为什么不建议使用存储过程?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
架构思维:面试官不仅仅想知道存储过程有什么缺点,更想考察你是否具备分层架构意识,能否理解 "业务逻辑应该在应用层而非数据库层" 的设计原则。
-
工程实践:是否经历过存储过程带来的维护痛点,能否从调试、版本控制、团队协作等角度分析实际问题。
-
权衡能力:是否了解存储过程适用的场景,而非一刀切地否定,懂得根据业务特点做技术选型。
核心答案
现代互联网架构中,不建议使用存储过程,主要原因如下:
| 问题维度 | 具体表现 | 影响 |
|---|---|---|
| 可维护性 | 代码分散在应用和数据库,难以统一管理 | 排查问题困难 |
| 可调试性 | 缺乏完善的调试工具,日志难以追踪 | 定位 bug 成本高 |
| 可移植性 | 不同数据库语法差异大,迁移困难 | 技术绑定风险 |
| 扩展性 | 业务逻辑绑定数据库,难以水平扩展 | 性能瓶颈 |
| 团队协作 | DBA 和开发职责混淆,代码审查困难 | 开发效率低 |
| 版本控制 | SQL 代码难以纳入 Git 等版本管理 | 回滚困难 |
一句话总结:存储过程把业务逻辑下沉到数据库,违背了分层架构原则,导致维护难、调试难、扩展难。
深度解析
一、架构层面:违背分层原则
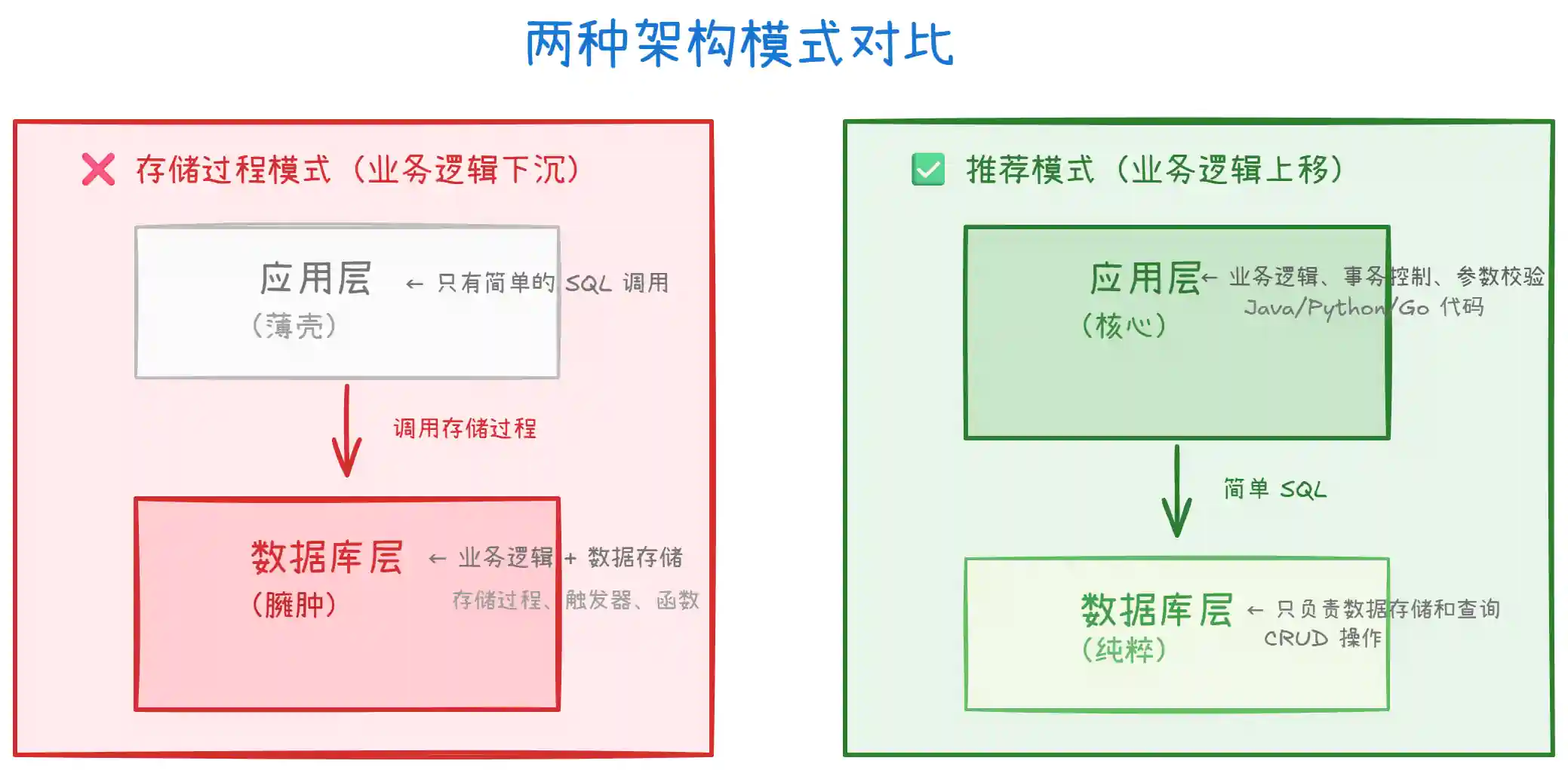
上图对比了两种架构模式的差异。核心问题在于:
-
存储过程模式:业务逻辑被 "下沉" 到数据库层,应用层变成了一个 "薄壳",只负责调用存储过程。这导致数据库承担了本不该由它承担的计算任务。
-
推荐模式:应用层负责业务逻辑、事务控制、参数校验,数据库层专注于数据存储和查询,职责清晰,易于维护和扩展。
为什么分层很重要:
-
单一职责:数据库擅长数据存储和检索,不擅长复杂业务计算。
-
独立演进:应用层可以独立部署、扩容,数据库层可以独立优化、迁移。
-
技术栈解耦:应用层可以用 Java、Go、Python 等任意语言,数据库可以切换不同产品。
二、可调试性:排查问题的噩梦
-- 存储过程示例:复杂的业务逻辑
CREATE PROCEDURE process_order(IN order_id INT)
BEGIN
DECLARE v_status VARCHAR(20);
-- 查询订单状态
SELECT status INTO v_status FROM orders WHERE id = order_id;
-- 复杂的业务判断逻辑
IF v_status = 'PENDING' THEN
-- 这里可能还有几十行代码...
UPDATE orders SET status = 'PROCESSING' WHERE id = order_id;
-- 调用其他存储过程
CALL update_inventory(order_id);
CALL send_notification(order_id);
END IF;
-- 异常处理?日志?断点调试?通通没有!
END;
对比 Java 代码的调试能力:
| 调试能力 | Java 应用层 | 存储过程 |
|---|---|---|
| 断点调试 | ✅ IDE 支持 | ❌ 基本不支持 |
| 日志追踪 | ✅ Log4j/SLF4J | ⚠️ 只能写临时表 |
| 单元测试 | ✅ JUnit/Mockito | ❌ 难以测试 |
| 性能分析 | ✅ Arthas/JProfiler | ⚠️ 只能看执行时间 |
| 异常堆栈 | ✅ 完整堆栈 | ❌ 信息有限 |
三、可扩展性:数据库成为瓶颈
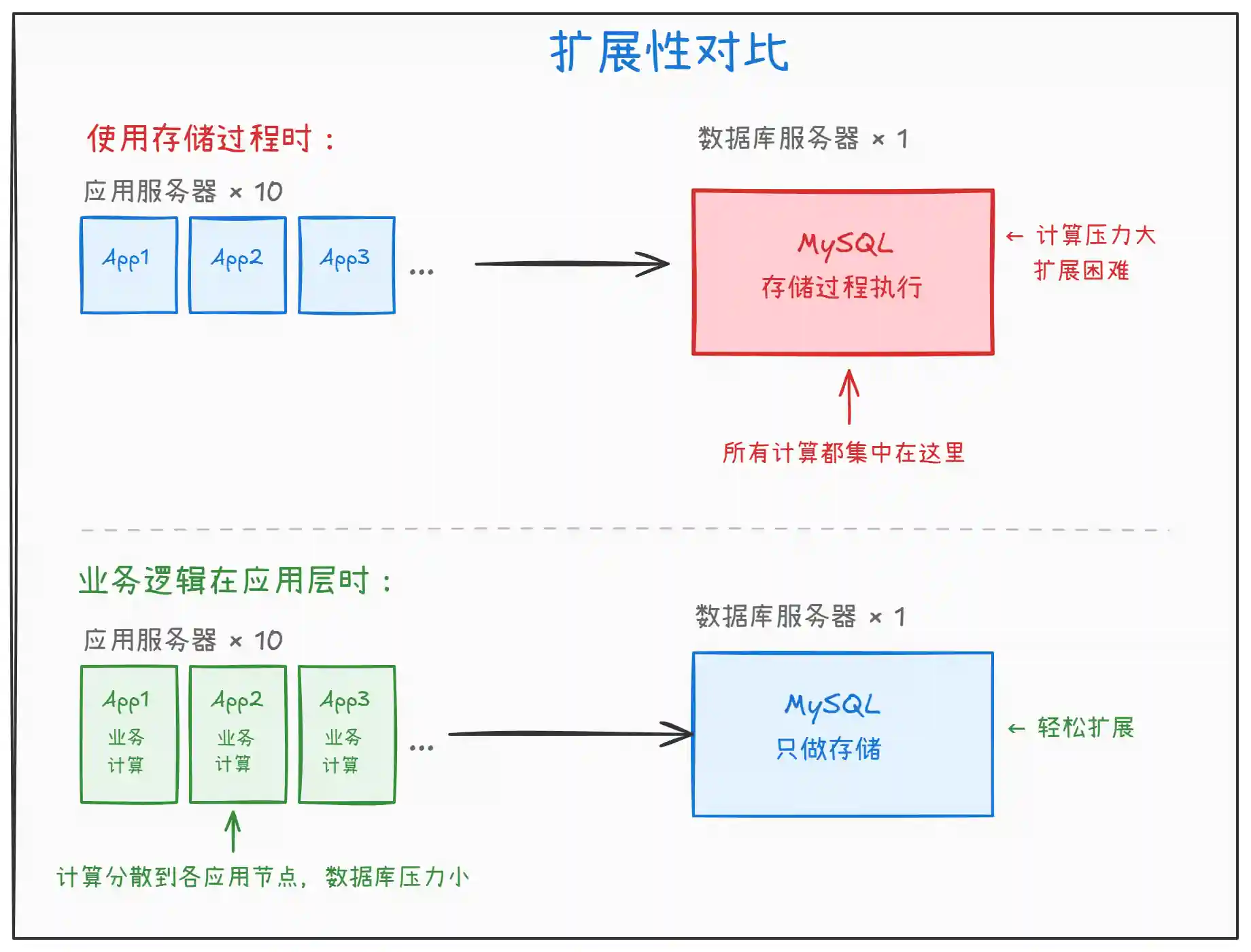
上图展示了两种架构的扩展性差异:
-
存储过程模式:业务计算集中在数据库层。当流量增加时,可以水平扩展应用服务器,但数据库服务器无法水平扩展,成为整个系统的瓶颈。
-
应用层逻辑模式:业务计算分散到各个应用节点。数据库只负责数据存储和查询,压力大大降低。当数据库压力过大时,可以通过读写分离、分库分表等方式扩展。
关键点:数据库是最难水平扩展的组件,应该尽量减少它的计算负担。
四、可移植性:数据库技术绑定
-- MySQL 存储过程语法
CREATE PROCEDURE get_users()
BEGIN
SELECT * FROM users;
END;
-- Oracle 存储过程语法(完全不同)
CREATE OR REPLACE PROCEDURE get_users AS
BEGIN
OPEN cur FOR SELECT * FROM users;
END;
-- SQL Server 存储过程语法(又不一样)
CREATE PROCEDURE get_users
AS
BEGIN
SELECT * FROM users;
END;
迁移成本:
- 从 MySQL 迁移到 PostgreSQL?重写所有存储过程。
- 从 Oracle 迁移到 MySQL?重写所有存储过程。
- 使用云数据库?可能不支持某些存储过程特性。
相比之下,Java/Python 业务代码与数据库无关,切换数据库只需修改 SQL 语句和连接配置。
五、团队协作:职责边界模糊
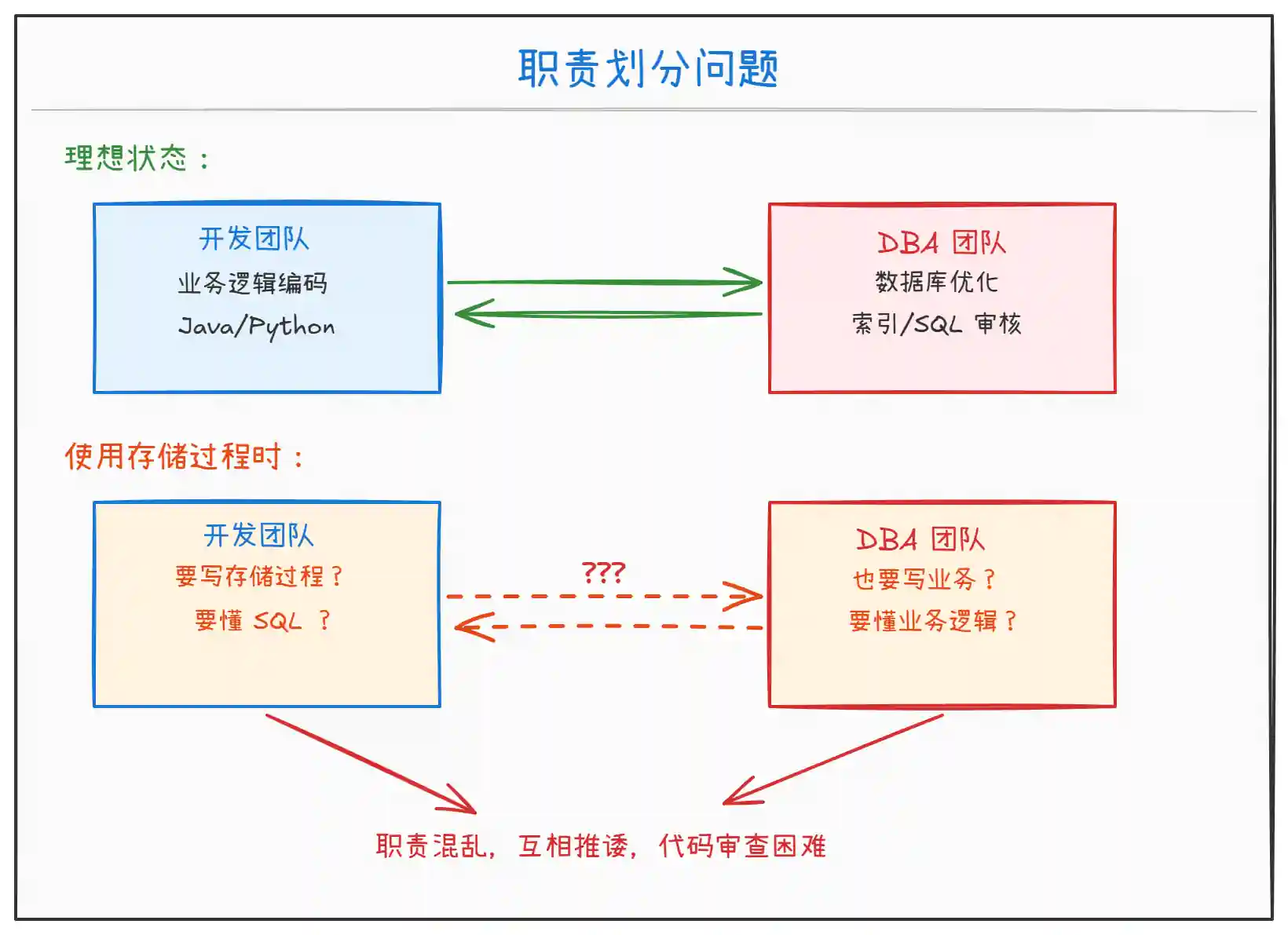
上图说明了使用存储过程时的团队协作问题:
-
开发团队:需要熟悉 SQL 语法、存储过程调试,增加学习成本。
-
DBA 团队:需要理解业务逻辑,参与业务代码评审,职责边界模糊。
-
代码审查:存储过程代码难以纳入团队的 Code Review 流程。
-
版本管理:存储过程通常不在 Git 仓库中,版本追踪困难。
六、什么时候可以用存储过程?
虽然不建议大量使用,但以下场景可以考虑:
| 场景 | 原因 | 示例 |
|---|---|---|
| 批量数据处理 | 减少网络开销,一次性执行大量操作 | 数据迁移、批量更新 |
| 复杂报表统计 | 计算密集型,避免数据传输 | 月度汇总报表 |
| 触发器场景 | 数据变更时自动执行 | 审计日志记录 |
| 遗留系统 | 改造成本高,保持现状 | 老旧 ERP 系统 |
原则:存储过程适合 "数据密集型" 操作,不适合 "逻辑密集型" 操作。
面试高频追问
-
存储过程和 SQL 语句有什么区别?
- 存储过程是预编译的 SQL 代码集合,存储在数据库中;SQL 语句每次执行都需要编译。存储过程可以包含流程控制、变量、异常处理等,普通 SQL 不行。
-
存储过程有性能优势吗?
- 理论上有(减少网络传输、预编译),但现代应用中网络延迟影响小,ORM 框架也有预编译支持,性能优势不明显。而且存储过程会把计算压力集中到数据库,反而可能成为瓶颈。
-
你们项目中遇到过存储过程的问题吗?
- 可以结合实际经验回答,如:调试困难、迁移时重写成本高、DBA 和开发职责不清等。
常见面试变体
- "存储过程和函数有什么区别?"
- "为什么现代互联网架构很少使用存储过程?"
- "存储过程适用于什么场景?"
记忆口诀
存储过程六大坑:维护难、调试难、移植难、扩展难、协作难、版本难
一句话决策:逻辑上应用层,数据下数据库,存储过程少用甚至不用。
总结
不建议使用存储过程的核心原因是它违背了分层架构原则,把业务逻辑下沉到数据库层,导致维护困难、调试困难、扩展困难、迁移困难。现代互联网架构强调职责分离,应用层负责业务逻辑,数据库层专注于数据存储,这样才能实现高内聚、低耦合、易扩展。当然,批量数据处理、复杂报表统计等特定场景可以适度使用存储过程,但要控制范围,避免滥用。