什么是缓存击穿、缓存穿透、缓存雪崩?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道这三个概念的定义,更是想知道你是否能清晰区分它们的触发场景("查不到" vs "过期了" vs "集体过期"),以及各自对应的解决方案。
-
方案设计能力:考察你是否了解布隆过滤器、互斥锁、随机 TTL、熔断降级等生产级别的防护手段,而不是只停留在 "加缓存" 这种表面回答。
-
架构思维:能否认识到这三类问题本质上都是 "缓存失效 → 大量请求打到 DB" 的不同变体,需要从 缓存层、应用层、数据库层 多维度防御。
核心答案
| 问题 | 触发场景 | 核心特征 | 首选方案 |
|---|---|---|---|
| 缓存穿透 | 查询 根本不存在 的数据 | 缓存和 DB 都没有,每次都穿透 | 布隆过滤器 + 空值缓存 |
| 缓存击穿 | 热点 Key 突然过期 | 大量并发请求同时打到 DB | 互斥锁 + 逻辑过期 |
| 缓存雪崩 | 大量 Key 同时过期 或 Redis 宕机 | 瞬间全部请求压向 DB | 随机 TTL + Redis 高可用 + 熔断降级 |
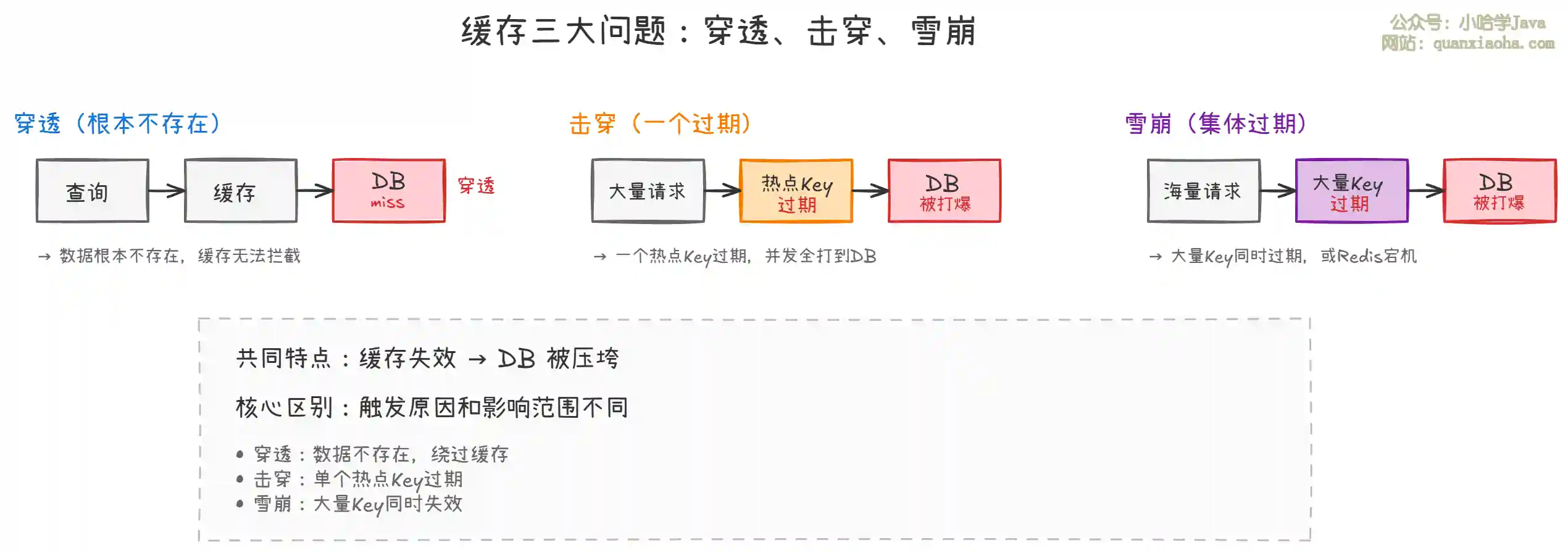
一句话结论:穿透是 "查的东西根本不存在",击穿是 "一个热点 Key 过期了",雪崩是 "一堆 Key 同时过期或 Redis 挂了"。三者本质都是缓存挡不住请求,DB 被压垮。
深度解析
一、缓存穿透:查的东西根本不存在
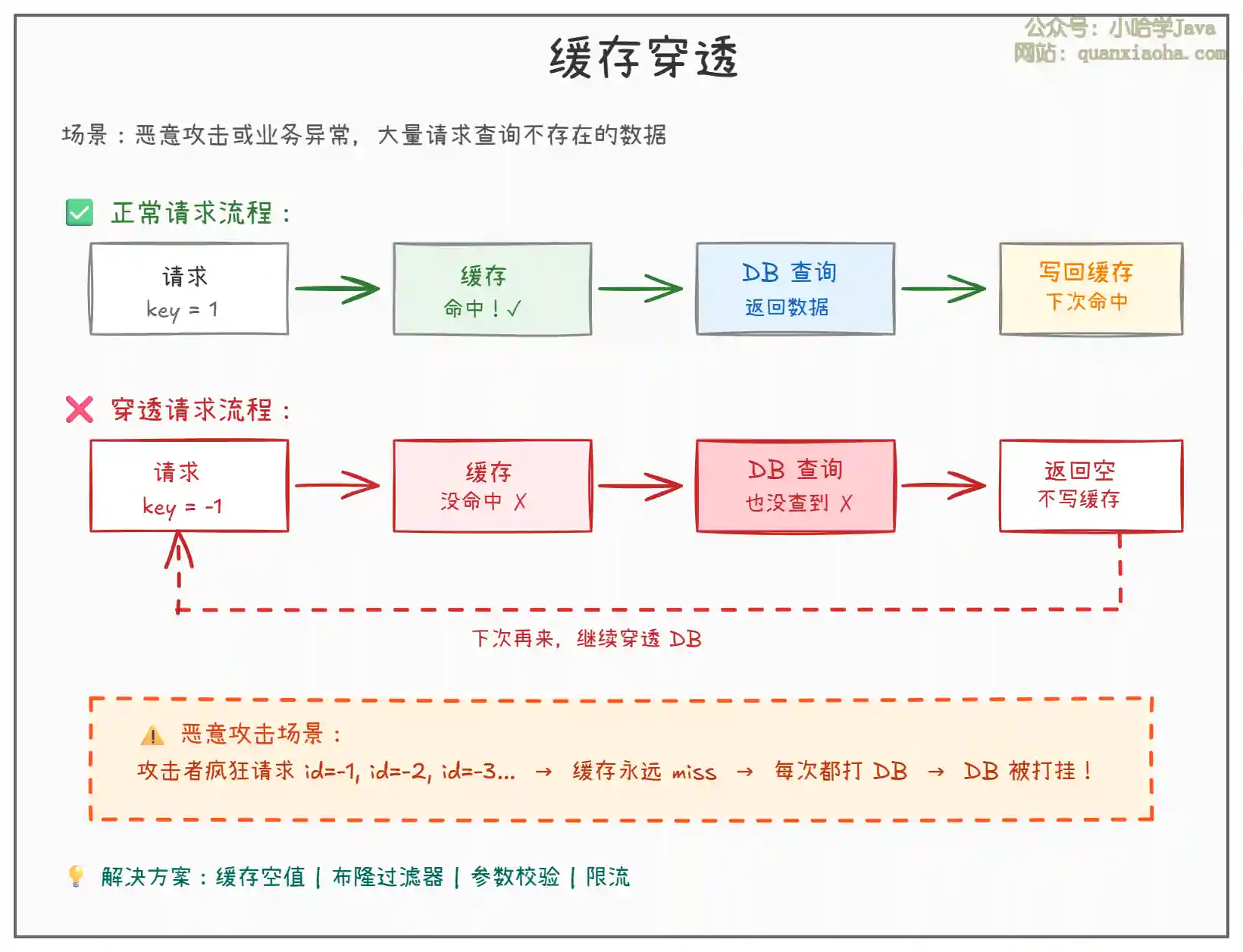
上图展示了缓存穿透的核心问题:
- 请求的数据在缓存和数据库中都不存在,比如查询
id = -1的用户,缓存里没有,数据库里也没有。 - 因为没有数据,所以也 无法写入缓存,下次同样的请求还是会穿透到数据库。
- 恶意攻击者可以利用这一点,大量发送查询不存在数据的请求,直接把数据库打挂。
解决方案一:布隆过滤器(推荐)
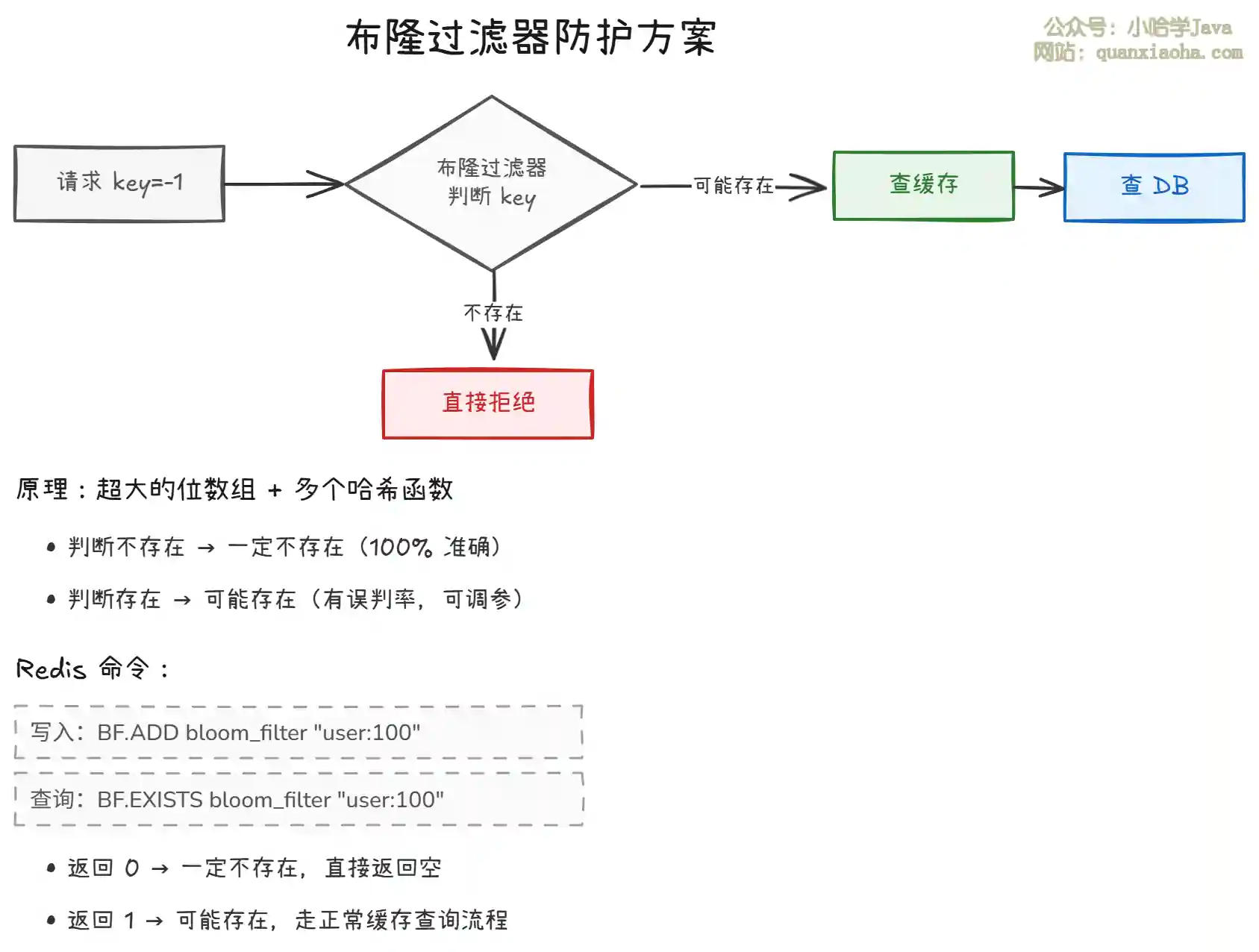
上图展示了布隆过滤器的防护逻辑:
- 在请求到达缓存之前,先经过布隆过滤器快速判断数据是否存在。
- 布隆过滤器判断 不存在则一定不存在,可以直接拒绝请求,不查缓存也不查 DB。
- 判断存在则 可能存在(有误判率),走正常的缓存 → DB 查询流程。
- 适合 数据相对固定、可预加载 的场景(如商品 ID、用户 ID)。
解决方案二:缓存空值
public Object getUserById(Long id) {
String key = "user:" + id;
// 1. 查缓存
String value = redis.get(key);
if (value != null) {
// 命中缓存(包括空值缓存)
return "NULL".equals(value) ? null : deserialize(value);
}
// 2. 查数据库
Object user = userDao.findById(id);
if (user != null) {
// 正常数据,写入缓存,TTL 30 分钟
redis.set(key, serialize(user), 30, TimeUnit.MINUTES);
} else {
// 空值也要缓存!TTL 设短一些,比如 5 分钟
redis.set(key, "NULL", 5, TimeUnit.MINUTES);
}
return user;
}
关键点:
- 当数据库也查不到时,往缓存中写入一个 空值标记(如
"NULL"),并设置一个较短的 TTL。 - 下次同样的请求会命中这个空值缓存,直接返回,不再打到 DB。
- 注意:空值 TTL 不能设太长,否则当数据真正被插入后,缓存中的空值会阻止读取到新数据。
方案对比:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 布隆过滤器 | 内存占用极小,判断高效 | 有误判率,不支持删除,需预加载 | 数据相对固定,ID 类查询 |
| 缓存空值 | 实现简单,通用 | 浪费缓存空间,可能数据不一致 | 查询条件多样,无法预加载 |
二、缓存击穿:一个热点 Key 突然过期
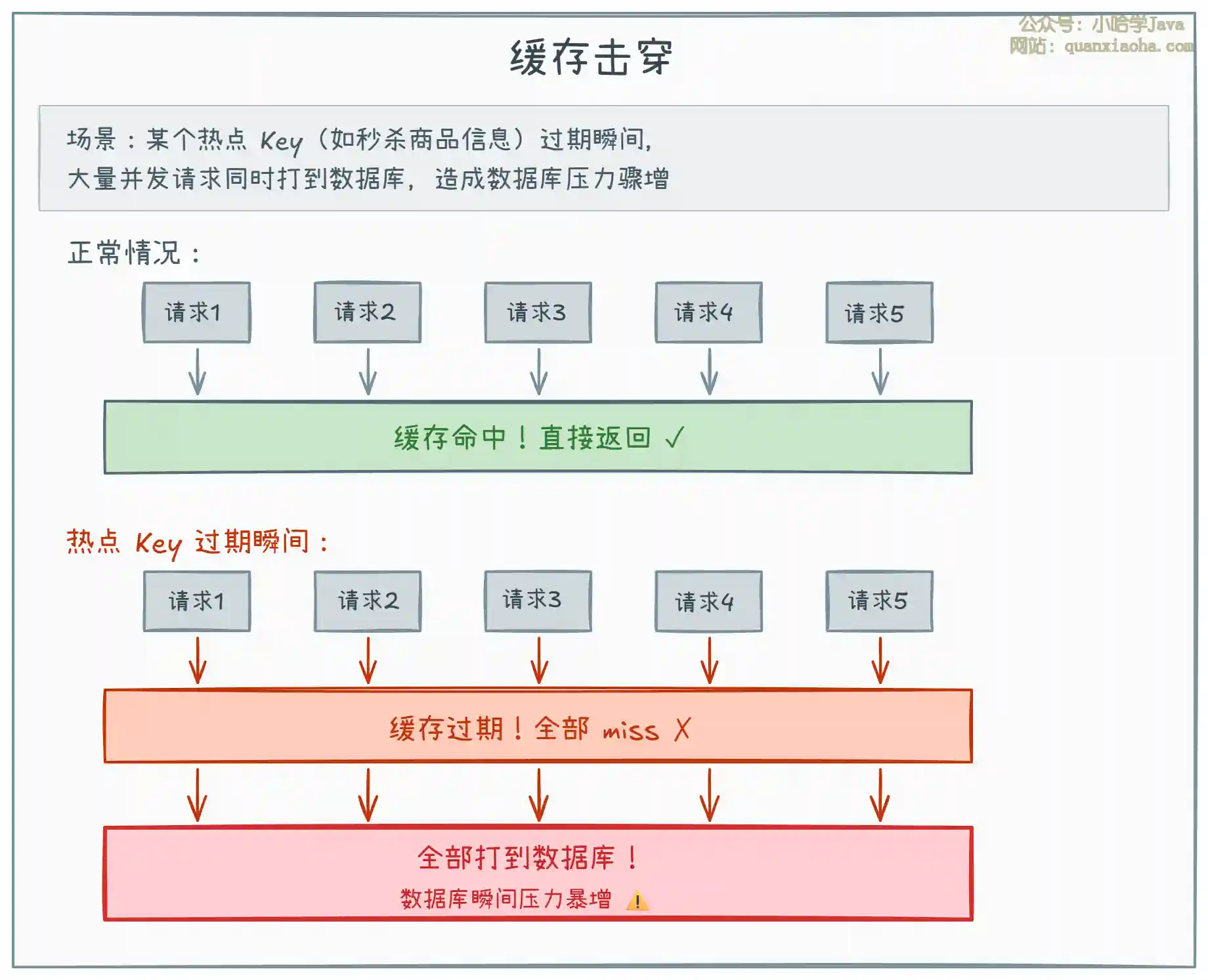
上图展示了缓存击穿的核心问题:
- 某个 热点 Key(如热门商品信息、首页推荐数据)在缓存中过期了。
- 过期的瞬间,大量并发请求同时发现缓存 miss,全部涌向数据库。
- 典型场景:秒杀商品详情、热门文章、微博热搜 等高并发读的热点数据。
解决方案一:互斥锁(推荐)
public Object getHotData(String key) {
// 1. 查缓存
String value = redis.get(key);
if (value != null) {
return deserialize(value);
}
// 2. 缓存 miss,尝试获取分布式锁(只让一个请求去查 DB)
String lockKey = "lock:" + key;
boolean locked = redis.set(lockKey, "1", "NX", "EX", 10);
if (locked) {
try {
// 3. 获取锁成功,double-check 缓存(可能被其他线程写入了)
value = redis.get(key);
if (value != null) {
return deserialize(value);
}
// 4. 查数据库
Object data = db.query(key);
// 5. 写入缓存
redis.set(key, serialize(data), 30, TimeUnit.MINUTES);
return data;
} finally {
// 6. 释放锁
redis.del(lockKey);
}
} else {
// 7. 获取锁失败,说明其他线程在查 DB,稍等后重试
Thread.sleep(100);
return getHotData(key); // 递归重试
}
}
关键点:
- 大量请求中,只有 获取到分布式锁的那个请求 去查数据库,其他请求等待后重试。
- 其他请求重试时,缓存可能已经被第一个请求写入了,直接命中缓存返回。
- Double-check:获取锁后再查一次缓存,避免重复查 DB。
解决方案二:逻辑过期(不设 TTL)
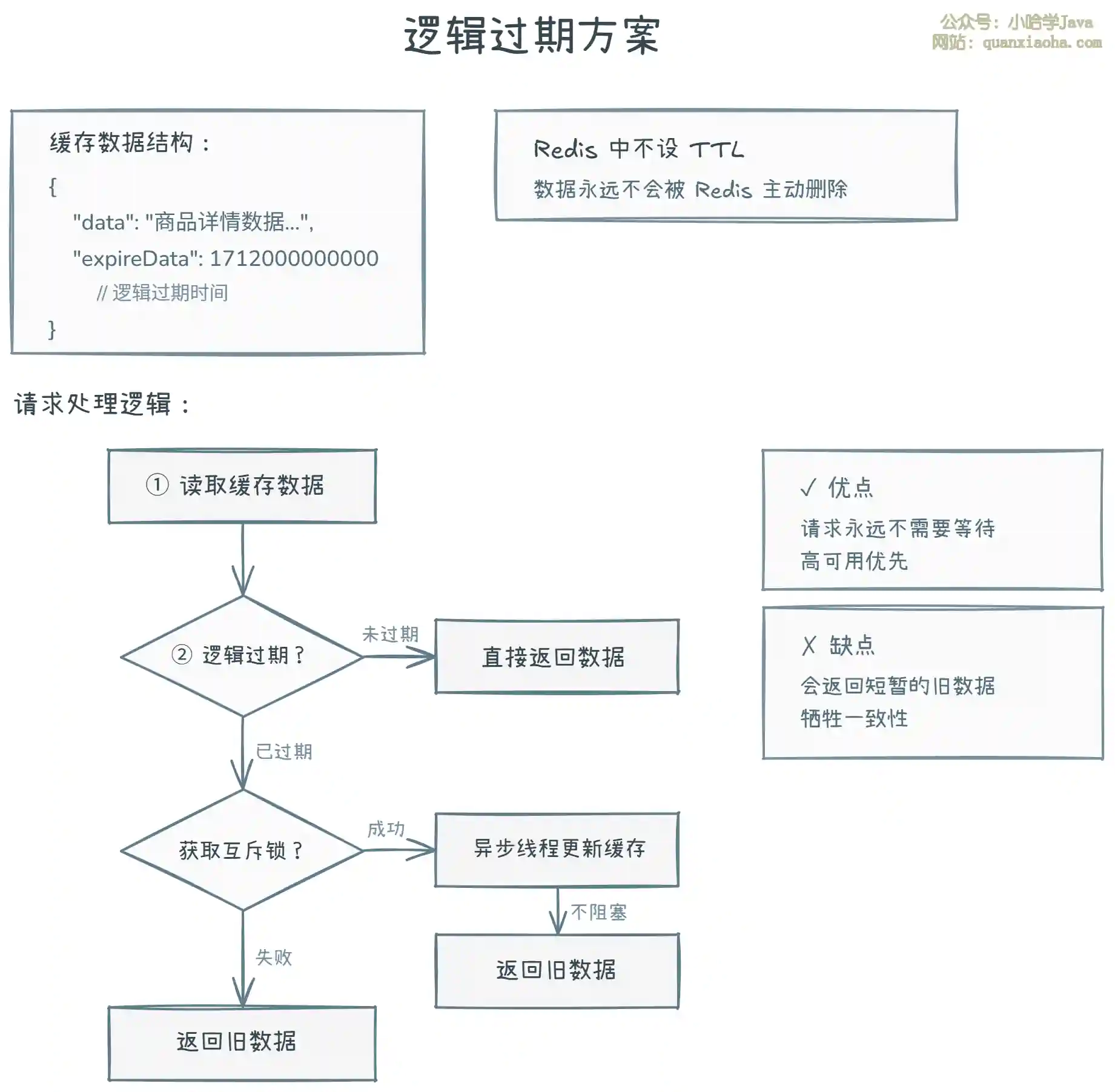
上图展示了逻辑过期的核心思路:
- 缓存数据中包含一个 逻辑过期时间 字段,但 Redis 中 不设物理 TTL,数据永远不会被 Redis 主动删除。
- 读取时判断逻辑过期时间:未过期直接返回;已过期则获取互斥锁,获取成功后 异步开启一个线程 去更新缓存,当前请求返回旧数据。
- 其他请求发现过期但拿不到锁,也直接返回旧数据。
- 适合对一致性要求不高、但高可用要求高的场景(如商品详情页,旧数据短暂展示可以接受)。
方案对比:
| 方案 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 互斥锁 | 强一致(同一时刻只有一个数据源) | 有等待时间 | 低 | 一致性要求高 |
| 逻辑过期 | 最终一致(短暂返回旧数据) | 无等待,性能最佳 | 中 | 高可用优先,允许短暂不一致 |
三、缓存雪崩:大量 Key 同时过期或 Redis 宕机

上图展示了缓存雪崩的两种触发场景:
- 场景一:大量 Key 同时过期。如果一批 Key 的 TTL 设成一样的(比如批量导入数据时都设了 30 分钟),到期后全部失效,瞬间大量请求全部打到 DB。
- 场景二:Redis 宕机。缓存层整体不可用,所有请求直接打到数据库,数据库扛不住就整体雪崩。
- 与击穿的区别:击穿是 "一个热点 Key 过期",雪崩是 "大量 Key 集体过期",范围更广,危害更大。
解决方案:多维度防御

上图展示了缓存雪崩的四层防御体系:
- 第一层:随机 TTL。给缓存过期时间加一个随机偏移量,把集中过期打散成分散过期。这是最简单也最有效的手段。
- 第二层:Redis 高可用。用哨兵或集群模式保证 Redis 本身不会单点故障。还可以加一层本地缓存(如 Caffeine)作为二级缓存兜底。
- 第三层:熔断降级。当 DB 压力过大时,通过 Sentinel 等熔断框架直接拒绝部分请求,返回降级数据(如默认值、温馨提示),保护数据库不被打挂。
- 第四层:限流排队。用令牌桶或漏桶算法控制打到 DB 的请求速率,避免瞬时流量压垮数据库。
随机 TTL 代码示例:
// 批量设置缓存时,给 TTL 加随机偏移量
public void batchSetCache(Map<String, Object> dataMap) {
Random random = new Random();
for (Map.Entry<String, Object> entry : dataMap.entrySet()) {
// 基础 TTL 30 分钟 + 0~10 分钟随机偏移
long ttl = 30 * 60 + random.nextInt(10 * 60);
redis.set(entry.getKey(), serialize(entry.getValue()), (int) ttl, TimeUnit.SECONDS);
}
}
四、三者对比总结
面试高频追问
-
追问一:布隆过滤器有误判怎么办?
布隆过滤器判断 "存在" 时有一定误判率(可能实际不存在),但判断 "不存在" 时是 100% 准确的。可以通过增大位数组大小和增加哈希函数个数来降低误判率。生产环境通常设置误判率在 1% 以下即可。如果误判了,最多也就是多查一次数据库,不会造成严重后果。
-
追问二:互斥锁方案中,如果查 DB 的线程挂了怎么办?锁会不会死锁?
分布式锁必须设置过期时间(如 10 秒),即使持有锁的线程挂了,锁也会自动释放。但要注意 锁过期时间要大于 DB 查询时间,否则锁提前释放会导致其他线程也去查 DB。如果担心,可以在代码中加
try-finally确保锁一定被释放。 -
追问三:如果 Redis 宕机了,怎么办?
第一道防线是 Redis 高可用(哨兵/集群),保证单节点故障不影响整体服务。第二道防线是 本地缓存(Caffeine、Guava Cache),Redis 不可用时退而求其次用本地缓存。第三道防线是 熔断降级,Redis 和本地缓存都不行时,直接返回降级数据,保护数据库。
常见面试变体
- 变体一:"缓存穿透怎么解决?"
- 变体二:"热点 Key 过期了怎么办?"
- 变体三:"如何防止大量 Key 同时过期?"
- 变体四:"Redis 宕机了怎么办?"
- 变体五:"你项目中遇到过缓存相关的问题吗?怎么解决的?"
记忆口诀
穿透:查的东西不存在 —— 布隆过滤挡在前,空值缓存兜在后。
击穿:一个热点突然过期 —— 互斥锁只放一个去查 DB,逻辑过期异步更新不阻塞。
雪崩:大量 Key 集体过期 —— 随机 TTL 打散时间,高可用防宕机,熔断限流保命。
核心区别:穿透是 "没有",击穿是 "一个没了",雪崩是 "一堆没了"。
总结
缓存击穿、穿透、雪崩本质上都是 "缓存失效 → 请求打到 DB → DB 被压垮" 的不同变体。穿透 是查询不存在的数据,用布隆过滤器和空值缓存解决;击穿 是热点 Key 过期,用互斥锁或逻辑过期解决;雪崩 是大量 Key 同时过期或 Redis 宕机,用随机 TTL + 高可用 + 熔断降级多维度防御。生产环境需要 多层防护,不能只依赖单一方案。