什么是 MySQL 最左前缀匹配?为什么要遵守?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
原理理解:面试官不仅仅想知道你会背 "最左前缀原则",更想考察你是否理解联合索引的 B+ 树存储结构,能否从数据结构层面解释为什么必须遵循这个原则。
-
实践能力:是否能够正确设计联合索引的列顺序,避免索引失效,写出能走索引的高效 SQL。
-
问题排查:是否具备分析索引失效原因的能力,能否通过
EXPLAIN定位最左前缀相关问题。
核心答案
最左前缀匹配原则 是指:联合索引按照定义顺序从左到右依次匹配,查询条件必须从索引的最左列开始,并且不能跳过中间的列。
-- 联合索引
INDEX idx_a_b_c (a, b, c)
-- ✅ 能走索引
WHERE a = 1
WHERE a = 1 AND b = 2
WHERE a = 1 AND b = 2 AND c = 3
-- ❌ 不能走索引
WHERE b = 2 -- 缺少最左列 a
WHERE c = 3 -- 缺少 a 和 b
WHERE b = 2 AND c = 3 -- 缺少最左列 a
为什么要遵守:联合索引的 B+ 树是按照定义顺序构建的,先按第一列排序,第一列相同再按第二列排序,以此类推。跳过前面的列就无法利用索引的有序性。
一句话总结:联合索引像字典排序,必须从左边开始连续匹配,跳过前面的列就像在字典里直接翻 "中间的字",无法利用有序性。
深度解析
一、联合索引的 B+ 树结构

上图展示了联合索引在 B+ 树中的存储结构。核心要点:
-
全局有序 vs 局部有序:只有第一列
a是全局有序的,后面的列只在前面列相同的情况下才有有序性。 -
字典类比:想象一本字典,先按 "首字母" 排序,首字母相同再按 "第二个字母" 排序。如果你跳过首字母直接查第二个字母,字典的有序性就失效了。
-
二分查找的前提:B+ 树利用二分查找快速定位,前提是数据有序。跳过前面的列,后面的列无序,二分查找就失效了。
二、最左前缀匹配规则详解
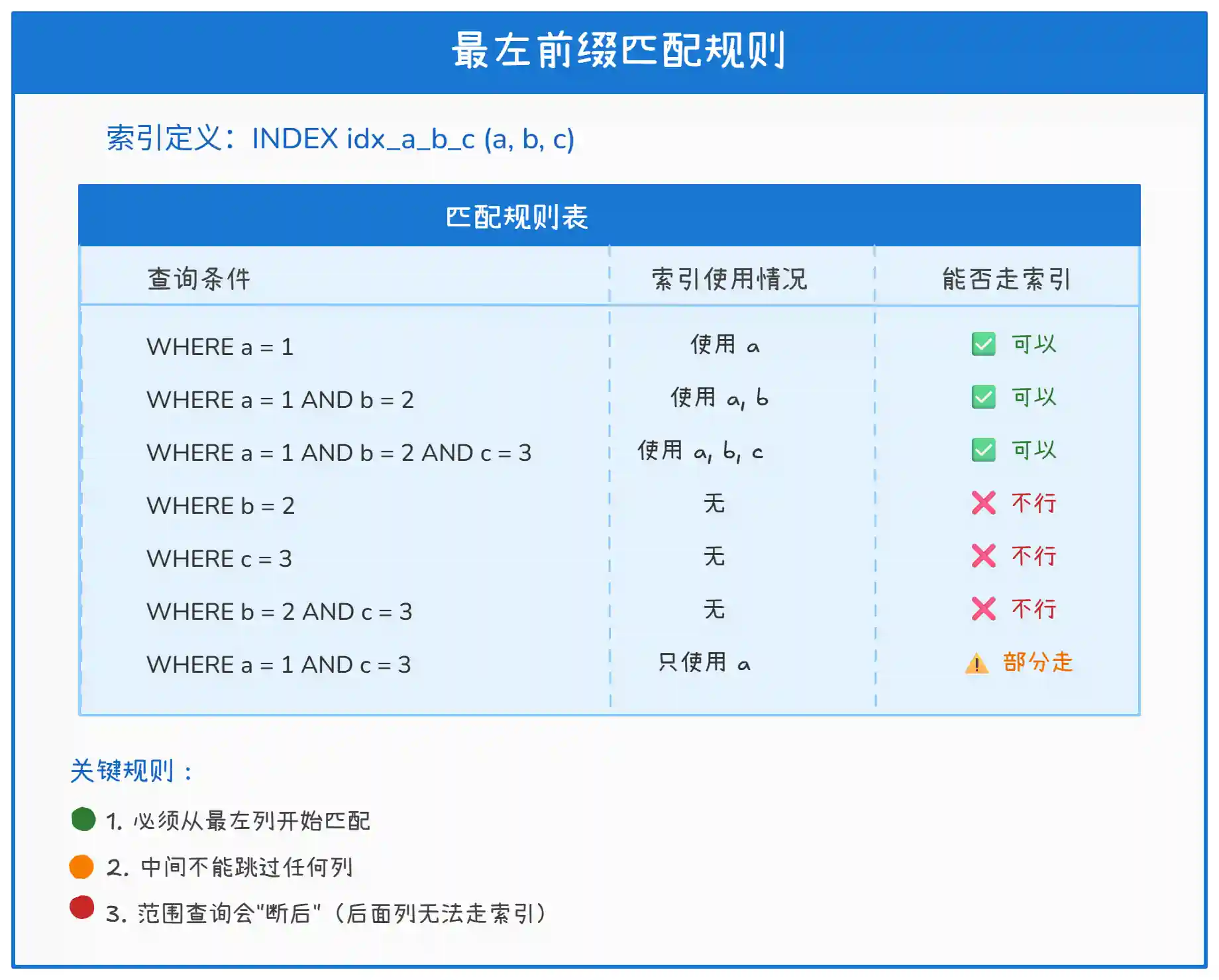
上图总结了最左前缀匹配的核心规则。具体说明:
-
规则一:必须从最左列开始。
WHERE b = 2缺少最左列a,无法利用索引的有序性,只能全表扫描。 -
规则二:中间不能跳过。
WHERE a = 1 AND c = 3跳过了b,只能使用a列的索引,c无法走索引。 -
规则三:范围查询会 "断后"。一旦出现范围查询(
>、<、BETWEEN、LIKE 'x%'),该列之后的索引列无法被使用。
三、范围查询 "断后" 问题
-- 索引:INDEX idx_a_b_c (a, b, c)
-- ✅ 三个列都能走索引
WHERE a = 1 AND b = 2 AND c = 3
-- ⚠️ 只能使用 a, b,c 无法走索引
WHERE a = 1 AND b > 2 AND c = 3
-- ↑ 范围查询,后面的 c "断了"
-- ✅ 范围查询放在最后,三个列都能利用索引
WHERE a = 1 AND b = 2 AND c > 3
原因分析:
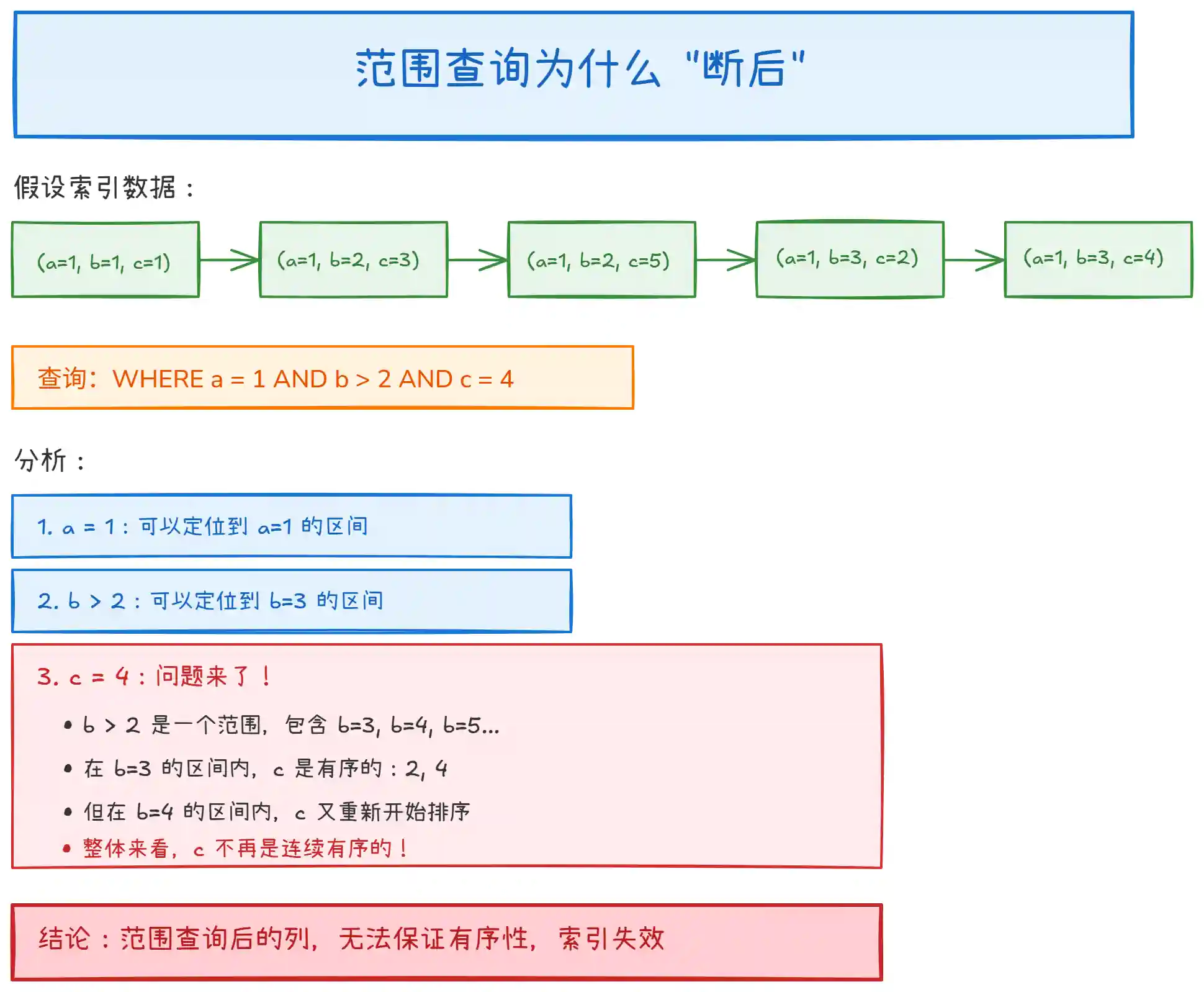
上图解释了范围查询 "断后" 的底层原因。核心问题:
-
范围查询筛选出的数据跨越了多个 "组",后面的列在这些组内分别有序,但整体无序。
-
无法利用 B+ 树的二分查找特性,只能逐条扫描。
四、最左前缀的实际应用
-- 场景:订单查询,常见查询条件组合
-- 查询模式分析
-- 1. 按用户查订单:WHERE user_id = ?
-- 2. 按用户+状态查:WHERE user_id = ? AND status = ?
-- 3. 按用户+时间范围查:WHERE user_id = ? AND create_time BETWEEN ? AND ?
-- ❌ 错误的索引设计
INDEX idx_status_user_time (status, user_id, create_time)
-- status 区分度低,放在最左边浪费
-- ✅ 正确的索引设计
INDEX idx_user_status_time (user_id, status, create_time)
-- user_id 区分度高,放在最左边
-- 等值条件在前,范围条件在后
设计原则:
| 原则 | 说明 | 示例 |
|---|---|---|
| 区分度高的列放前面 | 提高索引过滤效果 | user_id 比 status 区分度高 |
| 等值条件放前面 | 保证后面列能走索引 | WHERE a = 1 AND b > 2,a 放前面 |
| 范围条件放后面 | 避免 "断后" 问题 | create_time 放在联合索引最后 |
| 覆盖常用查询 | 一索引多查询 | 一个 (a,b,c) 可支持 a、a,b、a,b,c |
五、特殊情况:跳过索引列
-- 索引:INDEX idx_a_b_c (a, b, c)
-- MySQL 5.6+ 的索引下推优化
WHERE a = 1 AND c = 3
-- 没有 ICP:存储引擎返回所有 a=1 的记录,Server 层过滤 c=3
-- 有 ICP:存储引擎直接过滤 a=1 AND c=3,减少回表
-- EXPLAIN 结果
-- Extra: Using index condition(表示使用了索引下推)
注意:虽然 MySQL 5.6+ 有索引下推优化,但这只是在存储引擎层过滤数据,减少回表次数,并不是真正 "走索引"。c = 3 仍然无法利用索引的有序性快速定位。
六、常见误区

上图总结了最左前缀原则的常见误区。关键澄清:
-
条件顺序无关:MySQL 优化器会自动重排
WHERE条件,程序员不需要关心书写顺序。 -
SELECT 列不影响最左前缀:只影响是否使用覆盖索引(
Using index)。 -
OR 条件的陷阱:
OR条件通常导致全表扫描,因为无法保证所有条件都能走索引。 -
范围条件也适用:只是后面的列无法走索引,本身还是能用到索引的。
面试高频追问
-
联合索引 (a, b, c),WHERE a = 1 AND c = 3 能走索引吗?
- 只能走
a列的索引,c无法走索引。但 MySQL 5.6+ 会使用索引下推(ICP)在存储引擎层过滤c = 3,减少回表次数。
- 只能走
-
如何判断 SQL 是否走对了联合索引?
- 使用
EXPLAIN查看key(使用的索引名)、key_len(索引长度)。key_len可以判断使用了联合索引的几列。
- 使用
-
联合索引列顺序如何设计?
- 区分度高的列放前面、等值条件列放前面、范围条件列放后面、考虑查询频率和覆盖索引需求。
常见面试变体
- "为什么联合索引不遵循最左前缀就无法走索引?"
- "范围查询为什么会导致后面的索引列失效?"
- "索引下推是什么?和最左前缀有什么关系?"
记忆口诀
最左前缀三原则:必须从左始、中间不可跳、范围会断后
索引设计三要素:区分度高在前、等值在前范围后、覆盖常用查询模式
总结
最左前缀匹配原则是联合索引的核心使用规则,其根本原因是联合索引的 B+ 树按照定义顺序构建,先按第一列排序,第一列相同再按第二列排序。因此只有从最左列开始连续匹配,才能利用索引的有序性。实际应用中,应将区分度高的列、等值条件列放在前面,范围条件列放在后面,并通过 EXPLAIN 的 key_len 验证索引使用情况。