Redis 为什么要自定义 SDS?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道 SDS 是什么,更是想知道你是否读过 Redis 源码中
sds.h的结构定义,能否说清楚 C 字符串的 5 大缺陷以及 SDS 是如何逐一解决的。 -
性能优化意识:考察你是否理解 "strlen O(N) → O(1)"、"N 次重分配 → 空间预分配 & 惰性释放"、"缓冲区溢出" 这些性能和安全问题的工程解法。
-
源码级理解深度:能否说出 SDS 有 5 种类型(
sdshdr5~sdshdr64),以及为什么要按字符串长度做分级,这体现了 Redis 在内存优化上的极致追求。
核心答案
Redis 自定义 SDS(Simple Dynamic String)是为了解决 C 语言原生字符串的 5 大缺陷:
| C 字符串缺陷 | SDS 的解决方案 | 收益 |
|---|---|---|
strlen O(N) 遍历计数 |
len 字段记录长度 |
O(1) 获取长度 |
| 缓冲区溢出风险 | alloc - len 检查剩余空间 |
修改前自动扩容,杜绝溢出 |
| 频繁内存重分配 | 空间预分配 + 惰性释放 | 大幅减少 realloc 次数 |
只能存文本(\0 结尾) |
二进制安全,用 len 判断结尾 |
可存图片、音频等二进制数据 |
| 限定了字符串操作函数 | 丰富的专用 API | sdscat、sdscpy、sdssplitlen 等 |
一句话结论:SDS 本质上是一个 带元信息的动态字符数组,在保持 C 字符串兼容性的同时,解决了 O(N) 长度计算、缓冲区溢出、频繁重分配、二进制安全四大核心问题。
深度解析
一、SDS 的结构定义

上图展示了 C 字符串和 SDS 的内存布局对比,核心要点:
len:已使用的字节数(不含\0)。获取字符串长度时直接返回len,时间复杂度 O(1)。alloc:buf[]的总分配空间(不含头部和\0)。alloc - len就是剩余可用空间,用于判断是否需要扩容。flags:低 3 位标识 SDS 类型(sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64),不同类型用不同大小的len和alloc字段。buf[]:实际存储数据的地方,仍然以\0结尾,这样 SDS 可以直接复用一部分 C 标准库的字符串函数(如printf、strcasecmp)。
二、5 大优势逐一解析
优势一:O(1) 获取字符串长度
// C 字符串:必须遍历到 \0 才知道长度,O(N)
size_t strlen(const char *s) {
size_t len = 0;
while (s[len] != '\0') len++;
return len;
}
// Redis 中 strlen 被大量调用,比如每次执行 STRLEN 命令
// 如果用 C 字符串,一个 1MB 的字符串每次都要遍历 100 万字节!
// SDS:直接返回 len 字段,O(1)
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1]; // flags 在 buf 的前一个字节
switch(flags & SDS_TYPE_MASK) {
case SDS_TYPE_8: return ((struct sdshdr8*)s)[-1].len;
case SDS_TYPE_16: return ((struct sdshdr16*)s)[-1].len;
// ...
}
}
Redis 中有大量需要获取字符串长度的场景(键的长度检查、命令参数解析等),如果每次都 O(N) 遍历,性能会急剧下降。SDS 用一个 len 字段就把时间复杂度从 O(N) 降到了 O(1)。
优势二:杜绝缓冲区溢出

上图展示了 C 字符串的缓冲区溢出问题:
- C 语言的
strcat、strcpy等函数 不检查目标缓冲区大小,如果空间不够就直接往后写,覆盖相邻内存。 - SDS 在每次修改前,先检查
alloc - len(剩余空间),如果不够就先扩容,再执行修改,从根本上杜绝溢出。
优势三:减少内存重分配次数
C 字符串每次修改长度都可能触发 realloc(增长要扩容,缩短要释放)。SDS 通过两种策略大幅减少 realloc 次数:

上图展示了 SDS 的两种内存优化策略:
- 空间预分配:字符串增长时,多分配一些空间。小于 1MB 时多分配一倍,大于等于 1MB 时多分配 1MB。下次追加操作如果不超过预分配空间,就不需要
realloc。 - 惰性释放:字符串缩短时,不立即释放多余内存,只修改
len,保留alloc不变。下次增长时可以直接复用。需要真正释放时可以调用sdsRemoveFreeSpace。
优势四:二进制安全

上图展示了二进制安全的核心区别:
- C 字符串:用
\0判断结尾,遇到\0就认为字符串结束。这意味着不能存储包含\0的数据(图片、音频、序列化对象等)。 - SDS:用
len字段判断结尾,\0只是一个普通字节。可以存储任意二进制数据,这就是 二进制安全。
Redis 作为一个通用的数据结构存储系统,不仅存储文本,还存储整数、浮点数、图片、序列化对象等,所以必须二进制安全。
优势五:5 种 SDS 类型,极致内存优化
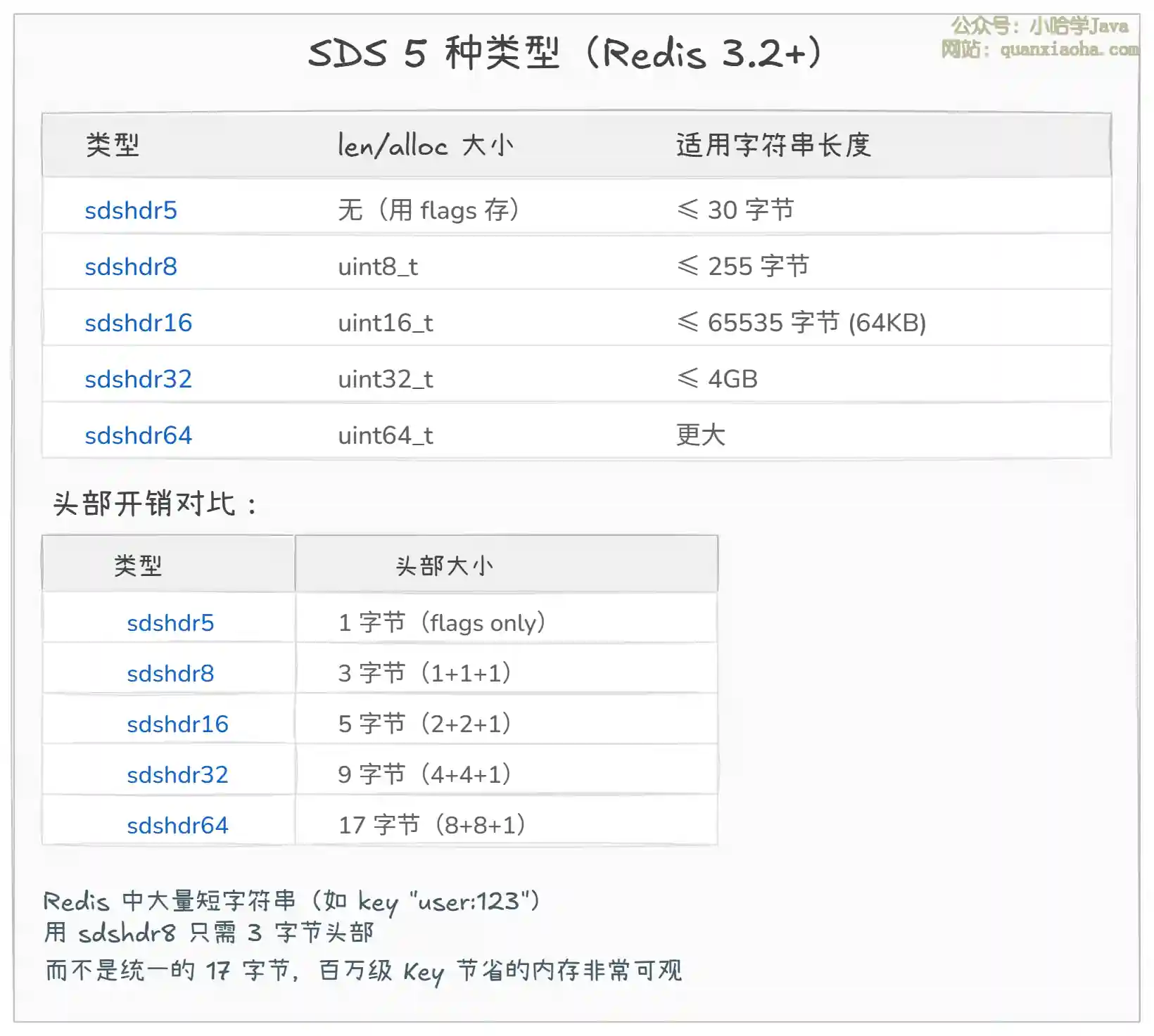
上图展示了 SDS 的 5 种类型设计:
- Redis 3.2 之前只有一种
sdshdr,len和alloc固定用int(4 字节),对于短字符串(如"name"、"age")来说,头部开销太大。 - Redis 3.2 之后拆分为 5 种类型,根据字符串长度自动选择最合适的类型,头部开销从固定 8 字节降低到 1~3 字节。
- Redis 中有海量的短字符串(Key 名、小 Value),这种分级设计能节省大量内存。
三、SDS 与 C 字符串的完整对比
| 对比维度 | C 字符串 | SDS |
|---|---|---|
| 获取长度 | O(N) 遍历 | O(1) 读 len |
| 缓冲区溢出 | 不检查,可能溢出 | 修改前检查,自动扩容 |
| 内存重分配 | 每次修改都要 | 预分配 + 惰性释放,大幅减少 |
| 存储内容 | 文本(\0 结尾) |
任意二进制数据 |
| 兼容 C 函数 | 本身就是 | 以 \0 结尾,部分兼容 |
| 头部开销 | 0 | 1~17 字节(按类型分级) |
| 适用场景 | 简单文本处理 | 高性能、高并发的存储系统 |
面试高频追问
-
追问一:SDS 怎么做到兼容 C 字符串函数的?
SDS 的
buf[]末尾始终保留一个\0,所以可以把buf的地址直接传给 C 标准库函数(如printf、strcasecmp、strchr等)。但要注意,这些函数仍然以\0判断结尾,所以只适用于不含\0的文本数据。对于二进制数据,必须使用 SDS 自带的 API。 -
追问二:
sdshdr5为什么没有len和alloc字段?sdshdr5专门用于长度 ≤ 30 字节的极短字符串。它把长度信息压缩到flags字段的高 5 位中(低 3 位标识类型),省去了len和alloc两个独立字段,头部只需要 1 字节。不过sdshdr5只用于 不可变字符串(如 Key 名),可变字符串会使用sdshdr8及以上。 -
追问三:Redis 中哪些地方用到了 SDS?
几乎所有涉及字符串的地方都用 SDS:Key 的存储、String 类型的 Value、List/Hash/Set/ZSet 的元素、Pub/Sub 的频道名和消息内容、命令参数解析等。可以说 SDS 是 Redis 中最基础、使用最广泛的数据结构。
常见面试变体
- 变体一:"Redis 的字符串是怎么实现的?"
- 变体二:"SDS 和 C 字符串的区别?"
- 变体三:"什么是二进制安全?为什么 Redis 需要二进制安全?"
- 变体四:"Redis 3.2 前后 SDS 有什么变化?"
记忆口诀
SDS 5 大优势:快(O(1) 长度)、安(防溢出)、省(少 realloc)、全(二进制安全)、省(5 级头部)。
结构三件套:len(已用)+ alloc(总容量)+ flags(类型标记)。
核心一句话:C 字符串靠 \0 管一切,SDS 用 len 管长度、用 alloc 管容量、用 flags 管类型,三个字段解决五大问题。
总结
Redis 自定义 SDS 是为了解决 C 原生字符串的 5 大缺陷:O(N) 长度计算、缓冲区溢出、频繁内存重分配、非二进制安全、缺少专用 API。SDS 通过 len + alloc + flags 三个字段,实现了 O(1) 长度获取、自动扩容防溢出、空间预分配和惰性释放减少重分配、二进制安全存储任意数据。Redis 3.2+ 还将 SDS 拆分为 5 种类型,极致优化内存开销。