MySQL 乐观锁与悲观锁怎么实现?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
概念理解度:面试官不仅仅是想知道你听过这两种锁的名字,更是想知道你是否理解它们的核心思想差异—— "先加锁再访问" vs "先访问再加锁"。
-
实践应用能力:考察你是否在实际项目中使用过这两种锁,能否根据业务场景(读多写少 vs 写多读少)选择合适的锁策略。
-
问题诊断能力:是否了解乐观锁的 ABA 问题、悲观锁的死锁风险,以及各自的解决方案。
核心答案
| 对比维度 | 乐观锁 | 悲观锁 |
|---|---|---|
| 核心思想 | 假设不会冲突,更新时检查 | 假设会冲突,操作前先加锁 |
| 实现方式 | CAS + 版本号/时间戳 |
SELECT ... FOR UPDATE |
| 加锁时机 | 提交更新时才检测 | 读取数据时就加锁 |
| 适用场景 | 读多写少、冲突较少 | 写多读少、冲突频繁 |
| 性能特点 | 并发性高,但冲突时重试成本高 | 并发性低,但数据一致性保障强 |
| ABA 问题 | 存在,需额外处理 | 不存在 |
一句话总结:乐观锁适合 "冲突少、读多写少" 的场景,悲观锁适合 "冲突多、写频繁" 的场景。
深度解析
一、乐观锁实现方案
乐观锁在 MySQL 中主要通过 版本号机制 或 时间戳机制 实现,核心是 "比较再交换"(Compare And Swap)的思想。
1. 版本号机制
实现步骤:
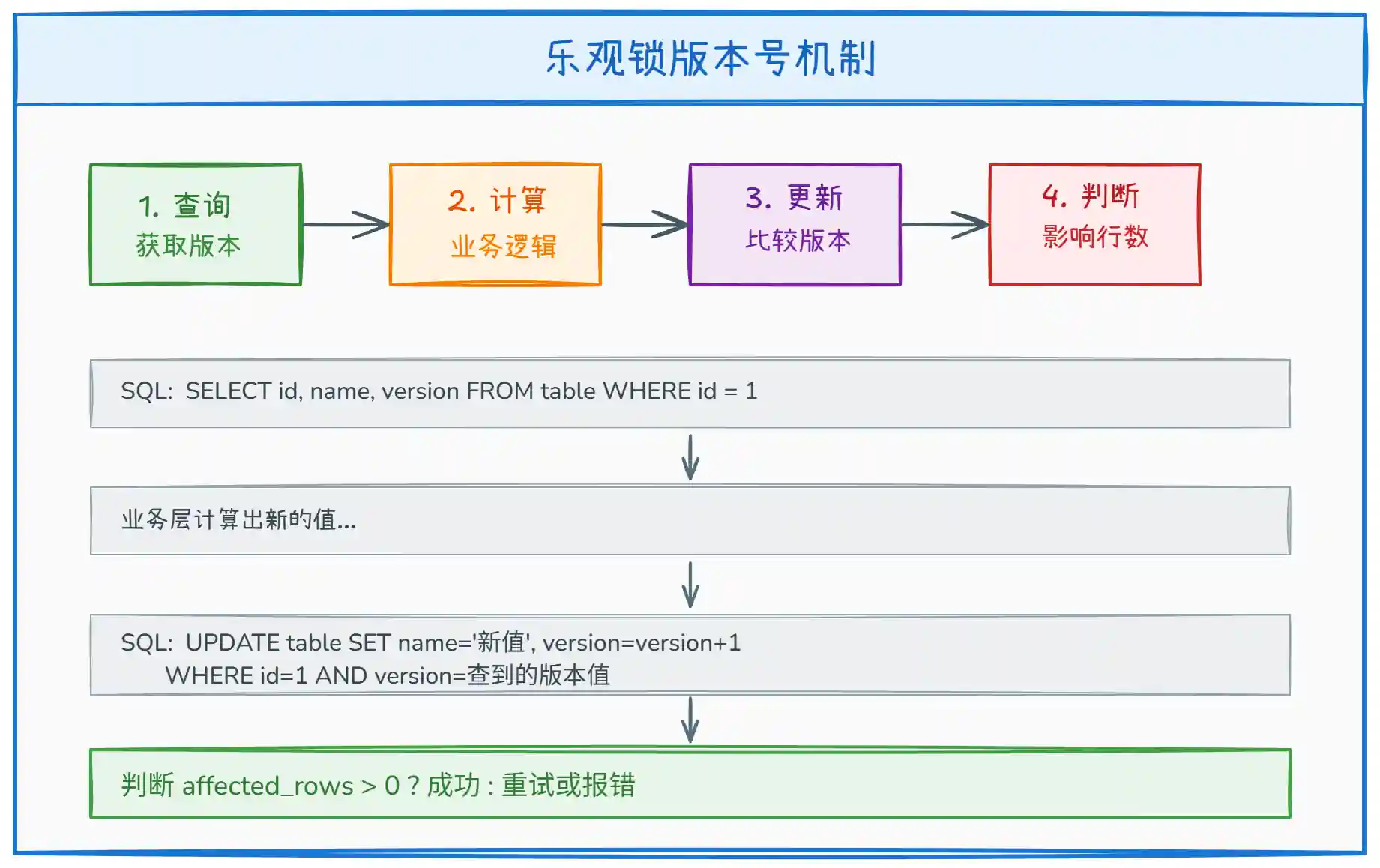
上图展示了乐观锁版本号机制的完整流程:
- 第一步(查询):先从数据库读取数据,同时获取当前版本号
version - 第二步(计算):在业务层进行逻辑计算,准备新值(此时不加锁,其他事务可以同时读取)
- 第三步(更新):执行更新语句,
WHERE条件中携带之前查到的版本号,同时将版本号 +1 - 第四步(判断):检查
affected_rows(影响行数),如果大于 0 说明更新成功;如果等于 0 说明版本号已被其他事务修改,需要重试或报错
表结构设计:
-- 商品表,version 字段作为乐观锁版本号
CREATE TABLE product (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
stock INT NOT NULL DEFAULT 0,
version INT NOT NULL DEFAULT 0, -- 版本号字段
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
Java 代码示例:
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
/**
* 扣减库存(乐观锁实现)
* @return true-扣减成功,false-库存不足或版本冲突需重试
*/
public boolean deductStockWithOptimisticLock(Long productId, int quantity) {
// 1. 查询商品信息(包含版本号)
Product product = productMapper.selectById(productId);
if (product.getStock() < quantity) {
return false; // 库存不足
}
// 2. 执行更新,携带版本号条件
// UPDATE product SET stock = stock - #{quantity}, version = version + 1
// WHERE id = #{id} AND version = #{version}
int affectedRows = productMapper.deductStockOptimistic(
productId,
quantity,
product.getVersion() // 携带查询时的版本号
);
// 3. 判断是否更新成功
return affectedRows > 0;
}
/**
* 带重试机制的乐观锁扣减
*/
@Retryable(value = OptimisticLockException.class, maxAttempts = 3)
public boolean deductStockWithRetry(Long productId, int quantity) {
boolean success = deductStockWithOptimisticLock(productId, quantity);
if (!success) {
throw new OptimisticLockException("版本冲突,请重试");
}
return true;
}
}
Mapper XML:
<select id="selectById" resultType="com.example.Product">
SELECT id, name, stock, version FROM product WHERE id = #{id}
</select>
<update id="deductStockOptimistic">
UPDATE product
SET stock = stock - #{quantity},
version = version + 1
WHERE id = #{id} AND version = #{version}
</update>
2. 时间戳机制
与版本号类似,用 update_time 字段替代 version 字段:
-- 更新时比较时间戳
UPDATE product
SET stock = stock - 1,
update_time = NOW()
WHERE id = 1 AND update_time = '2024-01-01 10:30:00';
⚠️ 注意:时间戳方案存在精度问题(毫秒级并发可能冲突),生产环境推荐使用版本号。
3. 条件更新(简化版乐观锁)
对于库存扣减这种"数值增减"场景,可以简化为:
-- 直接在 SQL 中判断库存是否充足
UPDATE product
SET stock = stock - 1
WHERE id = 1 AND stock > 0;
这种方式不需要额外的版本号字段,本质上是利用数据库的原子性保证一致性。
二、悲观锁实现方案
悲观锁在 MySQL 中通过 SELECT ... FOR UPDATE 实现,利用数据库的排他锁(X 锁)机制。
1. FOR UPDATE 语法
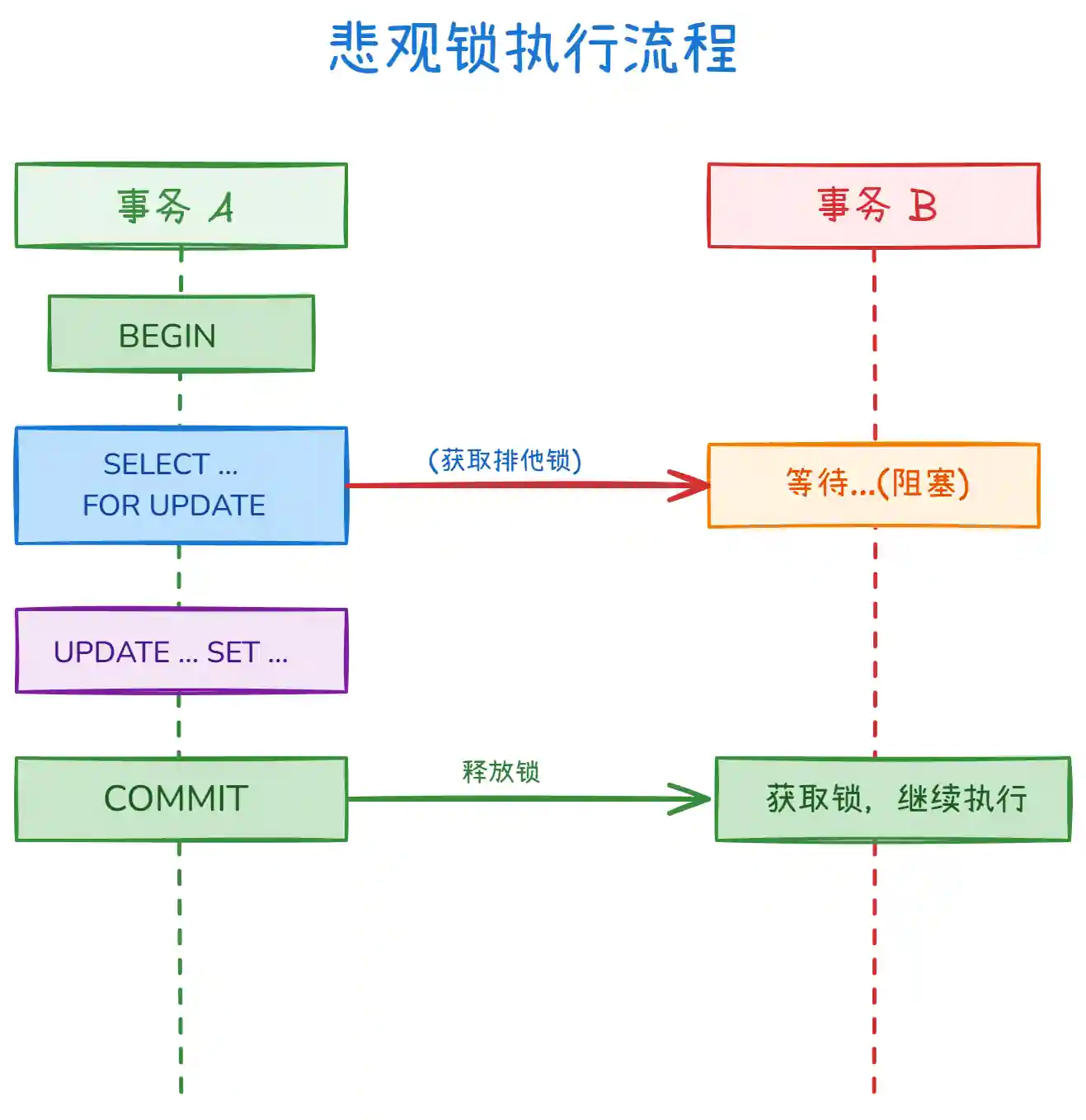
上图展示了悲观锁的执行流程:
- 事务 A 首先执行
SELECT ... FOR UPDATE,数据库会对查询到的记录加排他锁(X 锁) - 事务 B 同时也想对同一行执行
FOR UPDATE,由于锁被事务 A 持有,事务 B 会阻塞等待 - 事务 A 完成更新并
COMMIT后,锁被释放 - 事务 B 此时才能获取到锁,继续执行
Java 代码示例:
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
/**
* 扣减库存(悲观锁实现)
* 注意:必须在事务中执行
*/
@Transactional
public boolean deductStockWithPessimisticLock(Long productId, int quantity) {
// 1. 加锁查询(FOR UPDATE)
// SELECT id, name, stock FROM product WHERE id = #{id} FOR UPDATE
Product product = productMapper.selectByIdForUpdate(productId);
// 此时其他事务如果想操作这条记录,必须等待当前事务提交
if (product.getStock() < quantity) {
return false; // 库存不足
}
// 2. 执行更新
productMapper.updateStock(productId, quantity);
// 3. 事务提交时自动释放锁
return true;
}
}
Mapper XML:
<!-- 悲观锁查询:FOR UPDATE -->
<select id="selectByIdForUpdate" resultType="com.example.Product">
SELECT id, name, stock FROM product WHERE id = #{id} FOR UPDATE
</select>
<update id="updateStock">
UPDATE product SET stock = stock - #{quantity} WHERE id = #{id}
</update>
2. 锁的范围与索引
⚠️ 重要:FOR UPDATE 的锁范围与索引密切相关:
| 场景 | 锁范围 | 风险 |
|---|---|---|
| 通过主键/唯一索引查询 | 只锁匹配的行 | ✅ 推荐 |
| 通过普通索引查询 | 锁索引匹配的所有行 + 间隙 | ⚠️ 可能扩大锁范围 |
| 无索引查询 | 锁整张表 | ❌ 严重性能问题 |
-- ✅ 推荐:通过主键查询,只锁一行
SELECT * FROM product WHERE id = 1 FOR UPDATE;
-- ⚠️ 注意:无索引会锁表
SELECT * FROM product WHERE name = 'iPhone' FOR UPDATE; -- name 无索引
3. 死锁预防
悲观锁可能导致死锁,需要遵循以下原则:
/**
* 死锁预防原则:
* 1. 按固定顺序加锁(如按 ID 升序)
* 2. 避免长事务
* 3. 设置合理的锁等待超时
*/
@Transactional
public void transfer(Long fromId, Long toId, BigDecimal amount) {
// 按ID升序加锁,避免循环等待
Long first = Math.min(fromId, toId);
Long second = Math.max(fromId, toId);
Account acc1 = accountMapper.selectByIdForUpdate(first);
Account acc2 = accountMapper.selectByIdForUpdate(second);
// 执行转账逻辑...
}
三、乐观锁 vs 悲观锁对比
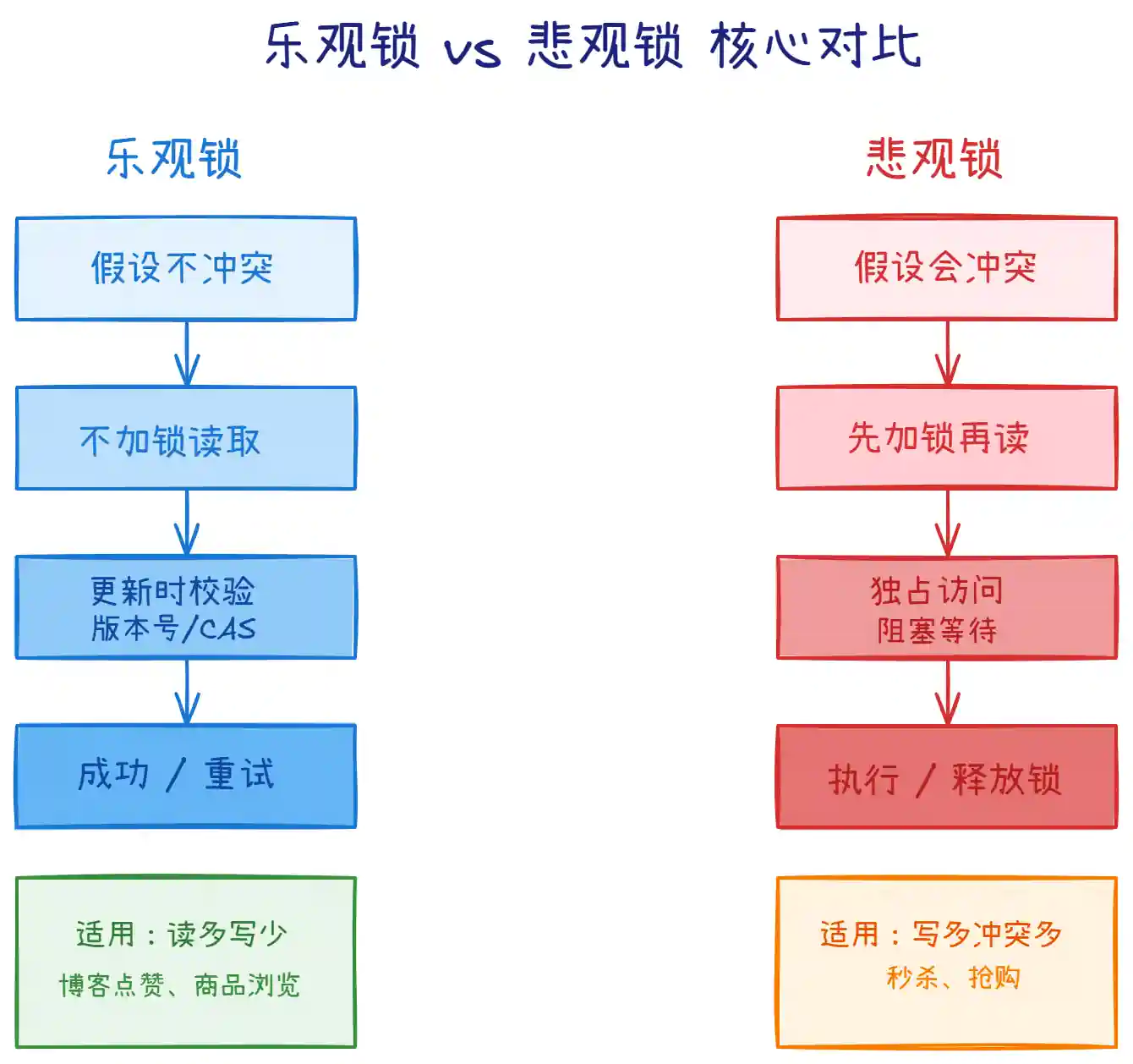
选择建议:
| 业务场景 | 推荐锁类型 | 原因 |
|---|---|---|
| 博客点赞、评论数 | 乐观锁 | 读远多于写,冲突概率极低 |
| 商品库存扣减(低并发) | 乐观锁 | 冲突较少,避免锁开销 |
| 秒杀抢购(高并发) | 悲观锁 | 冲突频繁,乐观锁重试成本高 |
| 账户余额操作 | 悲观锁 | 资金安全第一,强一致性 |
| 订单状态流转 | 悲观锁 | 状态一致性要求高 |
四、常见问题与解决方案
1. 乐观锁的 ABA 问题
问题描述:线程 1 读取版本 A,线程 2 将 A→B→A,线程 1 更新时误以为没有变化。
解决方案:使用更细粒度的版本号(如雪花算法 ID)或额外状态字段。
// 使用时间戳 + 随机数组合作为版本,避免 ABA
String newVersion = System.currentTimeMillis() + "_" + UUID.randomUUID();
2. 悲观锁的死锁问题
检测死锁:
-- 查看当前锁等待情况
SELECT * FROM information_schema.INNODB_LOCK_WAITS;
-- 查看当前运行的事务
SELECT * FROM information_schema.INNODB_TRX;
解决方案:
- 设置锁等待超时:
innodb_lock_wait_timeout = 50(默认 50 秒) - 按固定顺序加锁
- 避免长事务
- 使用小事务
面试高频追问
-
追问一:秒杀场景用乐观锁还是悲观锁?
高并发秒杀建议用悲观锁或分布式锁。乐观锁在冲突率极高时,大量请求需要重试,反而降低吞吐量。实际生产中常用 Redis 预扣库存 + 消息队列异步落库。
-
追问二:乐观锁更新失败后怎么处理?
两种策略:
- 重试机制:使用 Spring Retry 或自定义重试逻辑,设置最大重试次数
- 直接失败:返回错误提示让用户重新操作(如"数据已被修改,请刷新后重试")
-
追问三:
FOR UPDATE和LOCK IN SHARE MODE的区别?FOR UPDATE:加排他锁(X 锁),其他事务不能读也不能写LOCK IN SHARE MODE:加共享锁(S 锁),其他事务可以读但不能写
常见面试变体
- "如何解决并发更新数据的一致性问题?"
- "数据库行锁和表锁的区别?什么时候会锁表?"
- "什么场景下乐观锁比悲观锁性能更好?"
- "MySQL 的 MVCC 机制是什么?和乐观锁有什么关系?"
记忆口诀
乐观锁:先查后比再更新,版本不对就重试,适合读多写少场景
悲观锁:先锁后改再提交,别人只能干等着,适合写多冲突场景
总结
乐观锁通过版本号机制在更新时检测冲突,适合读多写少、冲突率低的场景;悲观锁通过 FOR UPDATE 加排他锁强制串行化,适合写多冲突、一致性要求高的场景。生产环境需根据业务特点选择,高并发场景可结合 Redis 分布式锁优化。