Redis 如何高效安全的遍历所有 Key?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道
SCAN命令怎么用,更是想知道你是否清楚KEYS *为什么在生产环境被禁用,以及SCAN基于游标的增量遍历是如何做到不阻塞 Redis 的。 -
原理理解深度:考察你是否了解
SCAN的底层实现(字典高位翻转算法)、为什么可能返回重复元素、为什么可能漏掉新增的 Key,以及COUNT参数的真正含义。 -
生产实践经验:能否给出完整的遍历方案(如批量删除匹配的 Key、大 Key 扫描),并知道如何处理
SCAN的各种边界情况。
核心答案
| 方式 | 命令 | 阻塞性 | 生产可用 | 适用场景 |
|---|---|---|---|---|
| 全量遍历 | KEYS pattern |
❌ 严重阻塞 | ⚠️ 禁止 | 仅调试 / 数据量极小 |
| 增量遍历 | SCAN cursor [MATCH] [COUNT] |
✅ 不阻塞 | ✅ 推荐 | 生产环境遍历 |
| 类型扫描 | SSCAN / HSCAN / ZSCAN |
✅ 不阻塞 | ✅ 推荐 | 遍历集合 / 哈希 / 有序集合 |
一句话结论:生产环境 严禁使用 KEYS,必须用 SCAN 系列命令 基于游标增量遍历,每次只返回少量结果,不阻塞 Redis 主线程。
深度解析
一、为什么 KEYS 命令不能用于生产?

上图展示了 KEYS 命令的危害:
- 单线程阻塞:Redis 用单线程处理命令,
KEYS必须遍历完所有 Key 才能返回,期间其他所有客户端的请求都被阻塞。 - 内存暴涨:如果有 1000 万个 Key,返回结果可能占用数百 MB 内存。
- 级联故障:阻塞导致上游服务超时,超时导致重试,重试又加重 Redis 负载,最终可能引发雪崩。
结论:KEYS 只适合在数据量极小的开发 / 测试环境使用,生产环境严禁使用。
二、SCAN 命令的工作原理
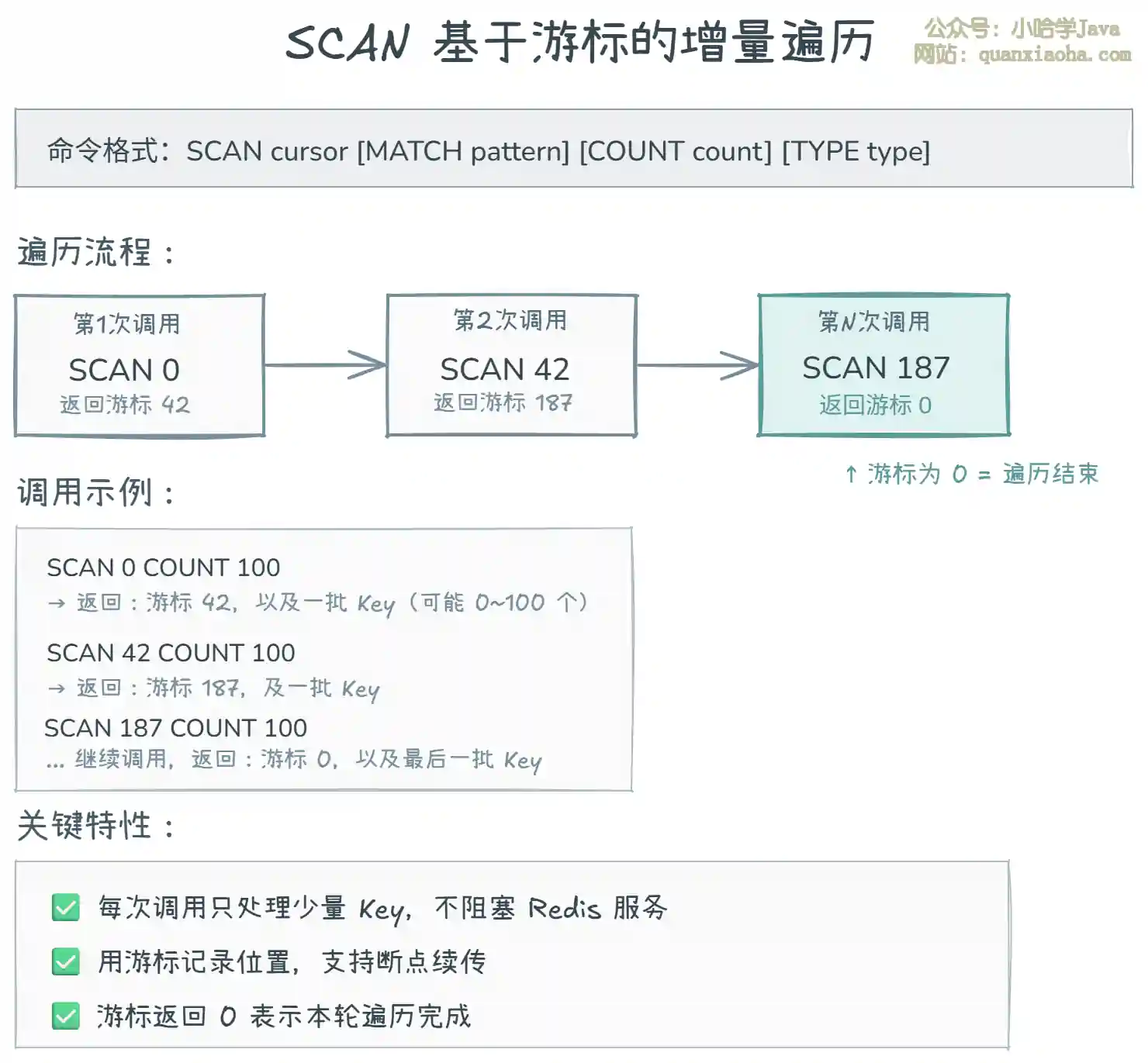
上图展示了 SCAN 的游标遍历机制:
- 游标从 0 开始:第一次调用
SCAN 0,表示开始遍历。 - 返回新游标:每次调用返回一个新游标和一批 Key。下次调用使用新游标继续遍历。
- 游标为 0 结束:当返回的游标为 0 时,表示遍历完成。
- 不阻塞:每次调用只处理一小批 Key(由
COUNT控制),处理完就返回,不阻塞其他客户端。
三、SCAN 的三个重要特性(面试必问)
特性一:可能返回重复的 Key

上图解释了 SCAN 可能返回重复 Key 的原因:
SCAN的游标算法不是简单的 "桶编号 +1",而是 高位翻转(将桶编号的二进制位反转后加 1)。这种设计是为了在 rehash 时仍然能正确遍历。- 当遍历过程中发生了 rehash(哈希表扩容或缩容),某些 Key 可能从旧位置迁移到了新位置,导致被访问两次,返回重复。
- 解决方案:客户端需要自行去重,通常用
HashSet记录已经见过的 Key。
特性二:可能漏掉新增的 Key
遍历期间新增的 Key 有可能不会被返回。因为游标算法是按照固定的跳跃顺序遍历桶,如果新 Key 被放入了已经遍历过的桶中,就会被跳过。这是 SCAN 的设计取舍:保证不阻塞,牺牲一定的完整性。
特性三:COUNT 不是精确返回数量
COUNT 只是 建议值,告诉 Redis "大约每次扫描多少个元素"。实际返回的 Key 数量可能远少于 COUNT(比如 COUNT 100 可能只返回 10 个 Key),因为大部分元素可能不匹配 MATCH 过滤条件。也可能多于 COUNT(在 rehash 场景下)。
四、SCAN 系列命令全家桶
| 命令 | 遍历对象 | 示例 |
|---|---|---|
SCAN |
遍历整个数据库的所有 Key | SCAN 0 MATCH user:* COUNT 100 |
SSCAN |
遍历 Set 的所有元素 | SSCAN myset 0 COUNT 100 |
HSCAN |
遍历 Hash 的所有 field-value | HSCAN myhash 0 MATCH field:* COUNT 100 |
ZSCAN |
遍历 Sorted Set 的所有 member-score | ZSCAN myzset 0 COUNT 100 |
五、生产实战:批量删除匹配的 Key
这是 SCAN 最常见的生产场景 —— 比如需要删除所有 temp:* 前缀的 Key:
/**
* 安全批量删除匹配的 Key
* 使用 SCAN 增量遍历 + Pipeline 批量删除
*/
public long safeDeleteKeys(String pattern) {
long deletedCount = 0;
Set<String> batch = new HashSet<>();
String cursor = "0";
do {
// 1. SCAN 增量扫描
ScanResult<String> scanResult = jedis.scan(
cursor,
new ScanParams().match(pattern).count(100)
);
cursor = scanResult.getCursor();
List<String> keys = scanResult.getResult();
if (!keys.isEmpty()) {
batch.addAll(keys);
// 2. 积累到一定数量后批量删除(减少网络开销)
if (batch.size() >= 500) {
deletedCount += batch.size();
Pipeline pipeline = jedis.pipelined();
for (String key : batch) {
pipeline.del(key);
}
pipeline.sync();
batch.clear();
}
}
} while (!"0".equals(cursor)); // 游标为 0 表示遍历结束
// 3. 删除剩余的 Key
if (!batch.isEmpty()) {
deletedCount += batch.size();
Pipeline pipeline = jedis.pipelined();
for (String key : batch) {
pipeline.del(key);
}
pipeline.sync();
}
return deletedCount;
}
// 使用示例:删除所有 temp: 开头的 Key
long count = safeDeleteKeys("temp:*");
System.out.println("删除了 " + count + " 个 Key");
关键点:
- 用
SCAN代替KEYS:增量遍历,不阻塞 Redis。 - 用 Pipeline 批量删除:减少网络 RTT,不用每删一个 Key 就发一次请求。
- 客户端去重:用
HashSet收集 Key,避免 SCAN 返回重复时重复删除。 - 分批提交:积累 500 个 Key 后批量删除,避免一次性删除太多导致短暂阻塞。
面试高频追问
-
追问一:
SCAN的COUNT设多少合适?默认值是 10,生产环境一般设 100~1000。设太小会增加遍历次数和网络开销;设太大会增加单次处理时间。对于百万级 Key 的数据库,
COUNT 100通常每轮只需几毫秒,不会影响 Redis 性能。如果 Key 特别多(千万级),可以适当增大到 500~1000。 -
追问二:Redis Cluster 中
SCAN怎么用?Redis Cluster 有 16384 个 slot,每个节点只负责一部分 slot。需要在 每个主节点上分别执行
SCAN(可以用CLUSTER NODES获取所有主节点地址),汇总结果。或者使用redis-cli --scan --pattern "xxx:*"命令,它会自动遍历所有节点。 -
追问三:
KEYS真的一点用都没有吗?在以下场景可以有限度使用:数据量极小的本地开发 / 测试环境;确认数据库只有几十个 Key 的维护脚本。但任何可能连接生产环境的代码,都不应该使用
KEYS。
常见面试变体
- 变体一:"生产环境如何安全地批量删除 Key?"
- 变体二:"Redis
SCAN命令了解吗?和KEYS的区别?" - 变体三:"
SCAN遍历过程中有新增 Key 会怎样?" - 变体四:"如何在线上扫描 Redis 中的大 Key?"
记忆口诀
KEYS:一次全扫,阻塞全场 —— "核武器,生产禁用"。
SCAN:游标分批,不阻塞 —— "机关枪,点射模式"。
三大特性:可能重复(客户端去重)、可能遗漏(设计取舍)、COUNT 不精确(只是建议值)。
核心模式:SCAN + Pipeline + 客户端去重 = 生产安全的批量操作。
总结
生产环境遍历 Redis 的所有 Key 必须使用 SCAN,严禁使用 KEYS。SCAN 基于游标增量遍历,每次只处理少量 Key,不阻塞 Redis 主线程。需要注意 SCAN 的三个特性:可能返回重复 Key(需客户端去重)、可能遗漏新增 Key、COUNT 只是建议值。实际使用时配合 Pipeline 批量操作,可以高效安全地完成批量删除、批量扫描等运维任务。