MySQL 如何进行 SQL 调优?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
系统性思维:面试官不仅仅想知道你会不会加索引,更想考察你是否具备从"发现问题 → 定位问题 → 解决问题 → 验证效果"的完整调优思路。
-
工具掌握度:考察你是否熟练使用
EXPLAIN、SHOW PROFILE、慢查询日志等调优工具,能否从执行计划中识别性能瓶颈。 -
原理理解深度:是否理解索引的数据结构(B+ 树)、索引失效场景、MySQL 优化器的工作机制,而非只会照搬网上八股文。
核心答案
MySQL SQL 调优是一个系统化工程,核心流程如下:
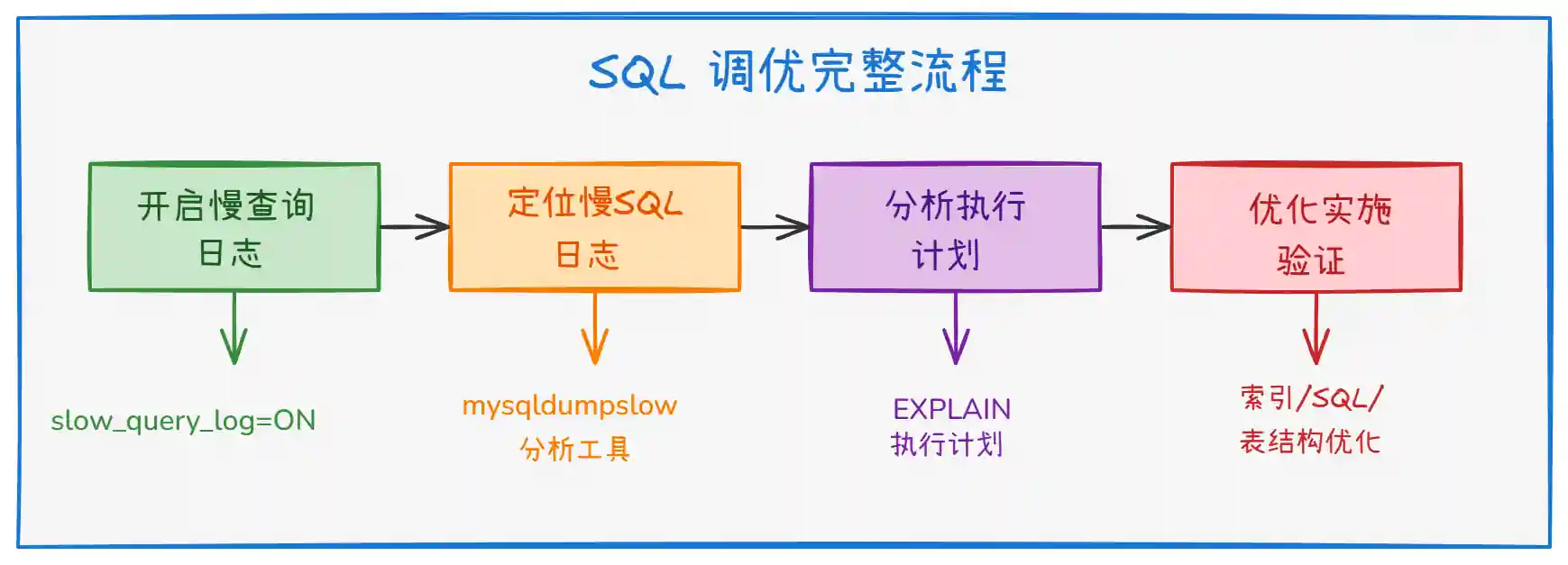
上图展示了 SQL 调优的完整流程。整体分为四个阶段:
-
阶段一(开启监控):通过配置
slow_query_log=ON开启慢查询日志,设置long_query_time阈值(默认 10 秒,生产建议 1-3 秒),为后续分析提供数据基础。 -
阶段二(定位问题):使用
mysqldumpslow工具分析慢查询日志,按执行时间、执行次数排序,快速锁定最需要优化的 SQL。 -
阶段三(分析原因):对目标 SQL 执行
EXPLAIN查看执行计划,重点关注type、key、rows、Extra字段,判断是否走索引、扫描行数是否合理。 -
阶段四(优化验证):根据分析结果进行索引优化、SQL 改写、表结构调整,然后再次执行
EXPLAIN验证效果。
一句话总结:调优 = 慢日志定位 + EXPLAIN 分析 + 索引优化 + SQL 改写。
深度解析
一、定位慢 SQL:慢查询日志
首先需要开启慢查询日志,记录执行时间超过阈值的 SQL:
-- 查看慢查询日志配置
SHOW VARIABLES LIKE '%slow_query%';
SHOW VARIABLES LIKE 'long_query_time';
-- 开启慢查询日志(临时生效)
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 2; -- 超过 2 秒记录
SET GLOBAL log_queries_not_using_indexes = 'ON'; -- 记录未走索引的 SQL
-- 永久生效需修改 my.cnf
[mysqld]
slow_query_log = 1
long_query_time = 2
slow_query_log_file = /var/log/mysql/slow.log
使用 mysqldumpslow 工具分析慢日志:
# 按查询时间排序,显示前 10 条
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 按查询次数排序
mysqldumpslow -s c -t 10 /var/log/mysql/slow.log
二、分析执行计划:EXPLAIN 详解
使用 EXPLAIN 或 EXPLAIN ANALYZE(MySQL 8.0+)查看 SQL 执行计划:
EXPLAIN SELECT * FROM orders WHERE user_id = 100 AND status = 'PAID';
关键字段解读:
| 字段 | 含义 | 关注点 |
|---|---|---|
type |
访问类型(效率从高到低) | system > const > eq_ref > ref > range > index > ALL(全表扫描,需优化) |
key |
实际使用的索引 | 是否命中预期索引 |
key_len |
使用的索引长度 | 越短越好,判断联合索引使用情况 |
rows |
预估扫描行数 | 越少越好 |
Extra |
额外信息 | Using filesort(文件排序)、Using temporary(临时表)需要关注 |
type 类型效率对比:

上图展示了 EXPLAIN 中 type 字段的访问类型,从左到右效率递减:
-
system/const:最高效,主键或唯一索引查询,最多返回一行数据。 -
eq_ref:唯一索引关联查询,每个索引键值对应一行。 -
ref:非唯一索引查询,可能返回多行。 -
range:索引范围扫描,如BETWEEN、>、<、IN等操作。 -
index:遍历整个索引树,比ALL稍好(索引比数据文件小)。 -
ALL:全表扫描,性能最差,需要重点关注优化。
三、索引优化:最常见的调优手段
1. 索引创建原则
-- 为高频查询条件创建索引
CREATE INDEX idx_user_status ON orders(user_id, status);
-- 联合索引遵循"最左前缀原则"
-- 索引 (a, b, c) 可支持:a | a,b | a,b,c 的查询
-- 无法支持:b | c | b,c 的查询(缺少最左列)
2. 索引失效场景
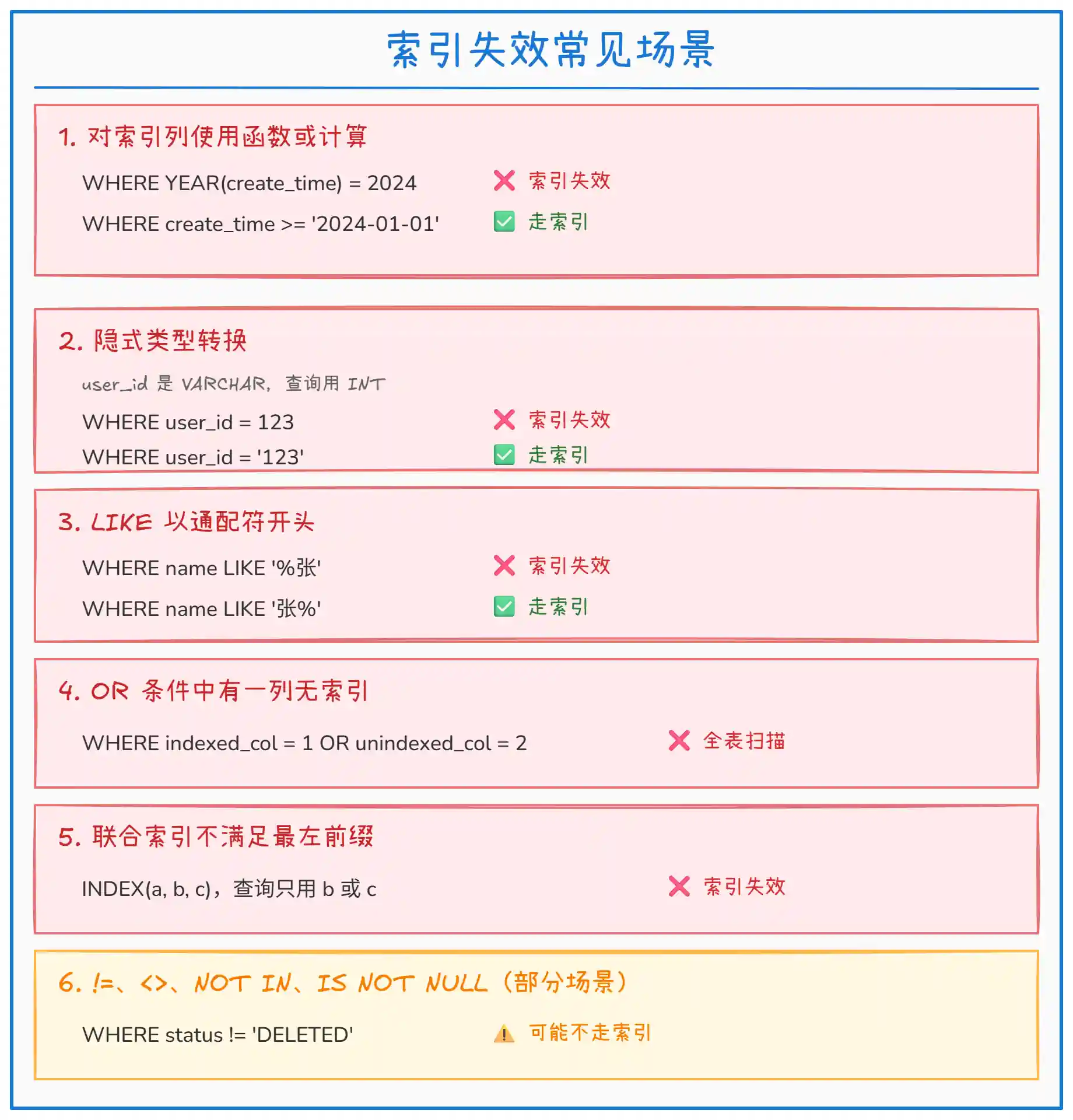
上图总结了索引失效的六大常见场景。每个场景都需要特别注意:
-
函数/计算:索引列经过函数处理后,B+ 树的有序性被破坏,无法利用索引。
-
隐式转换:MySQL 会将字符串转数字进行比较,相当于对列做了函数操作。
-
LIKE 前缀通配:
%xxx无法利用 B+ 树的有序性,只能全扫描。 -
OR 条件:只要有一个条件列没有索引,整体就会退化为全表扫描。
-
最左前缀:联合索引按照定义顺序构建,跳过前面的列无法利用索引。
-
否定条件:优化器可能认为返回数据量过大,直接全表扫描更高效。
四、SQL 语句优化技巧
1. 避免 SELECT *
-- ❌ 不推荐:查询所有列,增加 IO 和网络开销
SELECT * FROM orders WHERE user_id = 100;
-- ✅ 推荐:只查询需要的列
SELECT order_id, amount, status FROM orders WHERE user_id = 100;
2. 优化分页查询
-- ❌ 深分页性能差:需要扫描前 100000 条
SELECT * FROM orders LIMIT 100000, 10;
-- ✅ 方案一:基于游标分页(需要连续 ID)
SELECT * FROM orders WHERE id > 100000 LIMIT 10;
-- ✅ 方案二:延迟关联(先查 ID,再关联)
SELECT o.* FROM orders o
INNER JOIN (SELECT id FROM orders LIMIT 100000, 10) t
ON o.id = t.id;
3. 优化 COUNT 查询
-- ❌ COUNT(*) 扫描全表
SELECT COUNT(*) FROM orders WHERE status = 'PAID';
-- ✅ 维护计数表(适合高频统计场景)
CREATE TABLE order_stats (status VARCHAR(20), count INT);
-- 业务变更时同步更新计数
4. 优化 ORDER BY
-- ❌ filesort:排序字段未走索引
SELECT * FROM orders WHERE user_id = 100 ORDER BY create_time;
-- ✅ 创建联合索引,覆盖 WHERE + ORDER BY
CREATE INDEX idx_user_time ON orders(user_id, create_time);
五、表结构优化
1. 选择合适的数据类型
| 场景 | 推荐类型 | 原因 |
|---|---|---|
| 主键 ID | BIGINT 或 BIGINT UNSIGNED |
避免溢出,预留空间 |
| 状态字段 | TINYINT |
1 字节存储,配合枚举含义 |
| 字符串 | VARCHAR(N) |
变长存储,N 不宜过大 |
| 时间 | DATETIME 或 TIMESTAMP |
根据时区需求选择 |
| 大文本 | 独立表 + 外键 | 避免影响主表性能 |
2. 适度反范式设计
-- 范式设计:订单表只存 user_id,查询时 JOIN 用户表
SELECT o.*, u.name FROM orders o JOIN users u ON o.user_id = u.id;
-- 反范式设计:订单表冗余 user_name(适合读多写少场景)
-- 优点:减少 JOIN,提升查询性能
-- 缺点:用户改名需同步更新订单表
六、高级调优工具
1. SHOW PROFILE(查询性能剖析)
-- 开启 profiling
SET profiling = 1;
-- 执行 SQL
SELECT * FROM orders WHERE user_id = 100;
-- 查看性能详情
SHOW PROFILE;
SHOW PROFILE FOR QUERY 1; -- 查看具体 SQL 的各阶段耗时
2. Performance Schema(MySQL 5.7+)
-- 查看哪些 SQL 执行时间最长
SELECT * FROM performance_schema.events_statements_summary_by_digest
ORDER BY SUM_TIMER_WAIT DESC LIMIT 10;
3. EXPLAIN ANALYZE(MySQL 8.0+)
-- 真实执行 SQL 并显示各步骤实际耗时
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 100;
面试高频追问
-
联合索引的"最左前缀原则"是什么?为什么这样设计?
- 联合索引按照定义顺序构建 B+ 树,先按第一列排序,第一列相同再按第二列排序,以此类推。查询时必须从最左列开始匹配才能利用索引的有序性。
-
什么情况下应该创建索引?什么情况下不应该?
- 应创建:高频查询的 WHERE 条件、JOIN 关联列、ORDER BY/GROUP BY 列、区分度高(基数大)的字段。
- 不应创建:区分度低(如性别、状态只有几个值)、频繁更新的列、数据量小的表。
-
如何优化大批量数据导入?
- 临时关闭索引(
ALTER TABLE ... DISABLE KEYS)、使用批量 INSERT(一条语句插入多行)、关闭唯一性检查、增大innodb_buffer_pool_size。
- 临时关闭索引(
常见面试变体
- "EXPLAIN 执行计划中 type 字段有哪些值?分别代表什么?"
- "什么情况下索引会失效?举几个例子。"
- "如何优化 MySQL 的深分页问题?"
- "慢查询日志怎么开启?如何分析?"
记忆口诀
调优四步法:慢日志定位 → EXPLAIN 分析 → 索引优化 → 验证效果
索引失效六宗罪:函数计算、隐式转换、左模糊、OR 缺索引、最左缺失、否定条件
type 效率排序:system > const > eq_ref > ref > range > index > ALL
总结
MySQL SQL 调优的核心思路是:通过慢查询日志定位问题 SQL,使用 EXPLAIN 分析执行计划找出性能瓶颈(全表扫描、文件排序、临时表等),然后针对性地进行索引优化(遵循最左前缀、避免索引失效场景)、SQL 改写(避免 SELECT *、优化深分页)、表结构调整(选择合适字段类型、适度反范式)。调优是一个持续迭代的过程,需要结合业务场景和数据特点综合考量。