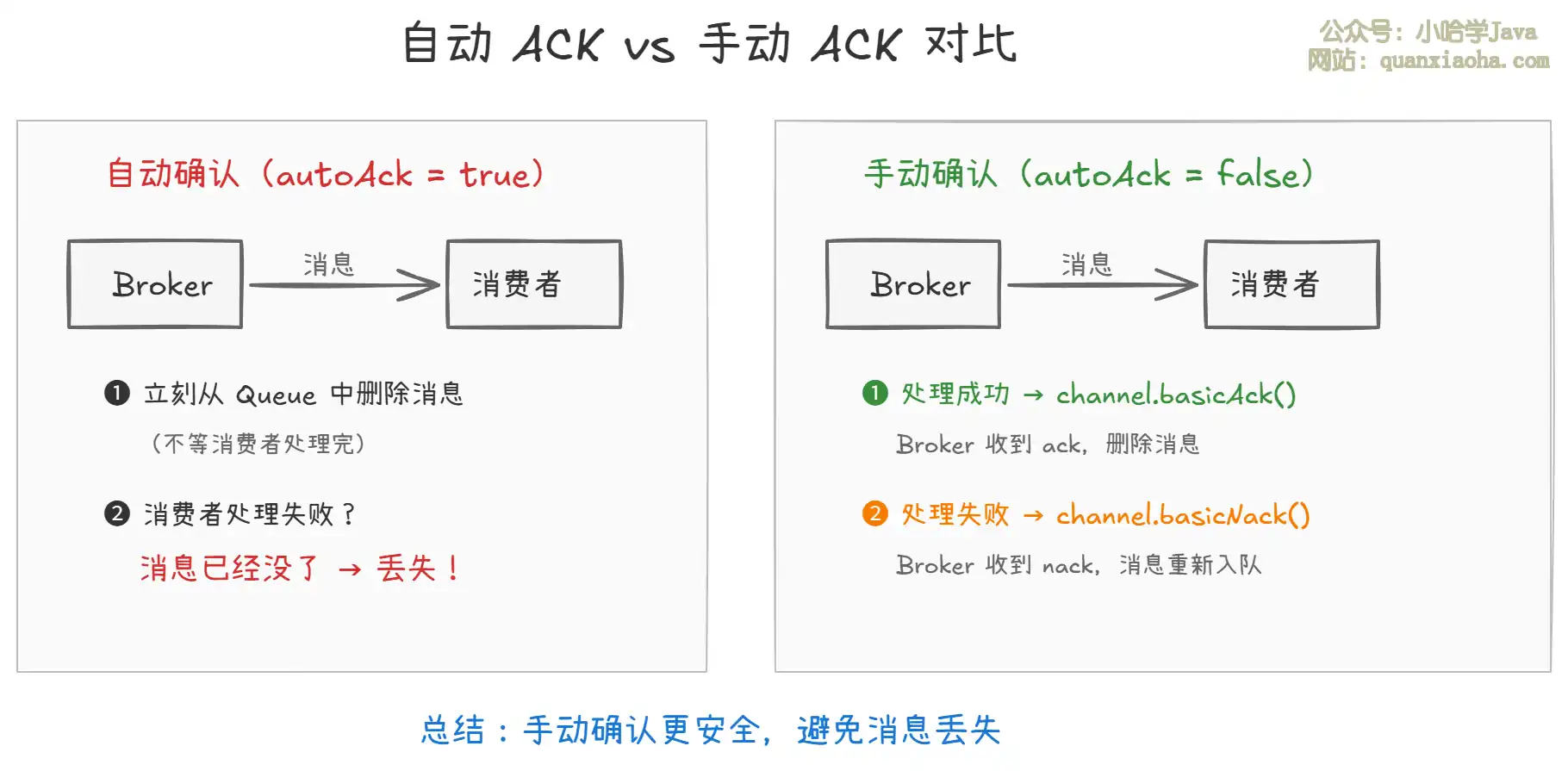
上图对比了自动确认和手动确认的差异。手动确认模式下,消息的命运由消费者掌握:成功了确认删除,失败了让消息重新入队。
Spring Boot 配置:
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual # 开启手动确认
prefetch: 1 # 每次只拉取 1 条,处理完再拉下一条
消费者代码:
@RabbitListener(queues = "order.queue")
public void handleMessage(String message, Channel channel,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag) throws Exception {
try {
// 处理业务逻辑
orderService.createOrder(message);
// 业务处理成功,手动确认
channel.basicAck(deliveryTag, false);
log.info("消息处理成功:{}", message);
} catch (Exception e) {
log.error("消息处理失败:{}", message, e);
// 处理失败,拒绝消息并重新入队
// 第三个参数 requeue = true 表示重新放回队列
channel.basicNack(deliveryTag, false, true);
}
}
注意:如果消费者一直处理失败,消息会不断重新入队,形成 "无限重试" 死循环。生产环境中通常的做法是:设置最大重试次数,超过后转入 死信队列(DLX),由专门的服务处理异常消息。
四、高可用集群补充
除了以上三个核心环节,在生产环境中还需要考虑 Broker 的高可用:

上图展示了 RabbitMQ 三种集群模式在消息可靠性方面的差异:
- 普通集群:Queue 数据只存在于单个节点,宕机即丢失,不适合可靠性要求高的场景
- 镜像队列:通过主从复制实现高可用,但同步复制的性能开销较大,且已标记为 deprecated
- 仲裁队列:基于 Raft 协议的多数派写入机制,是官方推荐的新方案,兼顾了数据一致性和性能
五、可靠性与性能的权衡
全部开启最强可靠性配置后,RabbitMQ 的吞吐量会明显下降。实际生产中需要根据业务场景做取舍:
| 场景 | 建议配置 | 原因 |
|---|---|---|
| 金融支付、订单核心链路 | 全部开启(Confirm + 持久化 + 手动 ACK + Quorum Queue) | 消息绝对不能丢,性能可以牺牲 |
| 普通业务通知、日志采集 | 仅持久化 + 手动 ACK | 允许极少量的消息丢失,换取更高吞吐 |
| 实时数据、监控指标 | 仅手动 ACK | 追求极致性能,历史数据丢了也无所谓 |
面试高频追问
-
追问一:开启 Confirm 机制对性能影响有多大?
同步确认模式下,每条消息都要等 Broker 回复,吞吐量可能降低 5-10 倍。建议使用异步确认(
confirm-type: correlated),批量发送后通过回调处理结果,性能损耗可控制在 20%-30% 左右。 -
追问二:消息一直消费失败怎么办?
配合 死信队列(DLX) 使用:设置消息的 TTL 和最大重试次数,超过后自动转入死信队列。再由专门的消费者对死信消息进行人工处理或告警。
-
追问三:Quorum Queue 和经典队列有什么区别?
Quorum Queue 基于 Raft 协议实现,消息写入需要多数节点确认,天然保证了数据一致性。经典镜像队列是异步复制,存在主从数据不一致的风险。官方推荐新项目使用 Quorum Queue。
-
追问四:如何保证消息的顺序消费?
单个 Queue 中的消息本身是有序的,问题出在多个消费者并发消费。解决方案:将需要保证顺序的消息通过相同的 routing key 路由到同一个 Queue,且该 Queue 只有一个消费者。
常见面试变体
- "RabbitMQ 的消息可靠性如何保证?"
- "RabbitMQ 生产者如何确认消息发送成功?"
- "RabbitMQ 消费者宕机了,消息会丢吗?"
- "RabbitMQ 持久化机制是怎样的?"
记忆口诀
三阶段防丢失:生产端 Confirm 确认送达、Broker 端三层持久化(Exchange + Queue + Message)、消费端手动 ACK 确认处理完。
口诀:"发确认、存磁盘、手动签" —— 发出去要确认,存下来要落盘,消费完要手动签收。
总结
RabbitMQ 保证消息不丢失需要从 生产者确认、Broker 持久化、消费者手动 ACK 三个环节同时入手。生产者通过 Publisher Confirm 和 Return 机制确保消息成功到达 Broker;Broker 通过 Exchange、Queue、Message 三层持久化确保宕机不丢数据;消费者通过手动 ACK 确保处理失败时消息能重新入队。生产环境中还需配合 Quorum Queue 实现集群高可用,并通过死信队列兜底异常消息。