谈谈 Redis 的内存淘汰策略?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观

面试考察点
-
基础掌握度:面试官不仅仅是想知道有哪些淘汰策略,更是想知道你是否能说清楚 8 种策略各自的淘汰范围(
allkeysvsvolatile)和淘汰算法(lruvslfuvsrandomvsttl),以及生产环境怎么选。 -
原理理解深度:考察你是否知道 Redis 的 LRU 不是精确的 LRU,而是近似算法(随机采样 + 淘汰最旧),以及 Redis 4.0 引入的 LFU 是如何基于计数器实现的。
-
知识体系完整性:能否区分 "过期策略"(惰性 + 定期,针对有过期时间的 Key)和 "淘汰策略"(内存满了怎么办,针对所有 Key),以及它们的触发时机不同。
核心答案
Redis 提供了 8 种 内存淘汰策略,当内存使用达到 maxmemory 上限时触发:
| 策略 | 淘汰范围 | 淘汰算法 | 适用场景 |
|---|---|---|---|
noeviction |
不淘汰 | 直接拒绝写入 | 数据不能丢失(默认) |
allkeys-lru |
所有 Key | 最近最少使用 | 通用缓存(推荐) |
allkeys-lfu |
所有 Key | 最不经常使用(4.0+) | 热点明显的缓存 |
allkeys-random |
所有 Key | 随机淘汰 | 无明显访问热点 |
volatile-lru |
仅过期 Key | 最近最少使用 | 部分数据可丢 |
volatile-lfu |
仅过期 Key | 最不经常使用(4.0+) | 部分数据可丢 |
volatile-random |
仅过期 Key | 随机淘汰 | 部分数据可丢 |
volatile-ttl |
仅过期 Key | 剩余时间最短 | 业务有明确 TTL 需求 |
一句话结论:生产环境做缓存用 allkeys-lru,热点明显用 allkeys-lfu;做存储(数据不能丢)用 noeviction 并做好容量规划。
深度解析
一、过期策略 vs 淘汰策略:别搞混了
很多人分不清这两个概念,面试时先说清楚区别是一个加分项。

上图清晰地展示了两者的区别:
- 过期策略是 "Key 到期了怎么处理",只管设置了过期时间的 Key。
- 淘汰策略是 "内存满了怎么办",在过期策略清理后内存仍然不够时触发,负责主动踢出一些 Key 来给新数据腾空间。
二、8 种策略的分类体系
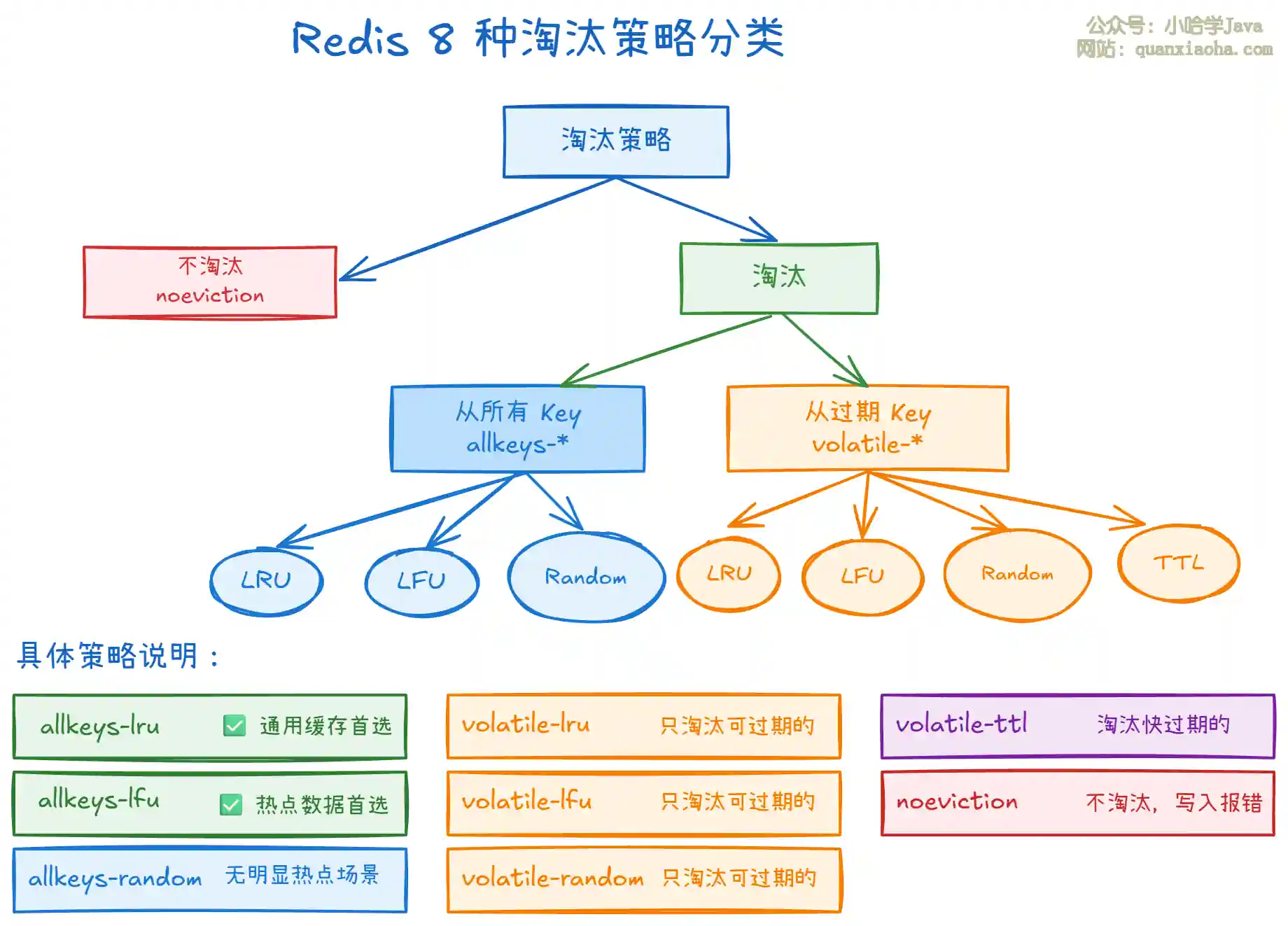
上图按分类维度整理了 8 种策略。理解的关键在于两个维度:
- 淘汰范围:
allkeys-*从所有 Key 中选(包括没设过期的),volatile-*只从设了过期时间的 Key 中选。 - 选择算法:
lru(最近最少使用)、lfu(最不经常使用)、random(随机)、ttl(剩余存活时间最短)。
三、LRU 算法:Redis 是近似的,不是精确的
标准的 LRU 算法需要一个 双向链表,每次访问都把数据移到链表头部,淘汰时直接删链表尾部。但 Redis 没有用这种方式,因为它需要额外的数据结构,且每次访问都要更新链表,开销大。
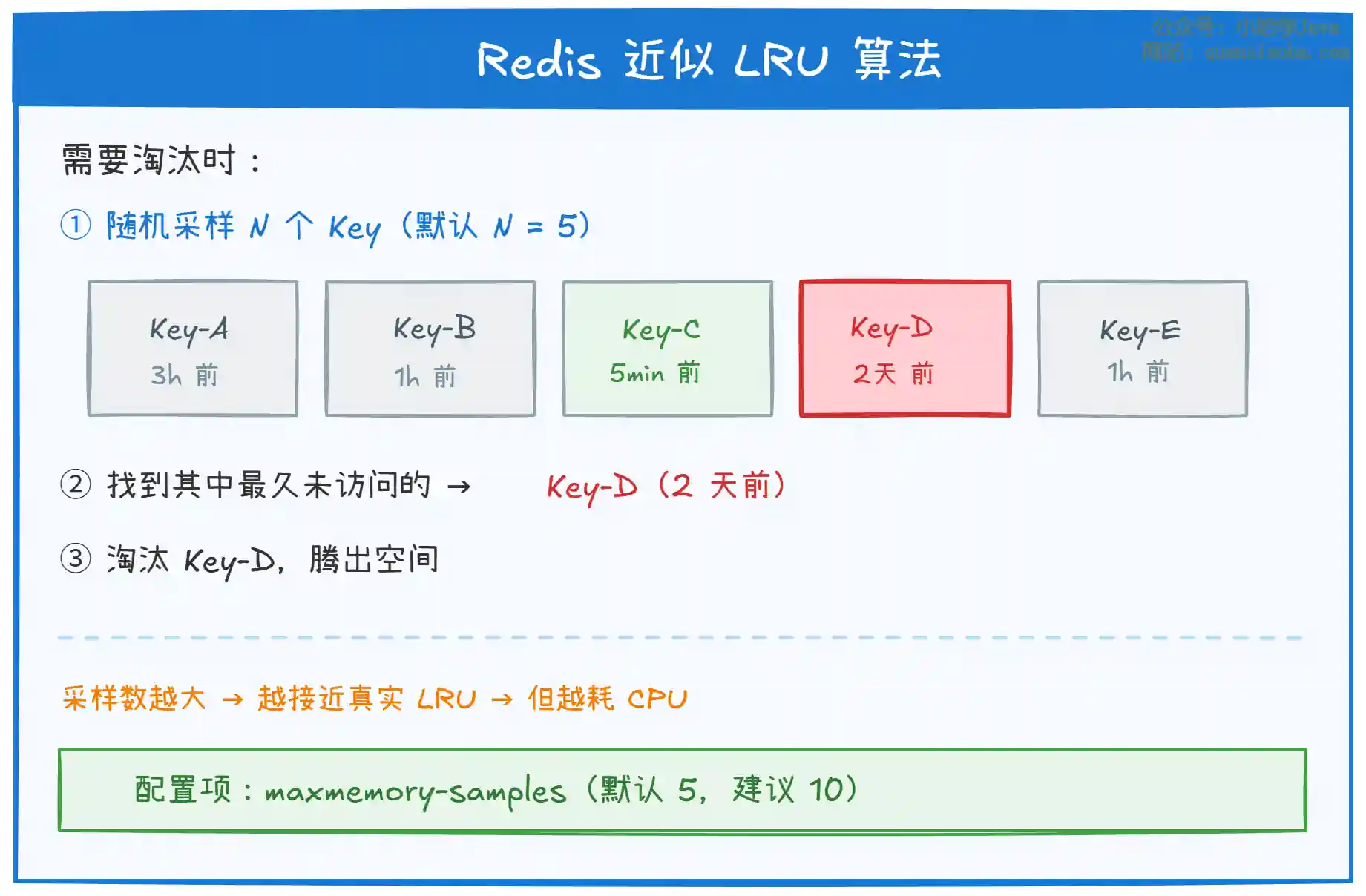
上图展示了 Redis 近似 LRU 的核心思路:
- 随机采样:每次需要淘汰时,随机抽取 N 个 Key(默认 5 个),从中淘汰最后一次访问时间最早的那个。
- 不是全局扫描:不会遍历所有 Key,所以效率很高,但结果不够精确。
- 采样数可调:通过
maxmemory-samples配置,值越大越接近真实 LRU,但 CPU 开销也越大。官方测试表明,采样数设为 10 时,效果已经非常接近真实 LRU。
四、LFU 算法:Redis 4.0 引入的 "热点感知"
LFU(Least Frequently Used)基于 "访问频率" 而非 "最近访问时间" 来决定淘汰谁,更适合 热点数据明显 的场景。

上图展示了 LFU 的计数器机制:
- 8 bit 计数器:范围 0~255,记录 Key 的 "逻辑访问频率"。不是每次访问都 +1,而是概率递增 —— 计数器越大,再增长的概率越低。这样新的热点 Key 有机会追赶老的。
- 16 bit 衰减时间:记录最后一次衰减的时间。每隔
lfu-decay-time分钟(默认 1 分钟),计数器减 1。这样长期不访问的 Key 的计数器会逐渐衰减,避免 "曾经热门但现在没人用" 的数据占着位置。
LRU vs LFU 对比:
| 维度 | LRU | LFU |
|---|---|---|
| 淘汰依据 | 最近访问时间 | 访问频率 |
| 适合场景 | 访问模式均匀 | 热点数据明显(20% 数据占 80% 流量) |
| 优点 | 实现简单,效果稳定 | 更精准识别热点 |
| 缺点 | 偶尔访问的冷数据可能顶掉热数据 | 需要调参(衰减时间、计数器增长率) |
| 配置参数 | maxmemory-samples |
lfu-decay-time + lfu-log-factor |
五、生产环境如何选型?
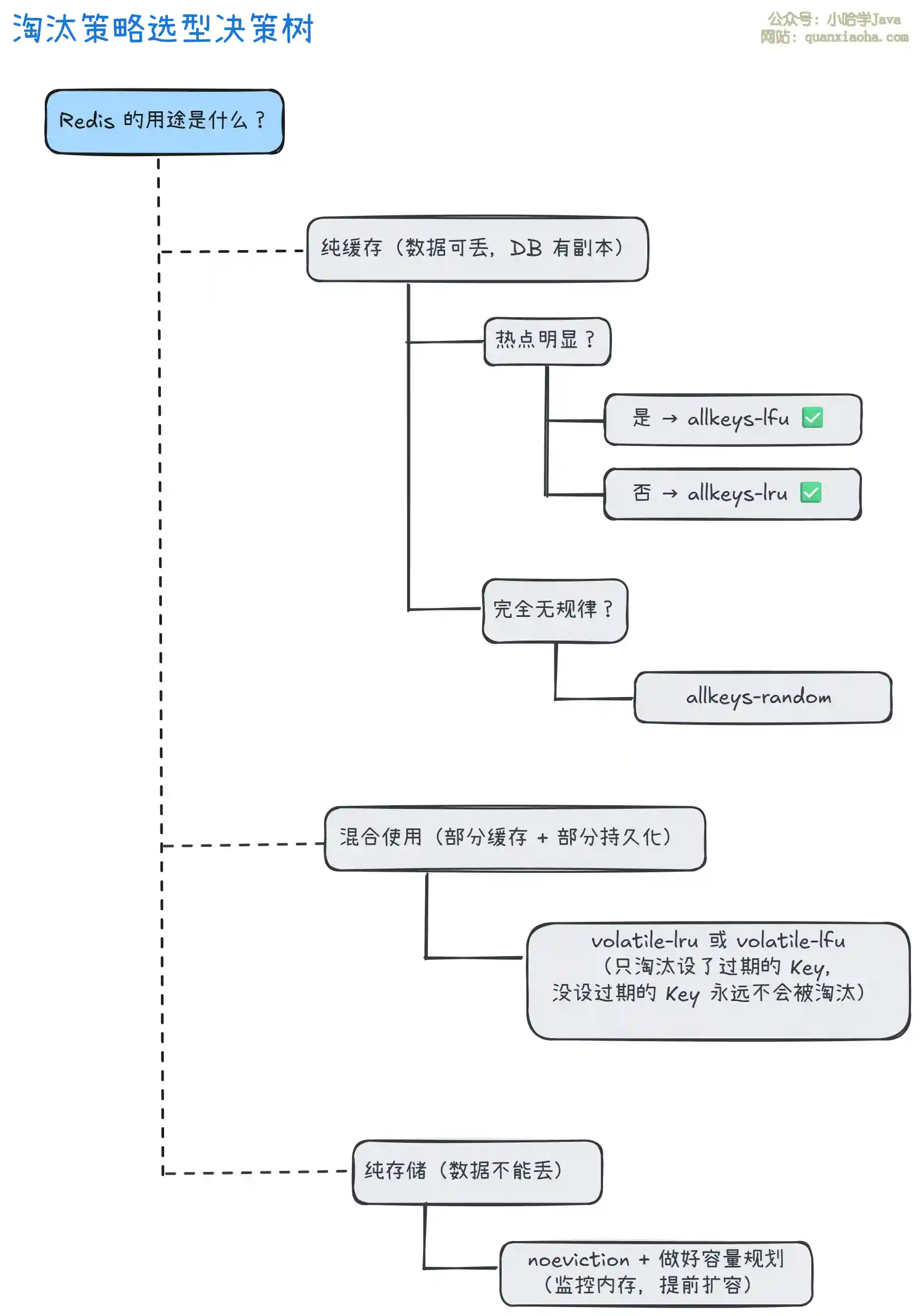
上图是一个简单的选型决策树,核心逻辑:
- 纯缓存场景:用
allkeys-*系列,因为缓存数据丢了可以重建。推荐allkeys-lru(通用)或allkeys-lfu(热点明显)。 - 混合使用场景:有些 Key 是缓存(可丢),有些是持久化数据(不能丢)。给缓存 Key 设置过期时间,用
volatile-lru,只淘汰设了过期的 Key。 - 纯存储场景:用
noeviction,但必须做好容量监控和提前扩容。
配置示例:
# redis.conf
# 设置最大内存(建议设为系统内存的 60%~70%)
maxmemory 4gb
# 设置淘汰策略
maxmemory-policy allkeys-lru
# LRU 采样数(越大越精确,但越耗 CPU)
maxmemory-samples 10
# LFU 相关参数(仅使用 LFU 时需要配置)
# 衰减时间(分钟),默认 1
lfu-decay-time 1
# 计数器增长因子,默认 10(越小增长越快)
lfu-log-factor 10
面试高频追问
-
追问一:
volatile-*策略有什么风险?如果所有 Key 都没有设置过期时间,
volatile-*策略就退化成了noeviction—— 找不到可淘汰的 Key,写入直接报错。所以如果你选了volatile-*,一定要确保需要被淘汰的 Key 都设置了过期时间,否则不如直接用allkeys-*。 -
追问二:Redis 的 LRU 和 Java
LinkedHashMap的 LRU 有什么区别?Java 的
LinkedHashMap可以通过重写removeEldestEntry()实现精确 LRU(每次访问都更新链表顺序)。Redis 为了高性能,用的是 近似 LRU(随机采样 + 淘汰最旧),不是全局排序,牺牲了一点精度换来更高的性能。 -
追问三:如何监控 Redis 的淘汰情况?
# 查看淘汰相关指标 INFO stats | grep evicted # evicted_keys:已淘汰的 Key 总数 # 查看当前内存和淘汰策略 INFO memory | grep maxmemory # maxmemory:最大内存限制 # maxmemory_policy:当前淘汰策略
常见面试变体
- 变体一:"Redis 内存满了怎么办?"
- 变体二:"Redis 的 LRU 算法是精确的吗?"
- 变体三:"LRU 和 LFU 的区别?生产环境怎么选?"
- 变体四:"
allkeys-lru和volatile-lru的区别?"
记忆口诀
8 种策略分两类:allkeys-*(全局选)和 volatile-*(过期里选)。
4 种算法:LRU(最久没用)、LFU(用得最少)、Random(随机)、TTL(快过期)。
生产首选:通用缓存 allkeys-lru,热点缓存 allkeys-lfu,不能丢数据 noeviction。
关键区别:过期策略 = "到期了怎么删",淘汰策略 = "内存满了踢谁"。
总结
Redis 内存淘汰策略共有 8 种,核心按 淘汰范围(allkeys vs volatile)和 选择算法(lru / lfu / random / ttl)两个维度划分。生产环境做缓存推荐 allkeys-lru(通用)或 allkeys-lfu(热点明显),做存储用 noeviction。Redis 的 LRU 是近似算法(随机采样),LFU 基于 8 bit 计数器 + 衰减机制,两者都在精度和性能之间取得了平衡。