谈谈 Redis ZSet 底层实现?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道 ZSet 是什么,更是想知道你是否了解 ZSet 底层的 两种实现(
ziplist/listpack+skiplist)以及各自的触发条件。 -
原理理解深度:考察你是否真正理解 跳表(Skip List) 的结构(多层索引、随机层数、O(logN) 查找),以及 Redis 为什么选择跳表而不是红黑树来实现有序集合。
-
版本演进认知:是否知道 Redis 7.0 将
ziplist替换为listpack,以及为什么要换。
核心答案
Redis ZSet(有序集合)底层使用 两种数据结构 实现,根据元素数量和大小自动切换:
| 条件 | 底层结构 | 特点 |
|---|---|---|
| 元素数量 ≤ 128 且每个元素 ≤ 64 字节 | ziplist(Redis 7.0 前)/ listpack(Redis 7.0+) |
紧凑存储,省内存,适合小数据量 |
| 元素数量 > 128 或有元素 > 64 字节 | skiplist(跳表)+ dict(字典) |
O(logN) 查找,适合大数据量 |
一句话结论:ZSet 的核心是 跳表 + 字典 的组合结构。跳表负责按分数范围查询(O(logN)),字典负责按成员查分数(O(1)),两者配合实现了 ZSet 的所有操作。
深度解析
一、ZSet 的整体架构
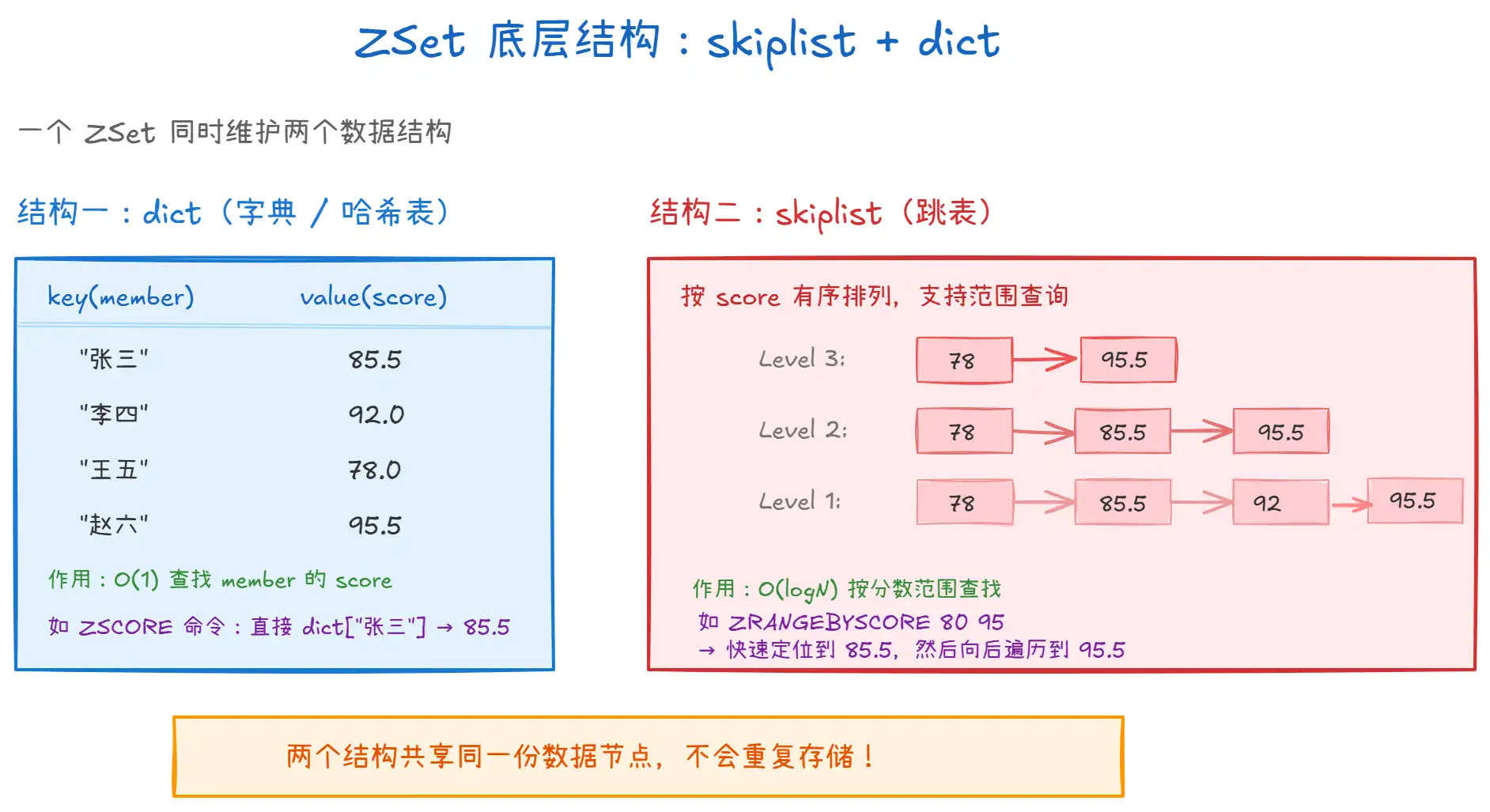
上图展示了 ZSet 的核心架构 —— 跳表 + 字典的组合:
- 字典(dict):以 member 为 key、score 为 value 的哈希表。作用是实现 O(1) 按 member 查 score,比如执行
ZSCORE命令时,直接通过字典查找,不需要遍历。 - 跳表(skiplist):按 score 有序排列的多层链表。作用是实现 O(logN) 的范围查询,比如执行
ZRANGEBYSCORE、ZRANK等命令时,跳表能快速定位。 - 两个结构共享同一份数据:字典的 value 和跳表的节点都指向同一个包含 member + score 的数据对象,不会重复存储两份,节省内存。
二、跳表(Skip List)详解
跳表是 ZSet 最核心的数据结构,面试必问。
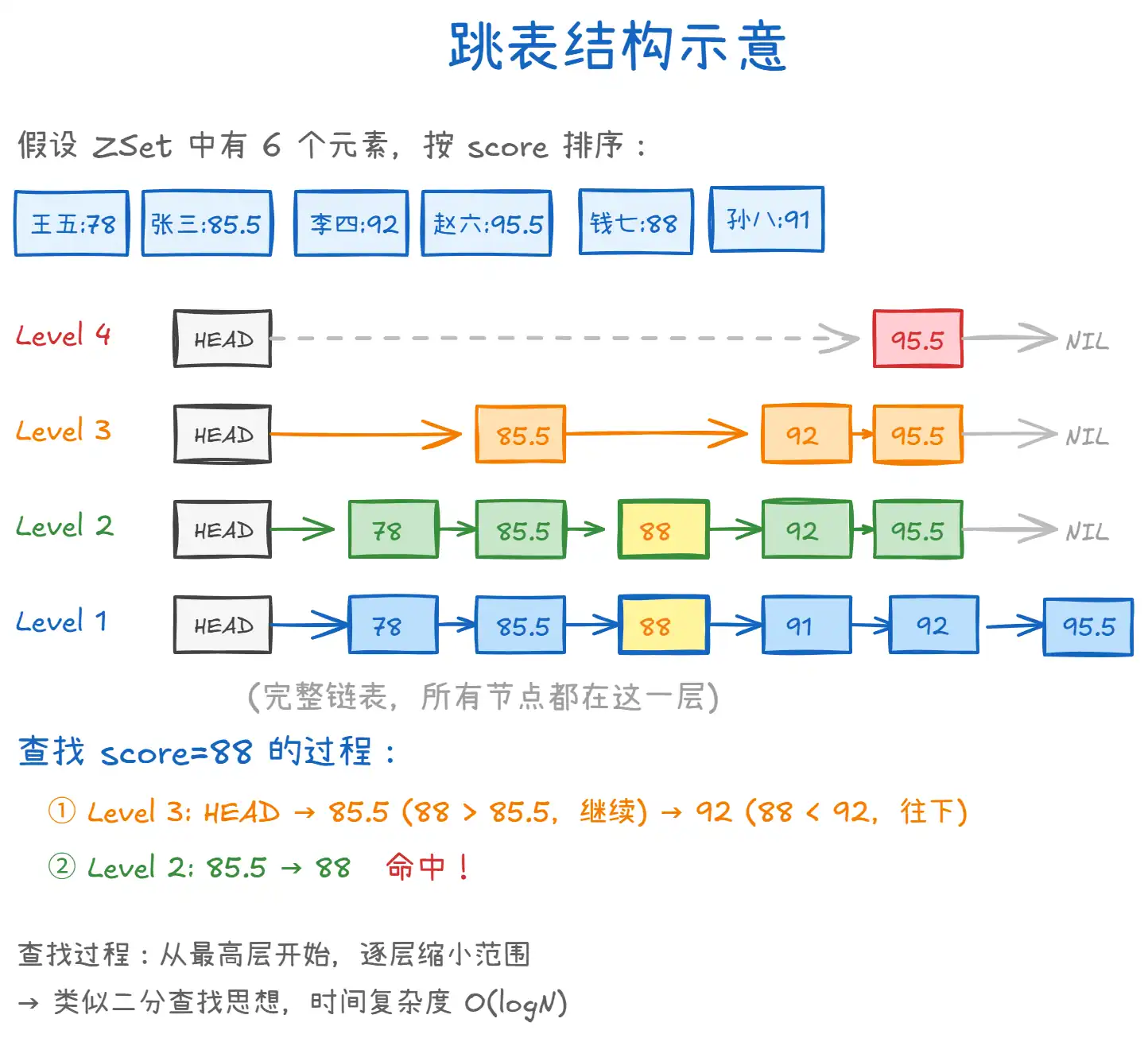
上图展示了跳表的核心结构:
- 多层索引:跳表在有序链表的基础上,建立了多层 "快车道"。高层节点少但跨度大,低层节点多但粒度细。查找时从最高层开始,如果目标比当前节点大就往右走,比当前节点小就往下走,逐层缩小范围。
- 随机层数:每个新节点插入时,通过随机算法决定它的层数。Redis 中每个节点有 25% 的概率再往上一层延伸,层数越高节点越稀疏。最高 32 层。
- 查找过程:从最高层开始,逐层二分缩小范围,时间复杂度 O(logN)。比遍历链表的 O(N) 快得多。
跳表节点的源码结构(Redis 7.x):
// 跳表节点定义(源码 t_zset.c)
typedef struct zskiplistNode {
sds ele; // 成员对象(member)
double score; // 分值
struct zskiplistNode *backward; // 后退指针(Level 1 的前驱)
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度(到下一个节点的距离)
} level[]; // 层数组,柔性数组
} zskiplistNode;
// 跳表定义
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头尾节点
unsigned long length; // 节点数量
int level; // 最大层数
} zskiplist;
关键字段解释:
ele:存储 member(如 "张三")。score:存储分值(如 85.5),跳表按此字段排序。backward:后退指针,只在最底层(Level 1)使用,支持从尾向头遍历(如ZREVRANGE)。level[]:柔性数组,每个元素包含forward(前进指针)和span(跨度)。span用于计算排名,ZRANK命令就是通过累加 span 得到的。header:跳表有一个特殊的头节点,不存储数据,它的层数始终等于跳表的最大层数。
三、跳表的核心操作

上图总结了跳表的四种核心操作:
- 查找:从最高层开始逐层二分,时间复杂度 O(logN)。这是
ZSCORE、ZRANK等命令的基础。 - 插入:先找到插入位置,然后随机生成新节点层数,更新每层的前后指针。同时往字典中插入一条记录。时间复杂度 O(logN)。
- 删除:先找到目标节点,更新每层指针跳过被删节点,释放内存。同时从字典中删除。时间复杂度 O(logN)。
- 范围查询:先用跳表定位到起始 score(O(logN)),然后沿 Level 1 链表向后遍历 M 个元素。总时间复杂度 O(logN + M),M 为结果集大小。
四、为什么 Redis 用跳表而不用红黑树?
这是面试中 最常被追问 的问题。
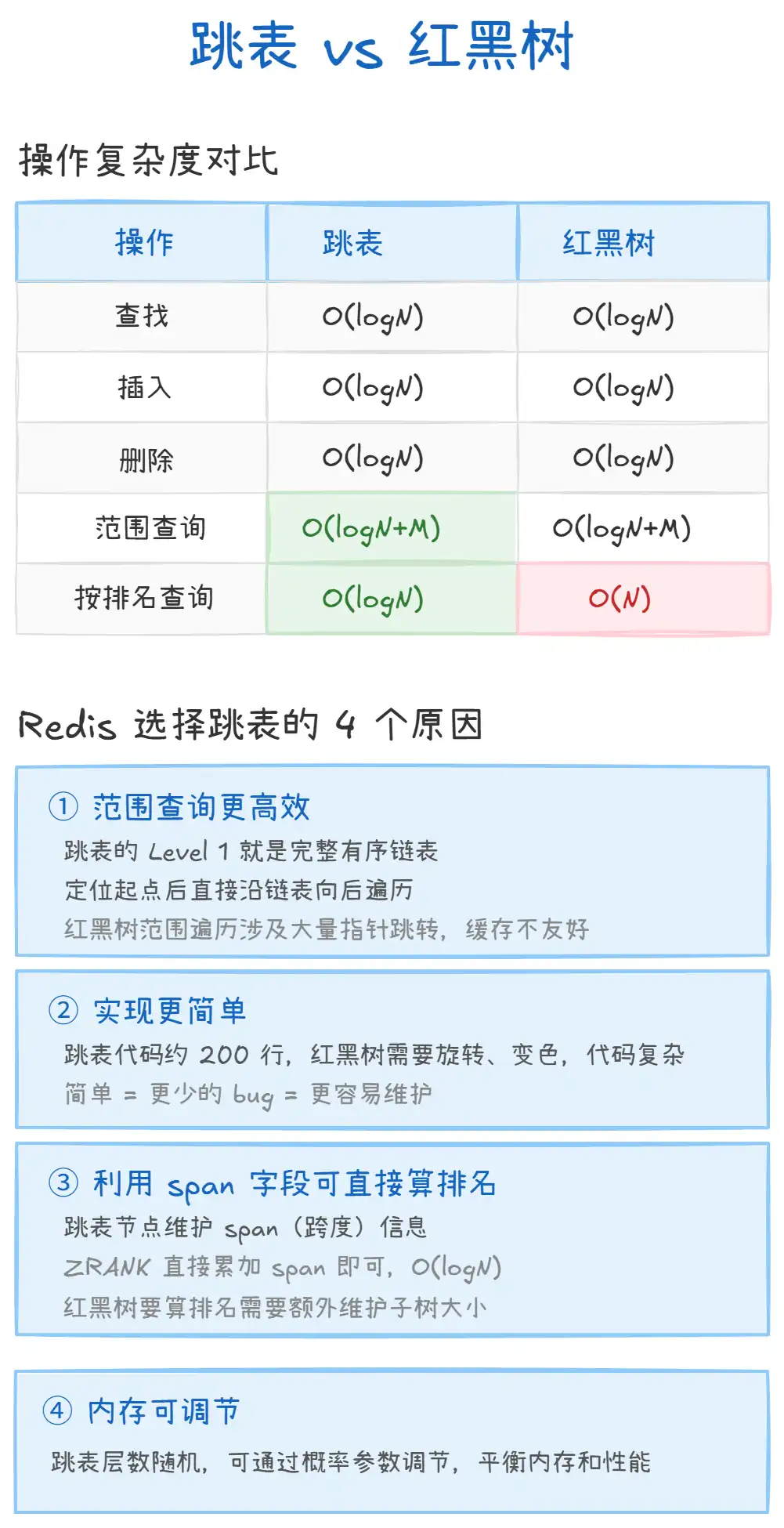
上图对比了跳表和红黑树的核心差异:
- 范围查询更高效:跳表的最底层就是完整的有序链表,定位起点后直接向后遍历即可,内存连续访问对 CPU 缓存友好。红黑树做范围查询需要中序遍历,涉及大量左右子树指针跳转,缓存不友好。ZSet 最常用的操作就是范围查询(
ZRANGE、ZRANGEBYSCORE),跳表在这方面有天然优势。 - 实现更简单:跳表的插入和删除只需要修改前后指针,不需要复杂的旋转和变色操作。Redis 作者 antirez 曾明确表示,跳表的代码更简洁、更容易理解和维护。
- 排名计算更方便:跳表通过
span字段可以 O(logN) 计算排名,而红黑树需要额外维护子树大小信息(类似 Order Statistic Tree),增加实现复杂度。 - 内存可调节:通过调整随机层数的概率参数(Redis 默认 0.25),可以在内存占用和查找性能之间灵活权衡。
五、ziplist / listpack(小数据量的紧凑存储)
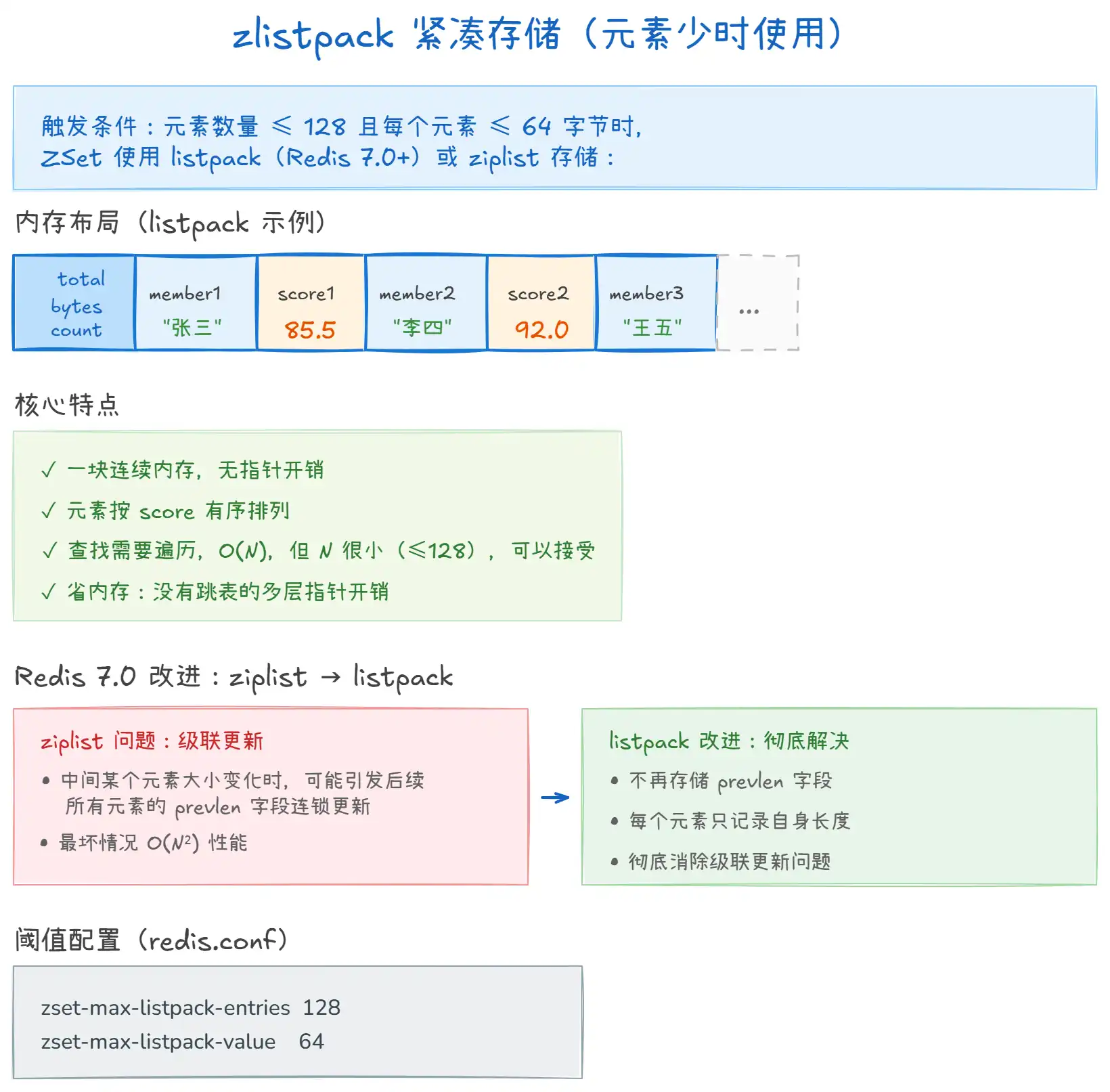
上图展示了 ZSet 在元素较少时的紧凑存储方式:
- listpack(Redis 7.0+):一块连续内存,member 和 score 交替排列,没有指针开销。元素按 score 有序排列,查找需要遍历但 N 很小(≤128),完全可以接受。
- ziplist 的问题:旧版
ziplist的每个元素头部存储了前一个元素的长度(prevlen),当前一个元素大小变化时,可能引发后续所有元素的prevlen字段连锁更新,最坏 O(N²)。 - listpack 的改进:不再存储
prevlen,每个元素只记录自己的长度,彻底消除了级联更新问题。 - 阈值可配置:
zset-max-listpack-entries控制最大元素数量,zset-max-listpack-value控制最大元素大小。超过任一阈值就会转换为跳表。
六、ZSet 常用命令与底层操作对应
| 命令 | 功能 | 底层操作 | 复杂度 |
|---|---|---|---|
ZADD |
添加元素 | dict 插入 + skiplist 插入 | O(logN) |
ZSCORE |
查分数 | 直接查 dict | O(1) |
ZRANK |
查排名 | skiplist 累加 span | O(logN) |
ZRANGE |
按排名范围查 | skiplist 遍历 | O(logN + M) |
ZRANGEBYSCORE |
按分数范围查 | skiplist 定位 + 遍历 | O(logN + M) |
ZREM |
删除元素 | dict 删除 + skiplist 删除 | O(logN) |
ZCARD |
元素总数 | 直接读 length | O(1) |
ZCOUNT |
分数范围内数量 | skiplist 定位两端 | O(logN) |
关键点:
ZSCORE和ZCARD是 O(1),因为字典直接查、length字段直接读。- 范围查询都是 O(logN + M),先用跳表定位起点,然后沿链表遍历 M 个元素。
面试高频追问
-
追问一:跳表的层数是怎么确定的?
每次插入新节点时,通过随机算法决定层数。Redis 使用的是 幂次定律(power law):每个节点有 25% 的概率再往上一层延伸,最多 32 层。这意味着大约 75% 的节点只有 1 层,25% 有 2 层,6.25% 有 3 层……层数越高节点越稀疏,从而保证查找效率接近 O(logN)。
-
追问二:ZSet 中 member 相同、score 不同会怎样?
ZSet 中每个 member 是唯一的。如果
ZADD一个已存在的 member 但 score 不同,Redis 会 更新 score(先从跳表旧位置删除,再按新 score 插入新位置),同时更新字典中的 score。 -
追问三:ziplist 和 listpack 的区别?为什么要替换?
核心区别在于
prevlen字段。ziplist 每个元素头部存储了前一个元素的长度,当前一个元素从 < 254 字节变为 ≥ 254 字节时,prevlen从 1 字节变为 5 字节,可能引发后续所有元素的连锁更新(级联更新),最坏 O(N²)。listpack 去掉了prevlen,每个元素只记录自身长度,彻底消除了这个问题。Redis 7.0 将所有使用 ziplist 的地方都替换成了 listpack。
常见面试变体
- 变体一:"Redis 为什么用跳表而不用红黑树?"
- 变体二:"ZSet 的底层实现是什么?"
- 变体三:"跳表的时间复杂度是多少?查找过程是怎样的?"
- 变体四:"Redis 7.0 的 listpack 和 ziplist 有什么区别?"
记忆口诀
ZSet 底层:小数据用 listpack(省内存),大数据用 skiplist + dict(高性能)。
跳表核心:多层索引 + 随机层数,O(logN) 查找,范围查询天然友好。
选跳表不选红黑树:范围查询快、实现简单、排名方便、内存可调。
两个结构各司其职:dict 管 O(1) 按 member 查 score,skiplist 管 O(logN) 按 score 范围查询。
总结
Redis ZSet 底层采用 跳表 + 字典 的组合结构(元素少时用 listpack)。字典实现 O(1) 按 member 查 score,跳表实现 O(logN) 的范围查询和排名计算。Redis 选择跳表而非红黑树,是因为跳表在范围查询、实现复杂度、排名计算等方面都有优势。Redis 7.0 用 listpack 替换了 ziplist,彻底解决了级联更新问题。