MySQL 为什么不推荐使用外键?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
性能意识:面试官不仅仅是想知道 "不推荐外键" 这个结论,更是想考察你是否理解外键带来的性能开销——每次写入都要检查约束、加锁、可能导致死锁。
-
架构设计思维:考察你是否具备分布式系统的设计视角,外键在分库分表、微服务架构下根本无法使用,需要在应用层维护数据一致性。
-
权衡取舍能力:外键能保证数据一致性但也有代价,考察你能否根据业务场景(强一致性 vs 高性能 vs 可扩展性)做出合理选择。
核心答案
外键(Foreign Key):用于建立表与表之间的关联关系,保证参照完整性。但互联网大厂普遍 不推荐在生产环境使用外键。
不推荐外键的核心原因:
| 问题维度 | 具体影响 | 严重程度 |
|---|---|---|
| 性能开销 | 每次插入/更新/删除都要检查外键约束 | ⭐⭐⭐⭐ |
| 锁竞争 | 外键检查会锁住父表记录,影响并发 | ⭐⭐⭐⭐⭐ |
| 死锁风险 | 跨表操作容易产生死锁 | ⭐⭐⭐⭐ |
| 扩展性 | 分库分表后外键失效 | ⭐⭐⭐⭐⭐ |
| 运维困难 | 批量数据迁移、删表受外键约束 | ⭐⭐⭐ |
一句话总结:外键通过数据库层面的约束保证一致性,但代价是 性能下降、锁竞争、死锁风险、无法分库分表,互联网场景更倾向于 在应用层维护关联关系。
深度解析
一、外键带来的性能问题
先看一个外键的示例:
-- 父表:订单表
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
order_no VARCHAR(32),
user_id BIGINT,
INDEX idx_user (user_id)
);
-- 子表:订单明细表(有外键约束)
CREATE TABLE order_items (
id BIGINT PRIMARY KEY,
order_id BIGINT,
product_name VARCHAR(100),
FOREIGN KEY (order_id) REFERENCES orders(id) -- 外键约束
);
当向 order_items 表插入数据时,MySQL 的执行过程:

上图展示了外键约束带来的额外开销。关键问题说明:
- 额外的 I/O:每次写入子表时,都要先查询父表确认关联记录存在
- 锁竞争:外键检查会对父表记录加 共享锁(S 锁),与更新操作的排他锁冲突
- 级联操作:如果配置了
ON DELETE CASCADE,删除父表记录会自动删除子表记录,开销更大
二、外键导致的锁竞争和死锁
外键最容易引发的并发问题:

上图展示了外键可能导致的死锁场景。核心问题在于:
- 锁类型冲突:外键检查加 S 锁(共享锁),更新操作加 X 锁(排他锁),两者互斥
- 跨表锁:一个事务可能同时锁住父表和子表的记录,增加死锁概率
- 难以排查:死锁往往是偶发的,高并发下才暴露,排查成本高
三、外键与分库分表不可兼容
互联网大厂普遍采用 分库分表 架构,外键在这种场景下完全失效:
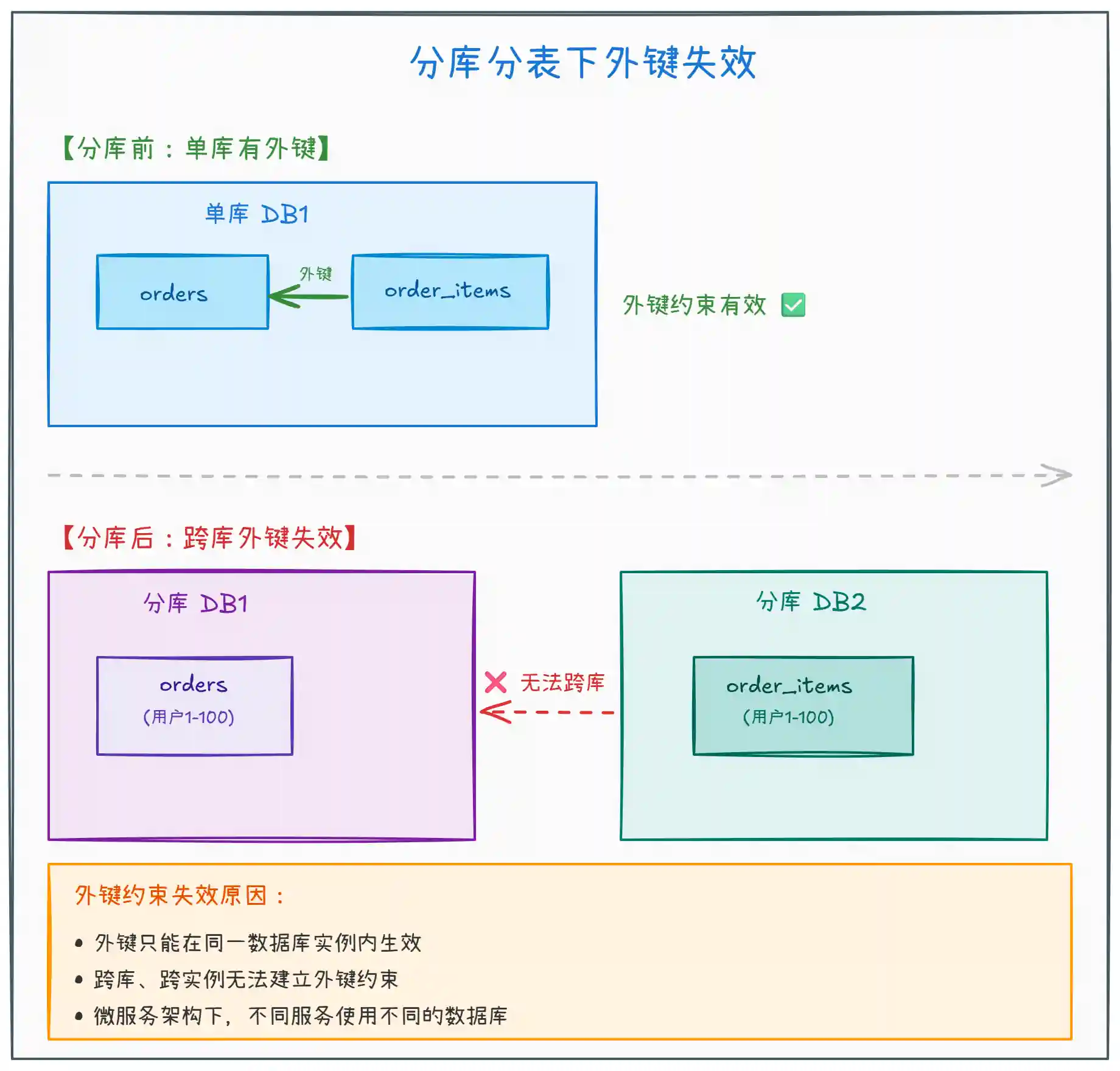
上图展示了分库分表架构下外键的局限性。核心矛盾在于:
- 跨库无外键:MySQL 的外键约束只在同一数据库实例内有效
- 微服务隔离:不同微服务有独立的数据库,物理上无法建立外键
- 分布式事务:跨库一致性需要用分布式事务(Seata、TCC)或最终一致性方案
四、替代方案:应用层维护关联关系
既然不用外键,如何在应用层保证数据一致性?
方案一:业务代码中校验
@Service
public class OrderService {
@Transactional
public void createOrderItem(Long orderId, OrderItemDTO itemDTO) {
// 1. 先检查父记录是否存在
Order order = orderMapper.selectById(orderId);
if (order == null) {
throw new BusinessException("订单不存在");
}
// 2. 再插入子记录
OrderItem item = new OrderItem();
item.setOrderId(orderId);
item.setProductName(itemDTO.getProductName());
orderItemMapper.insert(item);
}
}
方案二:定期清理孤儿数据
-- 定时任务:清理没有对应订单的订单明细(孤儿数据)
DELETE FROM order_items
WHERE order_id NOT IN (SELECT id FROM orders);
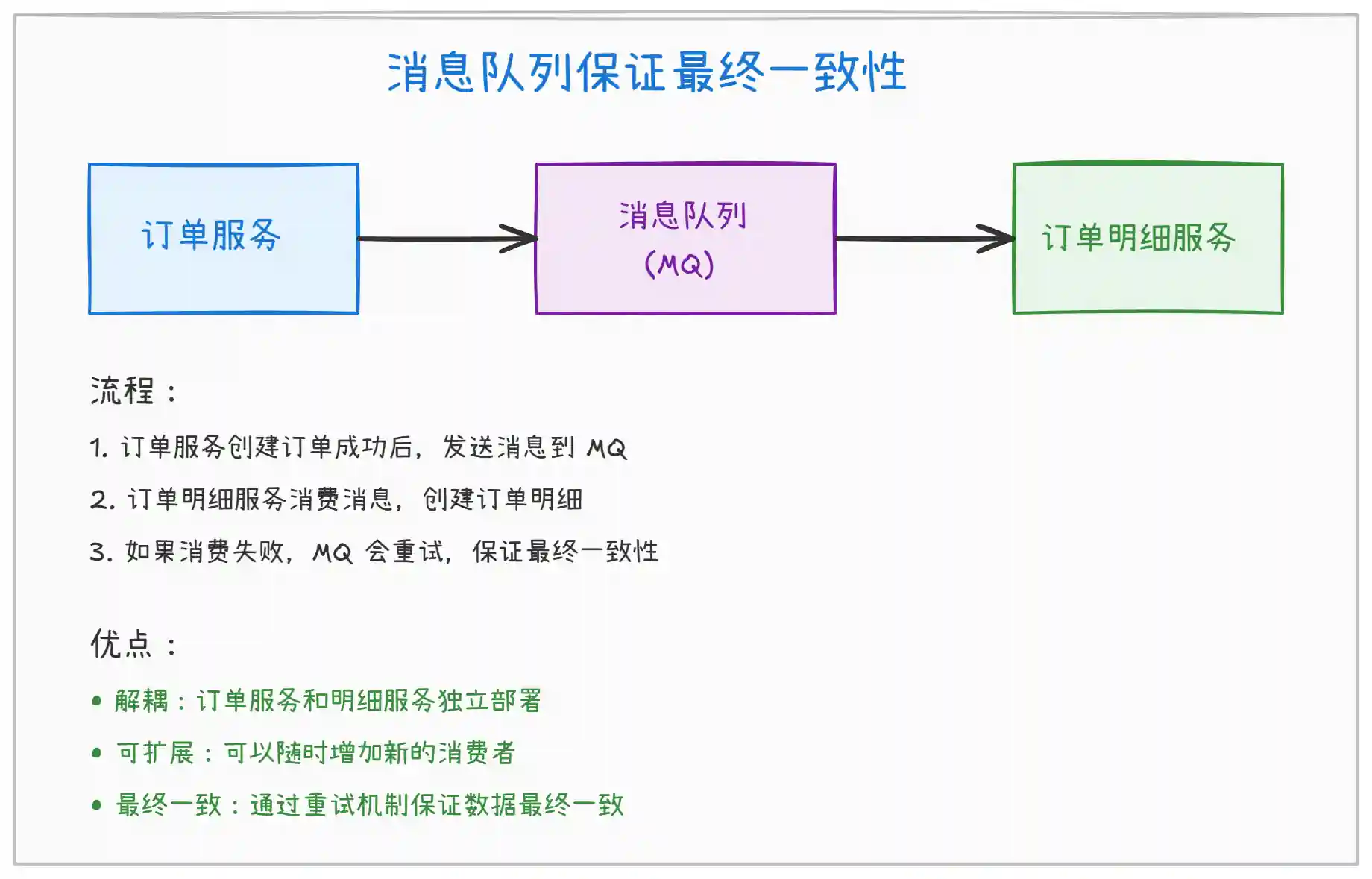
方案三:使用消息队列保证最终一致性
五、什么场景可以用外键?
虽然大厂不推荐,但外键并非一无是处,以下场景可以考虑使用:
| 场景 | 是否推荐外键 | 原因 |
|---|---|---|
| 单机小系统 | ✅ 可以用 | 数据量小、无分库分表需求、简化开发 |
| 强一致性要求 | ✅ 可以用 | 数据库层面的约束最可靠 |
| 高并发系统 | ❌ 不推荐 | 锁竞争影响性能 |
| 分库分表系统 | ❌ 不可用 | 跨库外键无效 |
| 微服务架构 | ❌ 不可用 | 服务独立数据库 |
面试高频追问
-
追问一:不用外键如何保证数据一致性?
- 答:应用层校验 + 事务控制 + 消息队列保证最终一致性。对于强一致性场景,可以使用分布式事务(Seata、TCC);对于弱一致性场景,可以异步处理 + 定期补偿。
-
追问二:外键一定不能用吗?有没有适用场景?
- 答:单机、小数据量、强一致性要求的场景可以用。比如内部管理系统、ERP 系统等,数据量和并发都不高,用外键可以简化开发。
-
追问三:
ON DELETE CASCADE级联删除有什么问题?- 答:级联删除会在删除父记录时自动删除子记录,但这是隐式的,容易造成误删;而且大批量级联删除会长时间锁表,影响系统可用性。建议在应用层显式处理删除逻辑。
常见面试变体
- "为什么阿里开发手册禁止使用外键?"
- "外键对性能有什么影响?"
- "分库分表后如何保证数据一致性?"
- "不用外键如何维护表之间的关联关系?"
记忆口诀
外键不推荐的原因:
- 性能差:每次写入都要检查约束
- 锁竞争:父表加共享锁,影响并发
- 死锁多:跨表操作容易死锁
- 难扩展:分库分表外键失效
总结
外键通过数据库约束保证参照完整性,但代价是 性能开销、锁竞争、死锁风险、无法分库分表。互联网高并发场景普遍在 应用层维护关联关系,通过业务代码校验、消息队列、分布式事务等方式保证数据一致性。只有单机小系统、强一致性需求的场景才考虑使用外键。