MySQL 慢查询怎么排查?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道慢查询日志怎么开,更是想知道你是否掌握从发现问题、定位问题、分析问题到解决问题的完整排查链路。
-
性能优化意识:考察你是否熟悉
EXPLAIN执行计划的各项指标,能否根据执行计划判断 SQL 的性能瓶颈(全表扫描、索引失效、临时表等)。 -
生产实践经验:能否结合实际场景讲述慢查询优化的完整案例,包括如何定位、如何分析、如何优化、优化效果如何验证。
核心答案
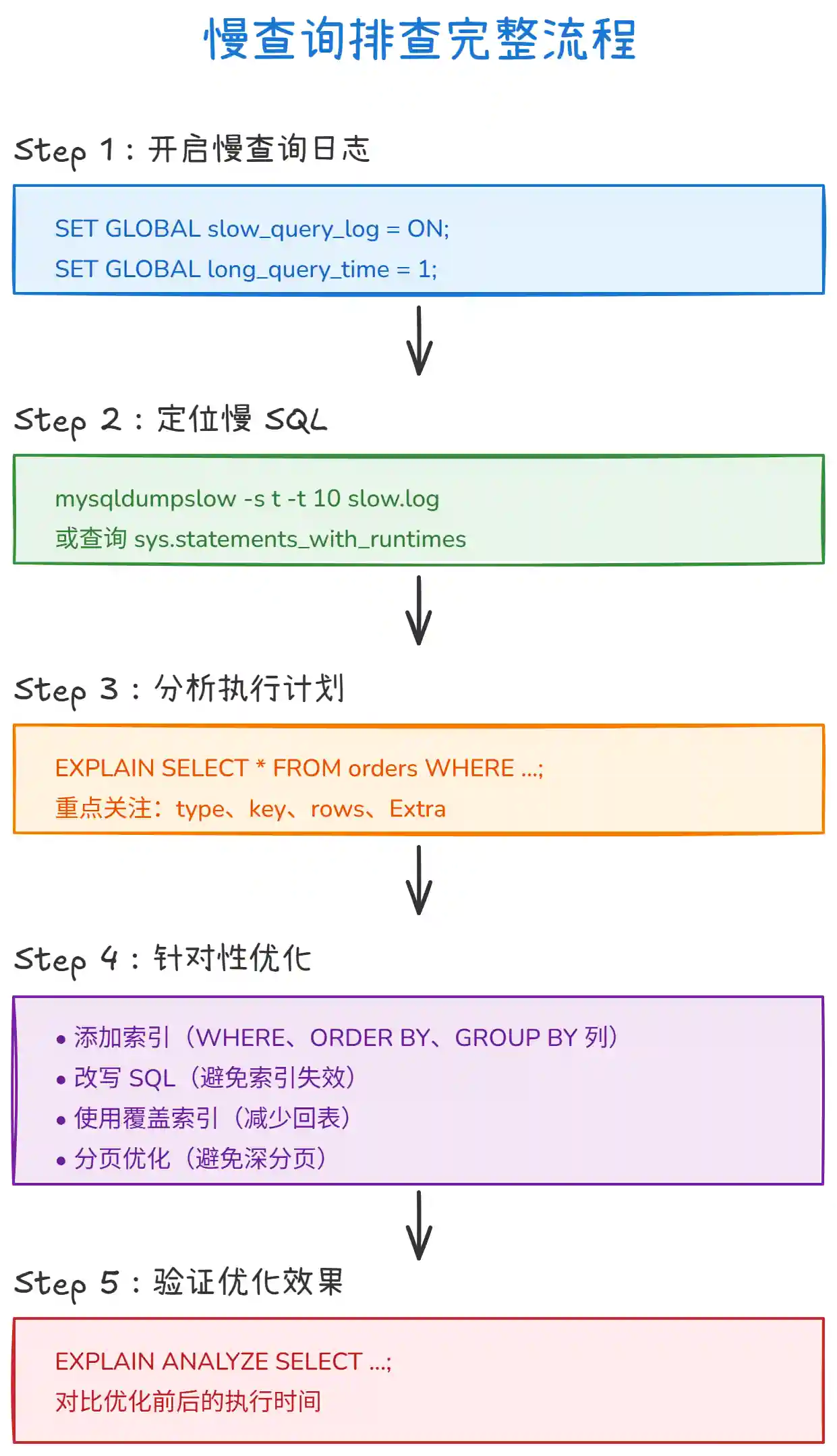
MySQL 慢查询排查遵循 "发现 → 定位 → 分析 → 优化 → 验证" 五步法:
- 步骤①:开启慢查询日志,捕获慢 SQL。
- 步骤②:查看慢查询日志,定位问题 SQL。
- 步骤③:使用
EXPLAIN分析执行计划。 - 步骤④:根据分析结果优化(索引/SQL 改写)。
- 步骤⑤:验证优化效果,对比执行时间。
一句话总结:开启慢查询日志定位问题 SQL,用 EXPLAIN 分析执行计划,针对性优化索引或改写 SQL,最后验证效果。
深度解析
一、开启慢查询日志
-- 1. 查看慢查询日志配置
SHOW VARIABLES LIKE '%slow_query%';
-- slow_query_log: OFF/ON(是否开启)
-- slow_query_log_file: 慢查询日志文件路径
-- 2. 查看慢查询阈值(默认 10 秒)
SHOW VARIABLES LIKE 'long_query_time';
-- 3. 动态开启慢查询日志(重启失效)
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 设置为 1 秒
-- 4. 是否记录没走索引的 SQL
SHOW VARIABLES LIKE 'log_queries_not_using_indexes';
SET GLOBAL log_queries_not_using_indexes = ON;
配置文件方式(永久生效):
# my.cnf
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 1
log_queries_not_using_indexes = ON
关键参数说明:
slow_query_log:是否开启慢查询日志long_query_time:慢查询阈值,超过该时间的 SQL 会被记录(单位:秒,可精确到微秒)log_queries_not_using_indexes:是否记录没走索引的 SQL(即使很快)min_examined_row_limit:扫描行数少于此值不记录(避免记录简单查询)
二、定位慢查询 SQL

常用命令:
# 使用 mysqldumpslow 分析慢查询日志
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 输出示例
Count: 5 Time=10.23s Lock=0.00s Rows=1000.0
SELECT * FROM orders WHERE create_time > '2024-01-01'
-- MySQL 5.7+ 使用 sys 库查询慢 SQL
SELECT
query_id,
LEFT(query, 100) AS query_preview,
exec_count,
avg_latency / 1000000 AS avg_ms,
rows_examined,
rows_sent
FROM sys.statements_with_runtimes_in_95th_percentile
ORDER BY avg_latency DESC
LIMIT 10;
三、使用 EXPLAIN 分析执行计划
-- 基本用法
EXPLAIN SELECT * FROM orders WHERE user_id = 100;
-- MySQL 8.0+ 推荐使用 EXPLAIN ANALYZE(显示实际执行时间)
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 100;
EXPLAIN 输出字段详解:

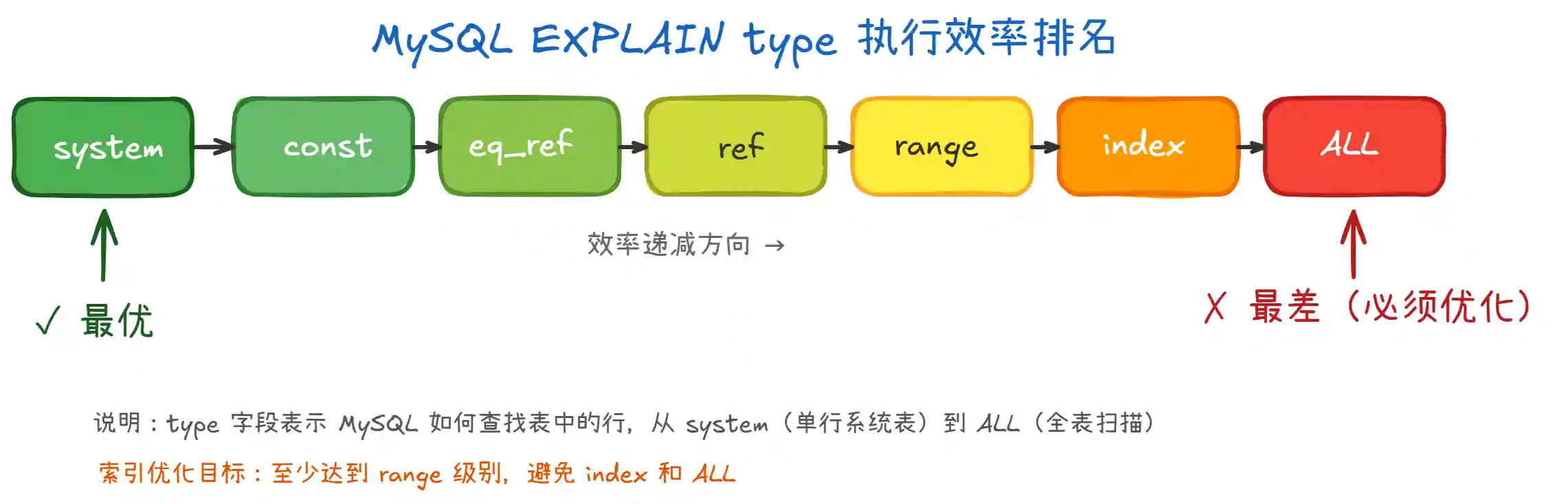
type 访问类型性能排序:
实战案例分析:
-- 案例 1:全表扫描(需要优化)
EXPLAIN SELECT * FROM orders WHERE amount > 100;
-- type: ALL, key: NULL, rows: 1000000
-- 优化:给 amount 加索引
-- 案例 2:索引范围扫描(较好)
EXPLAIN SELECT * FROM orders WHERE user_id = 100;
-- type: ref, key: idx_user_id, rows: 50
-- 已经走了索引
-- 案例 3:覆盖索引(最优)
EXPLAIN SELECT user_id, status FROM orders WHERE user_id = 100;
-- type: ref, key: idx_user_id, Extra: Using index
-- 不需要回表,性能最佳
四、常见慢查询场景与优化

优化实战示例:
-- 优化前:全表扫描 + 文件排序
EXPLAIN SELECT * FROM orders
WHERE status = 1
ORDER BY create_time DESC
LIMIT 100;
-- type: ALL, Extra: Using where; Using filesort
-- 优化:添加联合索引
CREATE INDEX idx_status_create_time ON orders(status, create_time);
-- 优化后:索引范围扫描 + 索引排序
-- type: ref, Extra: Using index condition
-- 优化前:索引失效(函数操作)
EXPLAIN SELECT * FROM orders
WHERE YEAR(create_time) = 2024;
-- type: ALL(索引失效!)
-- 优化后:改写为范围查询
EXPLAIN SELECT * FROM orders
WHERE create_time >= '2024-01-01'
AND create_time < '2025-01-01';
-- type: range, key: idx_create_time
五、排查流程完整示例
面试高频追问
-
EXPLAIN 中 type 有哪些类型?从好到差排序?
system>const>eq_ref>ref>range>index>ALL- 看到
ALL必须优化(全表扫描)
-
什么情况会导致索引失效?
LIKE左模糊:WHERE name LIKE '%abc'- 对索引列使用函数:
WHERE YEAR(create_time) = 2024 - 隐式类型转换:
phone是 VARCHAR,但WHERE phone = 13800138000 OR条件中有非索引列!=、<>、NOT IN(不一定,看优化器)- 联合索引不满足最左前缀
-
什么是覆盖索引?有什么好处?
- 查询的列都在索引中,不需要回表查聚簇索引
EXPLAIN的Extra显示Using index- 减少一次 B+Tree 查找,降低 I/O
-
如何优化深分页问题?
-- 优化前:越往后越慢 SELECT * FROM orders LIMIT 1000000, 10; -- 优化后:使用子查询 + 覆盖索引 SELECT * FROM orders a JOIN (SELECT id FROM orders LIMIT 1000000, 10) b ON a.id = b.id;
常见面试变体
- "如何定位 MySQL 的性能瓶颈?"
- "EXPLAIN 的 Extra 字段有哪些值?分别代表什么?"
- "索引在什么情况下会失效?"
- "如何优化一条慢 SQL?"
记忆口诀
慢查日志先开启,阈值设置要合理; EXPLAIN 看计划,type 从好到差记; ALL 全扫必须改,filesort 要注意; 索引失效常排查,覆盖索引最给力。
总结
MySQL 慢查询排查五步法:开启慢查询日志 → 定位问题 SQL → EXPLAIN 分析执行计划 → 针对性优化(加索引/改写 SQL)→ 验证效果。核心是看 EXPLAIN 的 type(避免 ALL)、key(确认走索引)、rows(扫描行数)、Extra(关注 Using filesort 和 Using temporary)。优化手段包括添加索引、避免索引失效、使用覆盖索引、改写 SQL 等。