什么是 Redis 的数据分片?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
概念理解:面试官不仅仅是想知道 "数据分片" 这个名词,更是想知道你是否清楚 为什么需要分片(单机瓶颈:内存、QPS、带宽),以及分片的核心思想(把数据分散到多个节点)。
-
方案掌握度:考察你是否了解 Redis 数据分片的 多种实现方式(客户端分片、代理分片、服务端分片),以及各自的优缺点和适用场景。
-
原理深度:能否说清楚 Redis Cluster 的 Hash Slot 路由机制(
CRC16(key) % 16384),以及MOVED/ASK重定向、Hash Tag 等核心机制。
核心答案
Redis 数据分片是指 将数据按照一定规则分散存储到多个 Redis 节点上,从而突破单节点的内存、QPS 和网络带宽限制。
| 分片方式 | 代表方案 | 路由位置 | 优点 | 缺点 |
|---|---|---|---|---|
| 客户端分片 | ShardedJedis / 自定义 | 客户端 | 无代理,性能高 | 节点变更需重启 |
| 代理分片 | Twemproxy / Codis | 代理层 | 对客户端透明 | 多一跳,代理是瓶颈 |
| 服务端分片 | Redis Cluster | 服务端 | 官方方案,自动管理 | 迁移成本高,有限制 |
一句话结论:数据分片是解决 Redis 单机瓶颈的关键手段。早期用客户端分片或 Twemproxy/Codis 等代理方案,现在 Redis Cluster(服务端分片)是主流方案,通过 16384 个 Hash Slot 实现自动分片和故障转移。
深度解析
一、为什么需要数据分片?

上图说明了为什么需要数据分片:
- 内存上限:单台 Redis 通常只能装几十 GB 数据,数据量超过单机内存时就装不下了。
- QPS 上限:单节点大约能承受 8~10 万 QPS,超过这个量级单机扛不住。
- 网络带宽:单节点网卡带宽有限,大 Value 场景下网络可能先成为瓶颈。
- 解决思路:把数据按照规则分散到多个节点上,每个节点只存一部分数据,从而实现 内存、QPS、带宽的线性扩展。
二、分片方式一:客户端分片
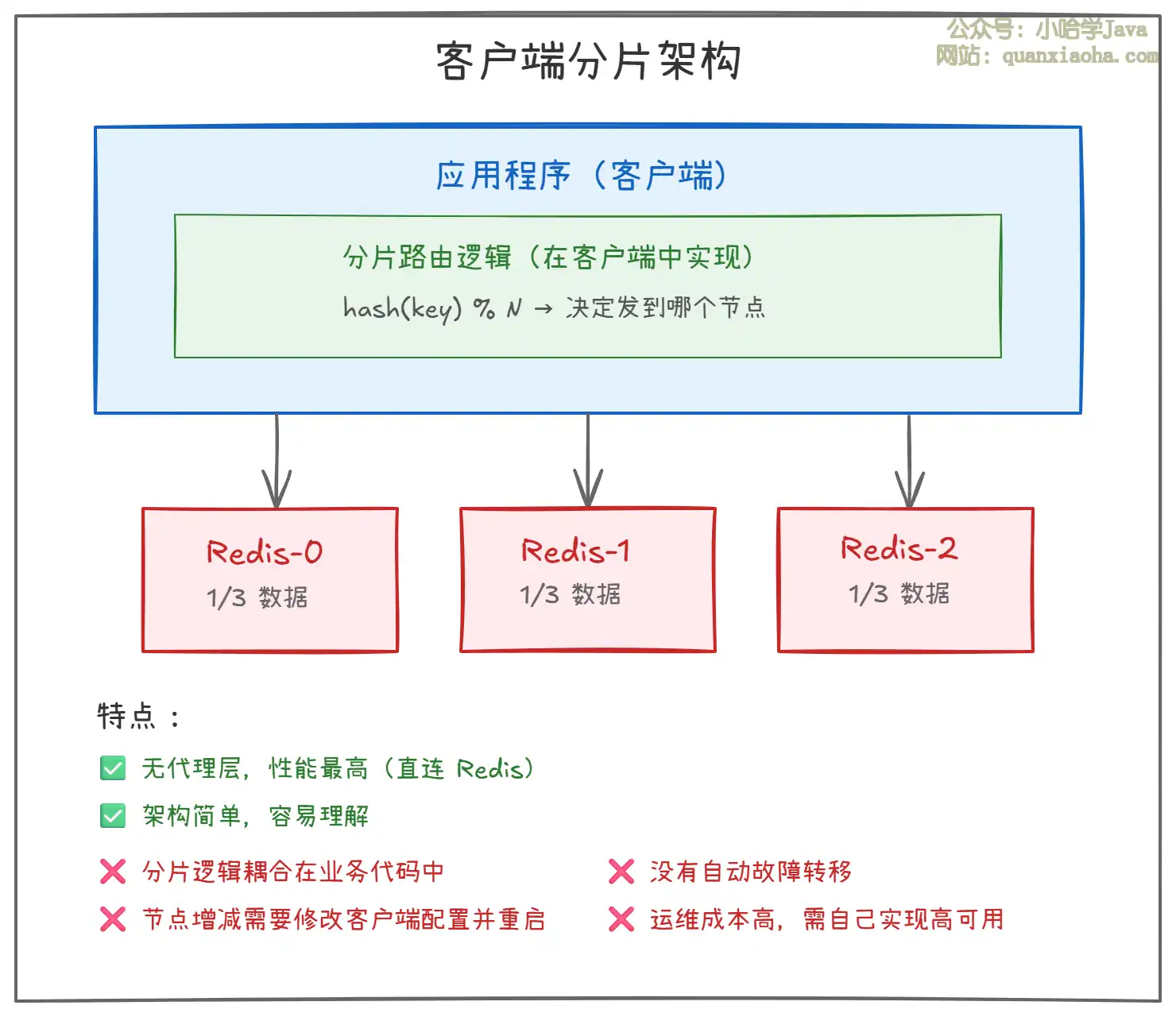
上图展示了客户端分片的架构:
- 路由逻辑在客户端:客户端根据 key 计算 hash 值,决定请求发到哪个 Redis 节点。常见算法是
hash(key) % N(N 是节点数)。 - 优点:没有代理层,客户端直连 Redis,性能最高。
- 缺点:分片逻辑耦合在业务代码中,运维不便。节点增减需要修改客户端配置并重启应用,没有自动故障转移能力,需要自己搭建 Sentinel 等方案来保证高可用。
- 代表方案:ShardedJedis、自定义分片逻辑。属于早期方案,现在已较少使用。
三、分片方式二:代理分片
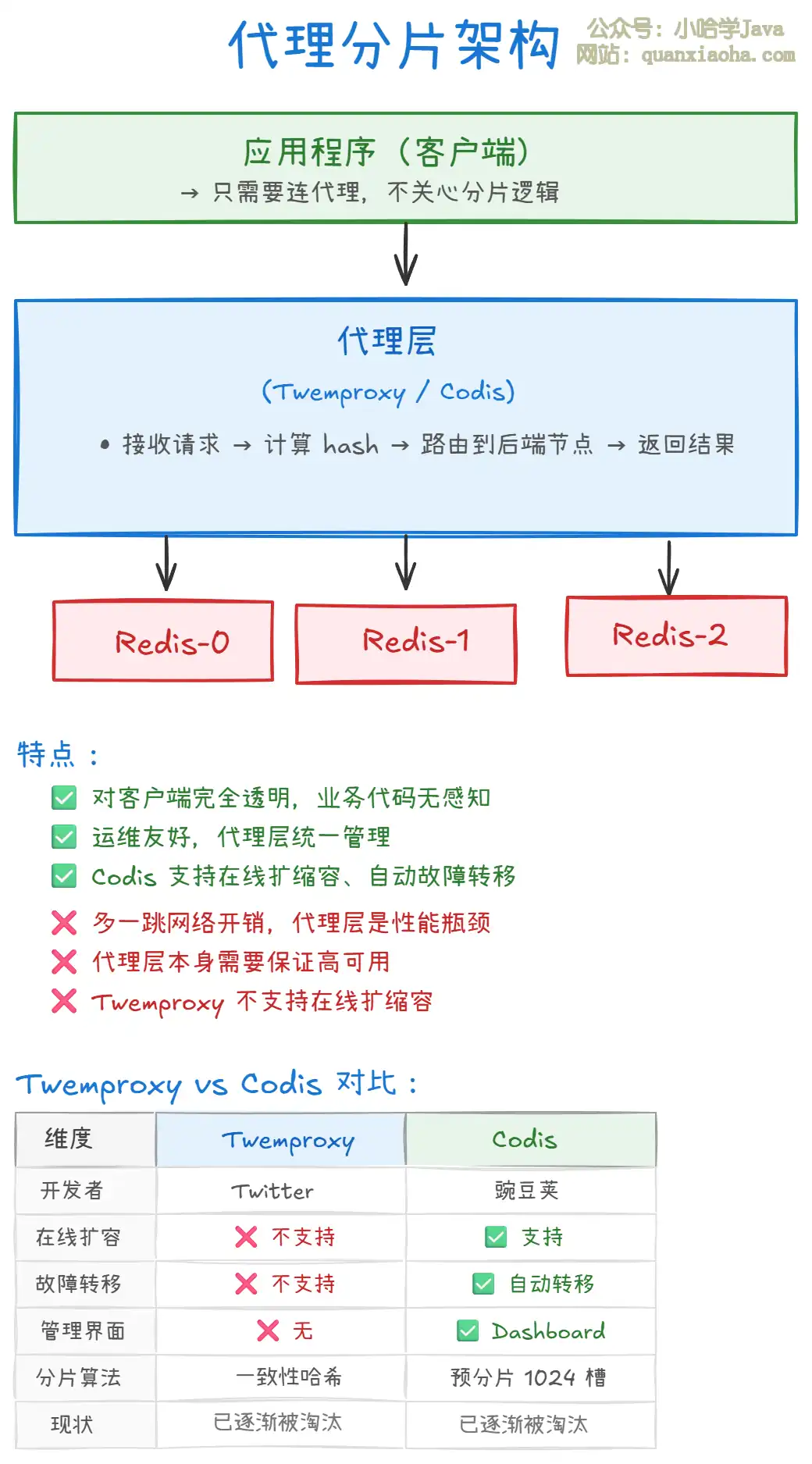
上图展示了代理分片的架构:
- 路由逻辑在代理层:客户端只需要连接代理,代理负责接收请求、计算 hash、路由到后端 Redis 节点、返回结果。客户端完全不需要关心分片逻辑。
- 优点:对客户端透明,运维友好,代理层统一管理。
- 缺点:多了一跳网络开销(客户端 → 代理 → Redis),代理层本身可能成为性能瓶颈,也需要保证高可用。
- Twemproxy vs Codis:Twemproxy 是 Twitter 开发的,轻量但不支持在线扩容和自动故障转移;Codis 是豌豆荚开发的,功能更完善(支持在线扩缩容、自动故障转移、有管理界面),但两者都已被 Redis Cluster 逐渐取代。
四、分片方式三:Redis Cluster(服务端分片)
这是 Redis 官方的分片方案,也是目前生产环境的主流选择。

上图展示了 Redis Cluster 的分片架构:
- 16384 个 Hash Slot:Cluster 将整个 key 空间划分为 16384 个 slot,平均分配给各个 Master 节点。每个 Master 负责一部分 slot。
- 路由规则:客户端发送命令时,对 key 做
CRC16(key) % 16384计算 slot 编号,然后路由到负责该 slot 的 Master 节点执行。 - 去中心化:没有代理层,客户端直连 Redis 节点。节点之间通过 Gossip 协议通信,没有中心节点。
- 高可用:每个 Master 配备至少一个 Slave,Master 宕机时 Slave 自动晋升。
- 在线扩缩容:可以通过
CLUSTER SETSLOT命令迁移 slot,实现不停机扩缩容。
五、Cluster 的路由机制
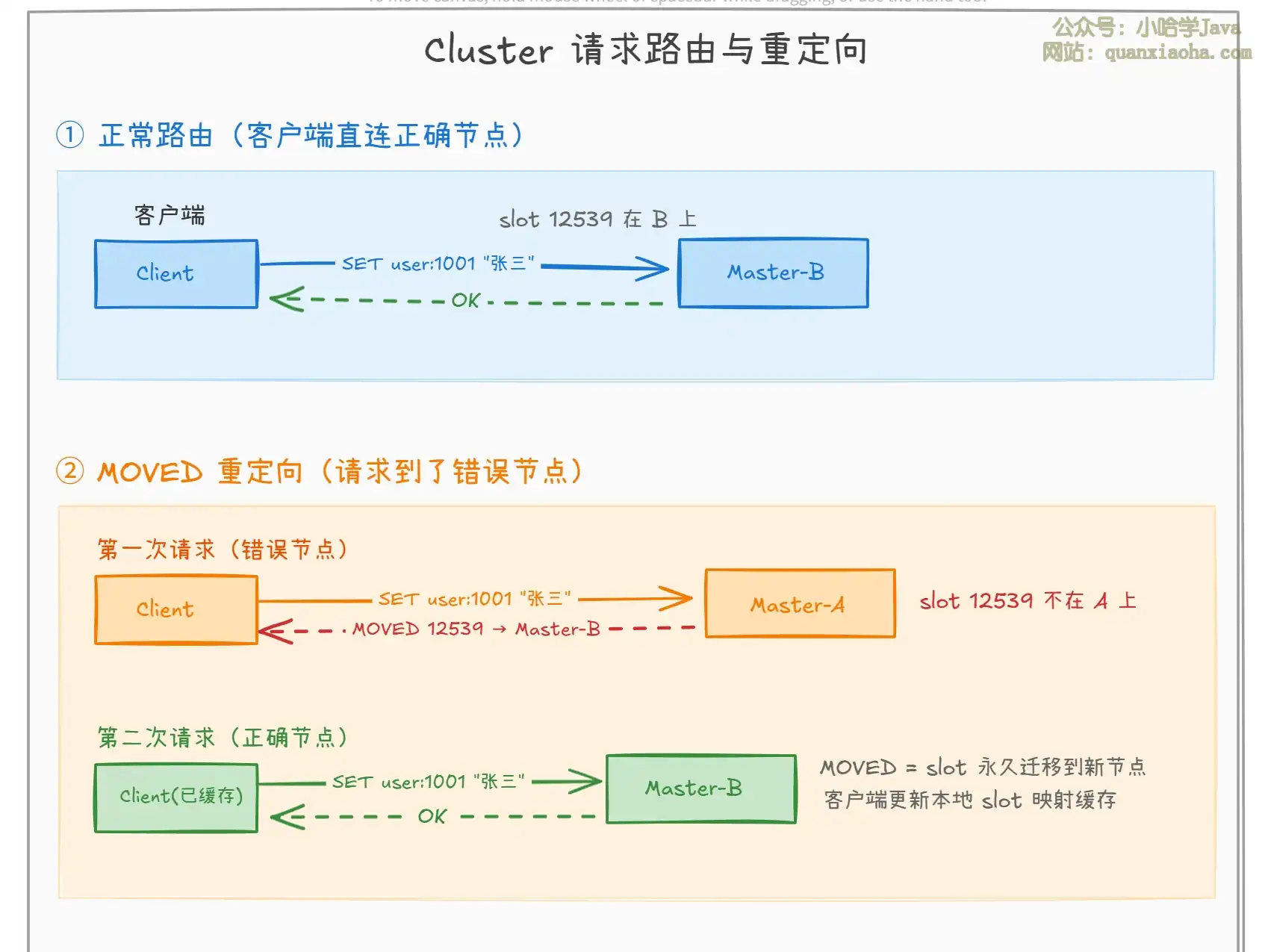
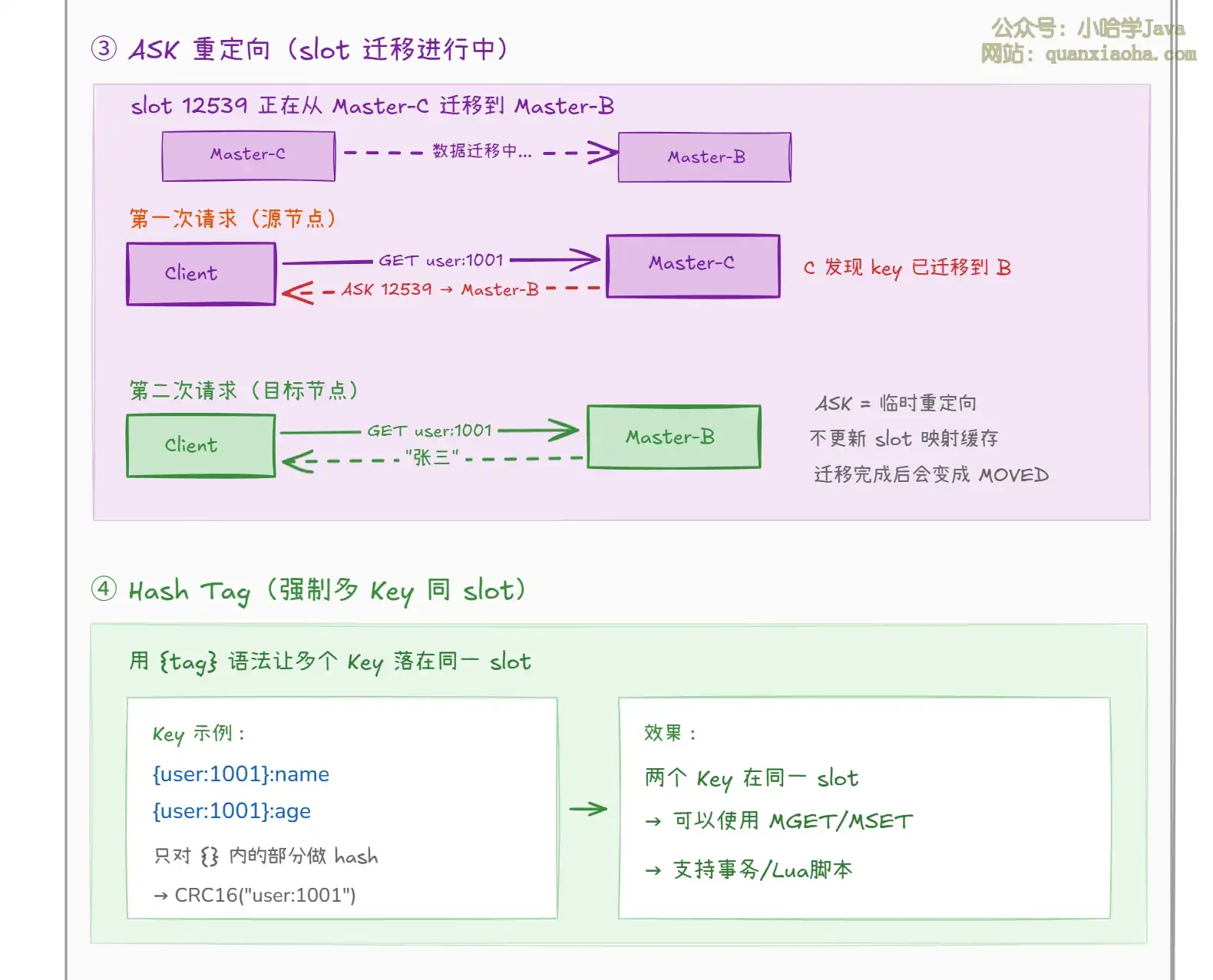
上图展示了 Cluster 的四种路由场景:
- 正常路由:客户端直接请求到了正确的节点,直接执行并返回结果。智能客户端会缓存 slot → node 的映射关系,大部分请求都能直接命中。
- MOVED 重定向:客户端请求到了错误的节点,该节点返回
MOVED指令,告诉客户端正确的节点地址。客户端更新本地缓存,下次直接路由到正确节点。MOVED表示 slot 已经 永久迁移。 - ASK 重定向:slot 迁移过程中,请求到了源节点但 key 已迁移到目标节点。源节点返回
ASK做临时重定向。ASK不会更新客户端的 slot 映射缓存,因为迁移还没完成。 - Hash Tag:用
{tag}语法强制多个 Key 落在同一 slot。只有{}内的部分参与 hash 计算。这样{user:1001}:name和{user:1001}:age会在同一 slot,可以进行MGET等多 Key 操作。
六、三种分片方式对比
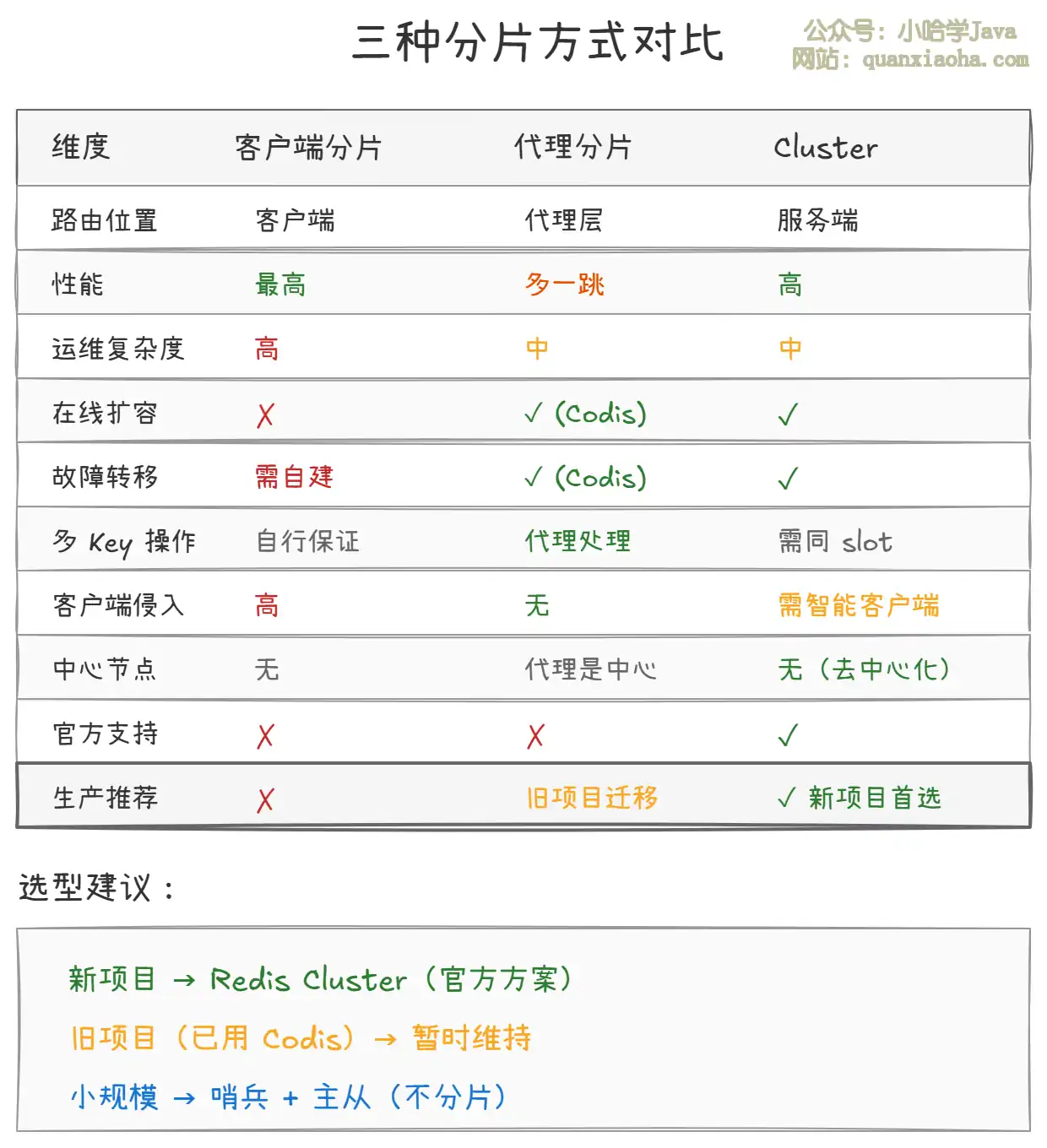
上图对比了三种分片方式的核心差异:
- 客户端分片:性能最高但运维最复杂,不适合生产环境。
- 代理分片:对客户端透明,Codis 功能完善,但多了一跳开销且非官方方案,已被 Cluster 逐渐取代。
- Redis Cluster:官方方案,去中心化,支持在线扩缩容和自动故障转移,是 新项目的首选。
面试高频追问
-
追问一:为什么 Cluster 用 16384 个 slot,而不是 65536 或其他数字?
核心原因是 Gossip 协议的心跳包大小。节点之间定期交换 slot 映射信息,16384 个 slot 只需 2KB 的 bitmap 就能表示。如果用 65536 个 slot,bitmap 就需要 8KB,心跳包变大,浪费带宽。此外 Redis 作者 antirez 认为集群节点超过 1000 个时性能就不理想了,16384 完全够用。
-
追问二:Cluster 扩缩容时数据怎么迁移?
扩容时,先加入新节点,然后从现有节点 迁移部分 slot 到新节点。迁移过程中使用
ASK重定向保证请求正常路由。缩容则反过来,先把 slot 迁走再下线节点。整个过程中集群正常服务,不会停机。 -
追问三:客户端分片中 "一致性哈希" 和 "取模" 有什么区别?
取模(
hash(key) % N)在节点数 N 变化时,大部分 key 的映射关系都会改变,导致大面积缓存失效。一致性哈希将节点映射到 0~2^32 的环上,key 也映射到环上,顺时针找最近的节点。增减节点时只影响相邻节点的数据,迁移量小。Redis Cluster 没有使用一致性哈希,而是用了 固定 slot 数(16384)+ 哈希取模,因为 slot 数固定不变,节点变化只影响 slot 的归属映射。
常见面试变体
- 变体一:"Redis Cluster 的路由机制是怎样的?"
- 变体二:"Redis 的 16384 个 slot 是怎么来的?"
- 变体三:"一致性哈希和 Hash Slot 有什么区别?"
- 变体四:"Codis 和 Redis Cluster 怎么选?"
记忆口诀
分片三种方式:客户端(最快但最累)→ 代理(透明但多一跳)→ Cluster(官方推荐)。
Cluster 核心:16384 slot 分片,CRC16 取模路由,Gossip 去中心化通信。
路由机制:正常直连、MOVED 永久迁移、ASK 临时迁移、Hash Tag 强制同 slot。
选型:新项目用 Cluster,旧项目维持 Codis,小规模不用分片。
总结
Redis 数据分片是将数据分散到多个节点以突破单机瓶颈的技术,有客户端分片、代理分片(Twemproxy/Codis)和服务端分片(Redis Cluster)三种方式。生产环境推荐 Redis Cluster,通过 16384 个 Hash Slot 实现自动分片、路由和故障转移。核心路由机制是 CRC16(key) % 16384,配合 MOVED/ASK 重定向和 Hash Tag 解决跨节点操作问题。