什么是数据库死锁,怎么解决?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础概念掌握:面试官不仅仅是想知道你听过 "死锁" 这个词,更是想考察你是否真正理解死锁产生的四个必要条件(互斥、占有并等待、不可抢占、循环等待),以及为什么在数据库中会发生死锁。
-
实际场景应对能力:考察你是否在项目中遇到过死锁问题,能否快速定位死锁的原因,以及是否有实际解决问题的经验。这反映了你对生产环境的掌控能力。
-
预防与解决的系统性思维:面试官想了解你是否具备从多个维度(数据库配置、SQL 编写规范、业务逻辑设计、监控预警)来预防和解决死锁的能力,而不仅仅是知道几个零散的知识点。
核心答案
数据库死锁是指两个或多个事务在执行过程中,因争夺资源而造成的一种互相等待的现象。当死锁发生时,这些事务都无法继续执行,除非有外力介入打破这种循环等待。
解决方案可以从三个层面来处理:
| 层面 | 方法 | 说明 |
|---|---|---|
| 数据库层面 | 超时机制、死锁检测 | innodb_lock_wait_timeout 设置等待超时;innodb_deadlock_detect 开启死锁检测(默认开启) |
| SQL 编写层面 | 统一访问顺序、减小事务粒度 | 所有事务按相同顺序访问表和行;大事务拆分为小事务 |
| 业务设计层面 | 降低隔离级别、优化索引 | 使用 RC 隔离级别减少锁范围;建立合适索引避免全表扫描 |
一句话总结:死锁无法完全避免,但通过统一访问顺序、减小锁粒度、优化索引等手段可以大幅降低发生概率,同时配合数据库的死锁检测和超时机制来兜底。
深度解析
一、死锁产生的四个必要条件
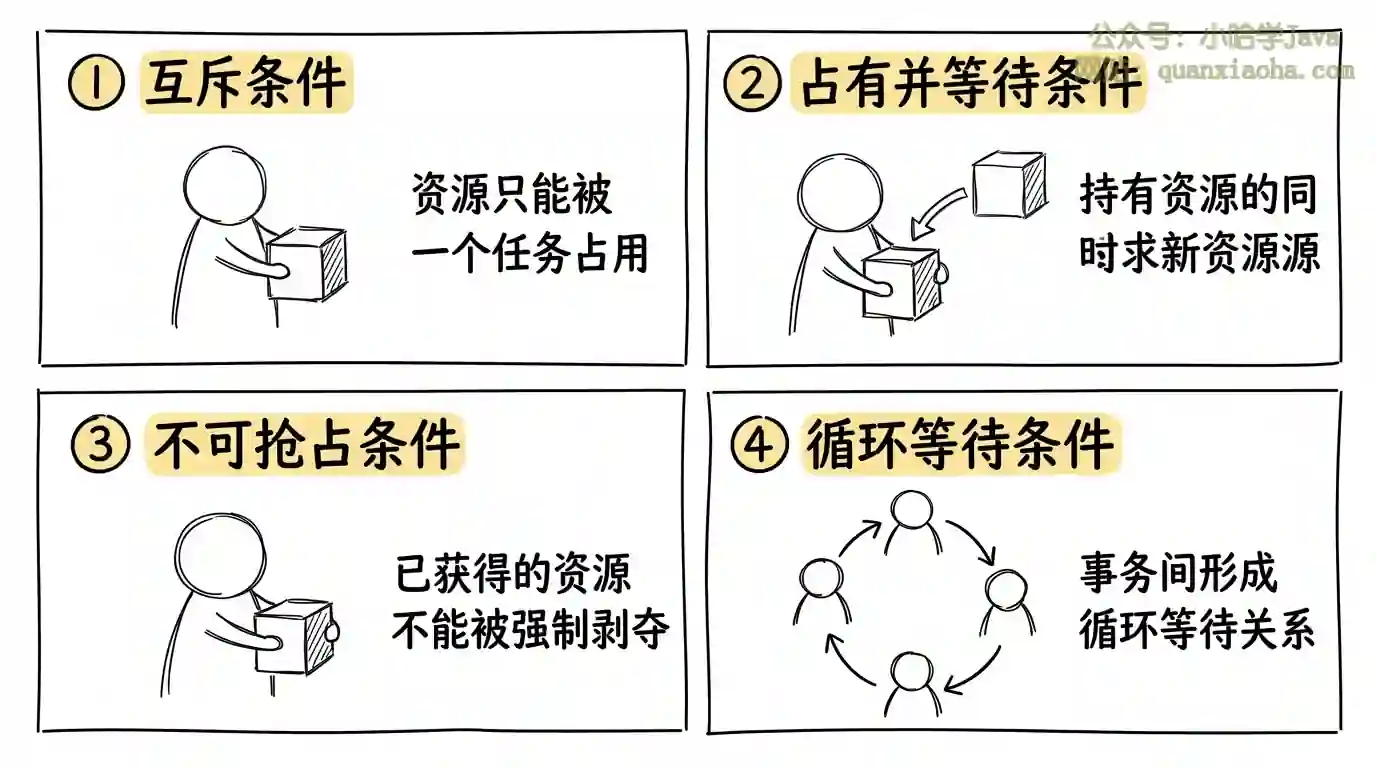
上图展示了死锁产生的四个必要条件。只有当这四个条件同时满足时,死锁才会发生。因此,预防死锁的核心思路就是破坏其中一个或多个条件。
-
互斥条件:资源在同一时间只能被一个事务占用。数据库锁天然满足这个条件,无法破坏。
-
占有并等待条件:事务已经持有了某些资源,同时还在等待获取其他资源。可以通过"一次性申请所有资源"来破坏,但实现成本较高。
-
不可抢占条件:事务已获得的资源不能被强制剥夺。数据库可以通过超时或死锁检测机制来"抢占"(回滚其中一个事务)。
-
循环等待条件:事务之间形成循环等待关系。可以通过"统一访问顺序"来破坏,这是最实用的方法。
二、典型死锁场景演示
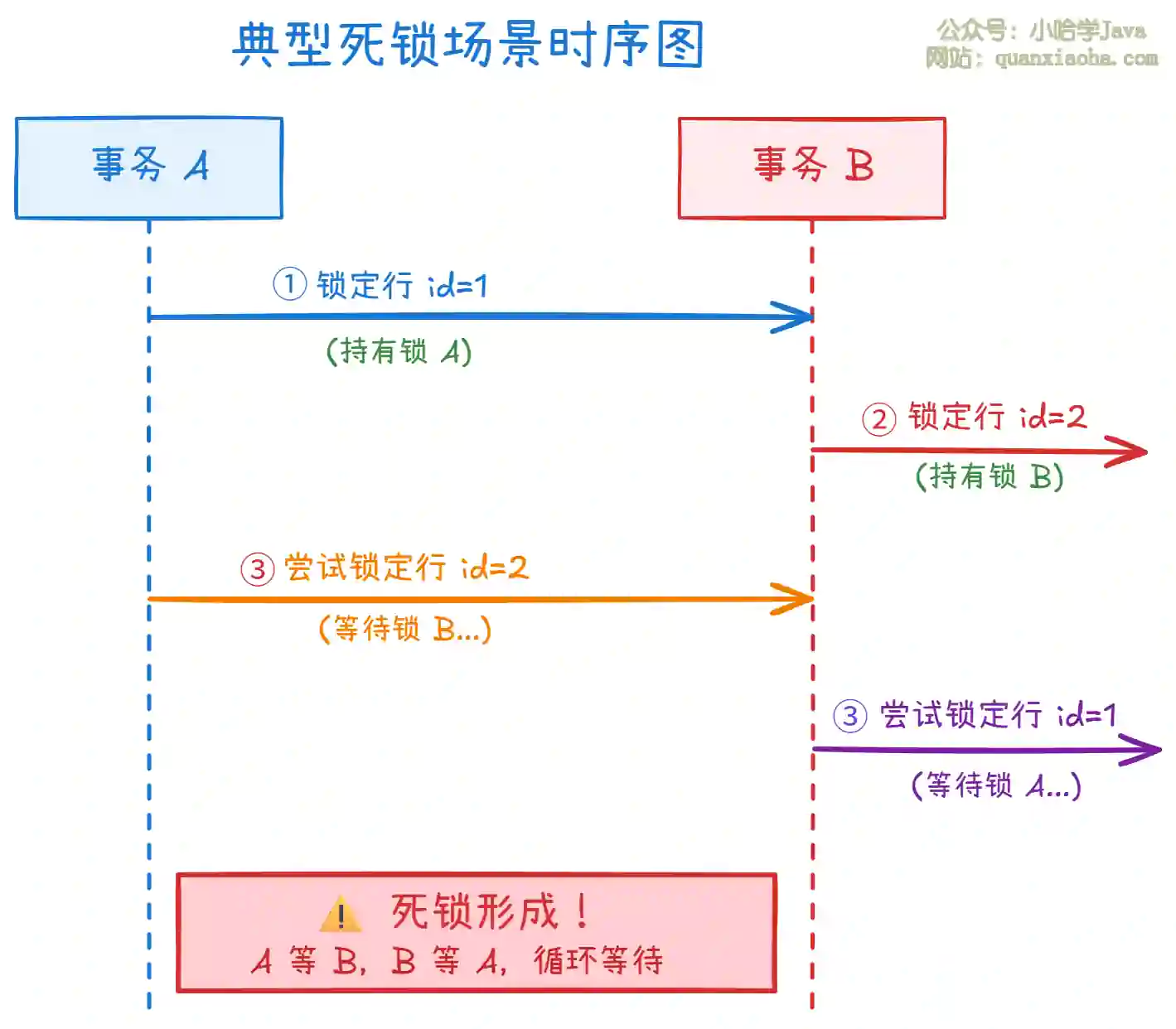
上图展示了最常见的死锁场景:两个事务以不同顺序访问相同的资源。
具体流程如下:
-
步骤 ①:事务 A 首先锁定
id=1的行,成功获得锁 A。 -
步骤 ②:事务 B 同时锁定
id=2的行,成功获得锁 B。 -
步骤 ③:事务 A 尝试锁定
id=2的行,但该行已被事务 B 锁定,因此进入等待状态。 -
步骤 ④:事务 B 尝试锁定
id=1的行,但该行已被事务 A 锁定,也进入等待状态。
此时形成了循环等待:A 等待 B 释放锁,B 等待 A 释放锁,谁都无法继续,死锁产生。
三、解决方案详解
1. 统一访问顺序(破坏循环等待条件)
-- ❌ 错误示例:不同事务以不同顺序访问
-- 事务 A:先 1 后 2
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
-- 事务 B:先 2 后 1
UPDATE accounts SET balance = balance - 100 WHERE id = 2;
UPDATE accounts SET balance = balance + 100 WHERE id = 1;
-- ✅ 正确示例:统一按 id 升序访问
-- 事务 A 和 B 都按相同顺序
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
核心原则:所有涉及多表或多行操作的事务,都按照相同的顺序(如按主键升序)访问资源,这样就不会形成循环等待。
2. 减小事务粒度(减少锁持有时间)
-- ❌ 错误示例:大事务,锁持有时间长
BEGIN;
-- 查询数据
SELECT * FROM orders WHERE user_id = 100;
-- 调用外部接口(耗时操作)
CALL external_service();
-- 更新数据
UPDATE orders SET status = 'PAID' WHERE user_id = 100;
COMMIT;
-- ✅ 正确示例:拆分事务,减少锁持有时间
-- 事务 1:只负责查询
SELECT * FROM orders WHERE user_id = 100;
-- 事务 2:只负责更新(锁持有时间短)
BEGIN;
UPDATE orders SET status = 'PAID' WHERE user_id = 100;
COMMIT;
核心原则:将大事务拆分为多个小事务,只在必要时获取锁,并尽快释放。避免在事务中执行耗时操作(如网络请求、复杂计算)。
3. 优化索引(减少锁范围)
-- ❌ 错误示例:无索引导致全表扫描,锁定所有行
-- 假设 status 字段没有索引
UPDATE orders SET status = 'CANCELLED' WHERE status = 'PENDING';
-- ✅ 正确示例:建立索引,只锁定符合条件的行
CREATE INDEX idx_status ON orders(status);
UPDATE orders SET status = 'CANCELLED' WHERE status = 'PENDING';
核心原则:没有合适的索引时,数据库可能进行全表扫描并锁定所有扫描过的行(取决于隔离级别),极大增加死锁概率。建立合适的索引可以让数据库只锁定目标行。
4. 数据库层面的配置
-- 查看当前死锁检测配置
SHOW VARIABLES LIKE 'innodb_deadlock_detect';
-- 查看锁等待超时时间(默认 50 秒)
SHOW VARIABLES LIKE 'innodb_lock_wait_timeout';
-- 调整超时时间(根据业务需求)
SET innodb_lock_wait_timeout = 30;
| 参数 | 默认值 | 说明 |
|---|---|---|
innodb_deadlock_detect |
ON | 开启死锁检测,发现死锁后自动回滚其中一个事务 |
innodb_lock_wait_timeout |
50 | 锁等待超时时间(秒),超时后事务自动回滚 |
核心原则:生产环境建议开启死锁检测(默认开启),并设置合理的超时时间。死锁检测能主动发现并解决死锁,超时机制作为兜底。
四、死锁排查与监控
-- 查看最近的死锁信息
SHOW ENGINE INNODB STATUS;
-- 在输出中查找 "LATEST DETECTED DEADLOCK" 部分
-- 可以看到:
-- 1. 哪些事务参与了死锁
-- 2. 每个事务持有哪些锁
-- 3. 每个事务在等待哪些锁
-- 4. MySQL 选择回滚了哪个事务
监控建议:
- 定期检查
SHOW ENGINE INNODB STATUS输出中的死锁信息 - 开启慢查询日志和错误日志,记录死锁发生的时间点
- 使用监控工具(如 Prometheus + Grafana)监控
Innodb_deadlocks指标 - 建立死锁告警机制,及时发现异常
面试高频追问
-
InnoDB 是如何检测死锁的?
InnoDB 使用等待图算法:为每个事务创建节点,如果事务 A 等待事务 B 的锁,就画一条 A → B 的边。定期检测图中是否存在环,存在环则说明有死锁。
-
发生死锁后,MySQL 如何选择回滚哪个事务?
MySQL 会选择回滚代价最小的事务,通常是根据事务已经修改的行数、锁定的资源数量等因素来判断。
-
RR 和 RC 隔离级别下,死锁有什么区别?
RR(可重复读)使用 Gap Lock 和 Next-Key Lock,锁定范围更大,死锁概率更高;RC(读已提交)只使用 Record Lock,锁定范围小,死锁概率相对较低。
常见面试变体
- "你项目中遇到过死锁吗?是怎么排查和解决的?"
- "如何设计系统来预防数据库死锁?"
- "MySQL InnoDB 的锁机制是什么?什么情况下会产生死锁?"
- "Gap Lock 是什么?它和死锁有什么关系?"
记忆口诀
死锁四个条件:互斥、占有等、不可抢、循环等(四个必须同时满足)
解决方案:统一顺序破循环,小事务减持有,加索引缩范围,开检测做兜底
排查口诀:SHOW ENGINE STATUS 看死锁,哪个事务哪把锁,等待图谱全明了
总结
数据库死锁是多事务并发时资源竞争导致的循环等待现象。核心解决方案是统一访问顺序(破坏循环等待)、减小事务粒度(减少锁持有时间)、优化索引(减少锁范围),同时配合数据库的死锁检测和超时机制兜底。生产环境中应建立死锁监控告警,及时发现并处理问题。