MySQL InnoDB 和 MyISAM 有什么区别?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道两个引擎的字面区别,更是想知道你是否理解 MySQL 存储引擎的底层机制,能否在实际项目中做出正确的技术选型。
-
架构设计能力:考察你是否清楚不同引擎在事务、锁、索引、崩溃恢复等方面的差异,能否根据业务特点(读多写少、高并发、强一致性等)选择合适的引擎。
-
生产实践经验:能否结合实际场景(如电商订单、日志分析、全文搜索等)给出合理的选择建议,而不是只会背概念。
核心答案
InnoDB 和 MyISAM 是 MySQL 最经典的两种存储引擎,核心区别如下:
| 对比维度 | InnoDB |
MyISAM |
|---|---|---|
| 事务支持 | ✅ 支持 ACID 事务 | ❌ 不支持事务 |
| 锁粒度 | 行级锁,支持 MVCC | 表级锁 |
| 外键约束 | ✅ 支持 | ❌ 不支持 |
| 崩溃恢复 | ✅ 支持(redo log、undo log) | ❌ 不支持,可能数据损坏 |
| 聚簇索引 | ✅ 聚簇索引(主键即数据) | ❌ 非聚簇索引 |
| 全文索引 | MySQL 5.6+ 支持 | ✅ 原生支持 |
| 存储文件 | .frm + .ibd |
.frm + .MYD + .MYI |
| 表最大行数 | 受表空间限制(64TB) | 受数据文件大小限制 |
| COUNT(*) 性能 | 需要扫描全表 | 直接读取计数器 |
| 适用场景 | 事务处理、高并发写 | 只读、读多写少、全文搜索 |
一句话总结:InnoDB 是现代 MySQL 的默认引擎,支持事务和行锁,适合高并发 OLTP 场景;MyISAM 适合读多写少的分析型场景。
深度解析
一、事务与崩溃恢复
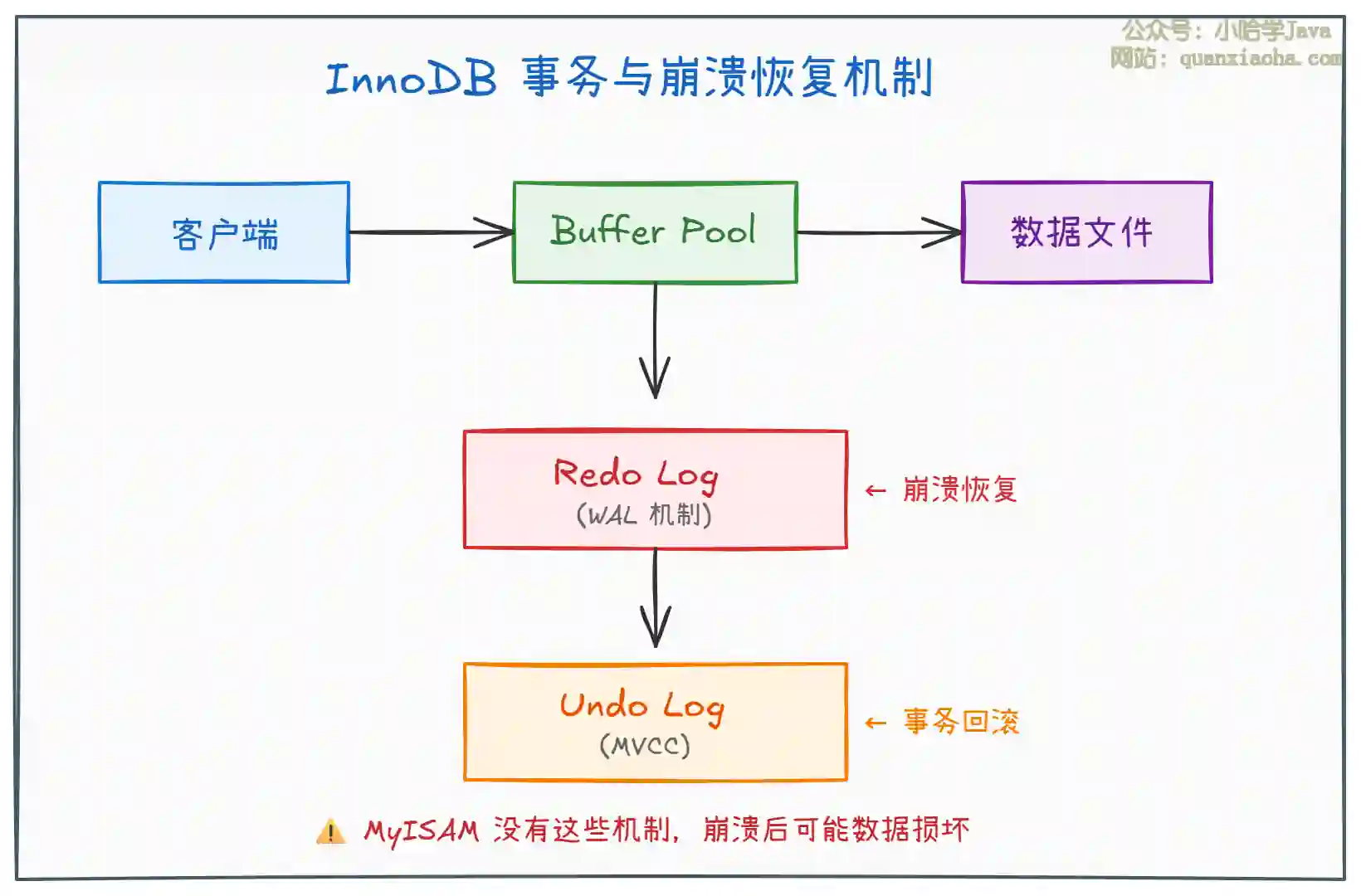
上图展示了 InnoDB 的事务与崩溃恢复机制,核心要点如下:
-
Redo Log(重做日志):采用 WAL(Write-Ahead Logging)机制,先写日志再写磁盘。即使数据库崩溃,也可以通过 redo log 恢复已提交的事务。这是 InnoDB 保证 持久性(Durability) 的核心机制。
-
Undo Log(回滚日志):用于事务回滚和 MVCC 多版本并发控制。当事务需要回滚时,通过 undo log 将数据恢复到修改前的状态;读取数据时,可以根据 undo log 看到数据的历史版本。
-
Buffer Pool:InnoDB 的内存缓冲池,数据和索引页都会先缓存到这里。修改操作先在内存中完成,再异步刷盘。
-
MyISAM 的致命缺陷:没有任何事务日志机制,写入过程中如果宕机,数据文件可能损坏且无法恢复。这是 MyISAM 逐渐被淘汰的核心原因之一。
二、锁机制对比
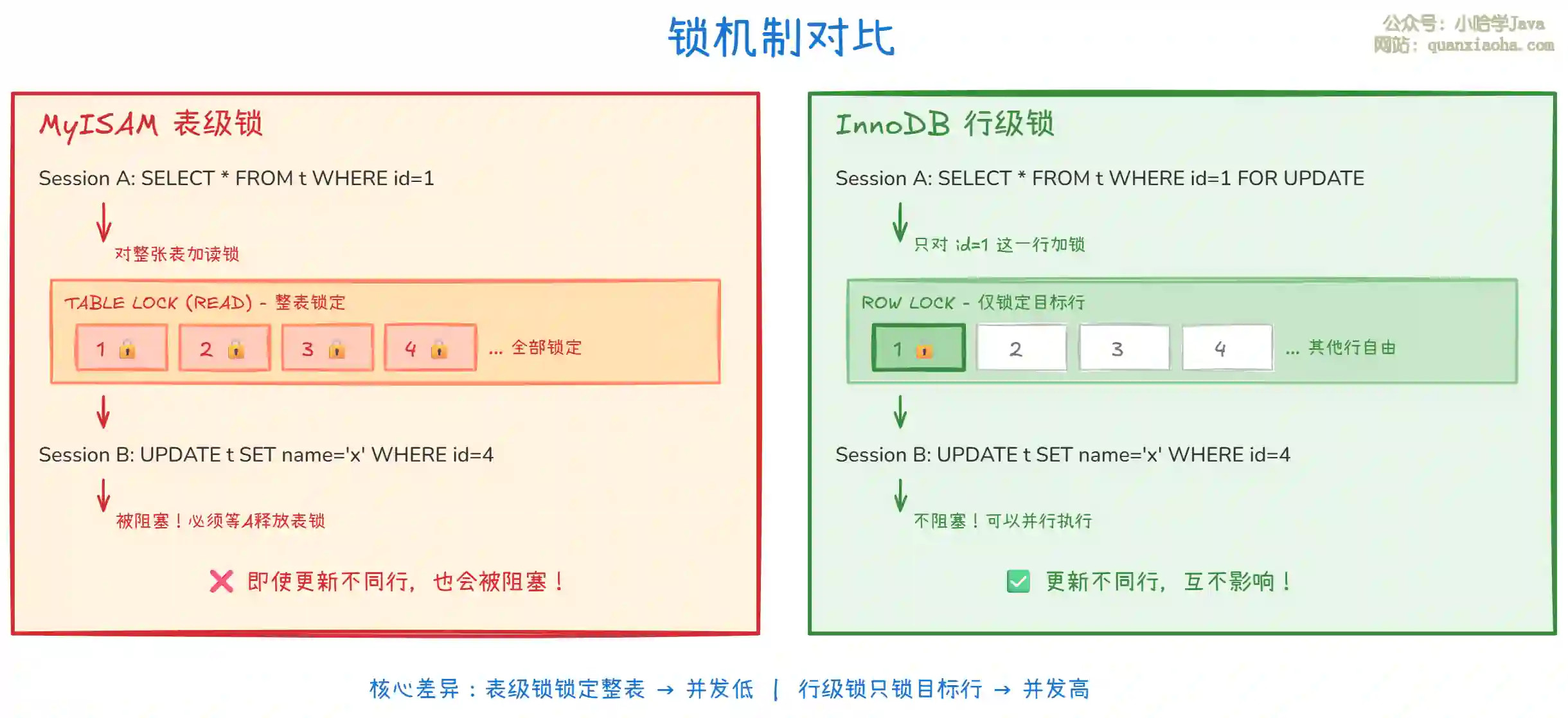
上图对比了两种存储引擎的锁机制,核心差异如下:
-
MyISAM 表级锁:
- 读操作加读锁(共享锁),允许其他会话读取,但阻塞写操作
- 写操作加写锁(排他锁),阻塞所有其他读写操作
- 即使操作的是不同的行,也会互相阻塞
- 适合读多写少的场景,因为读锁之间不冲突
-
InnoDB 行级锁:
- 只锁定被操作的数据行,不影响其他行
- 不同事务可以同时操作不同的行,并发度更高
- 配合 MVCC(多版本并发控制),普通读操作不加锁(快照读)
- 只有写操作和当前读才会加锁
- 适合高并发读写混合场景
性能影响:在高并发写入场景下,MyISAM 的表级锁会成为严重的性能瓶颈。
三、索引结构对比
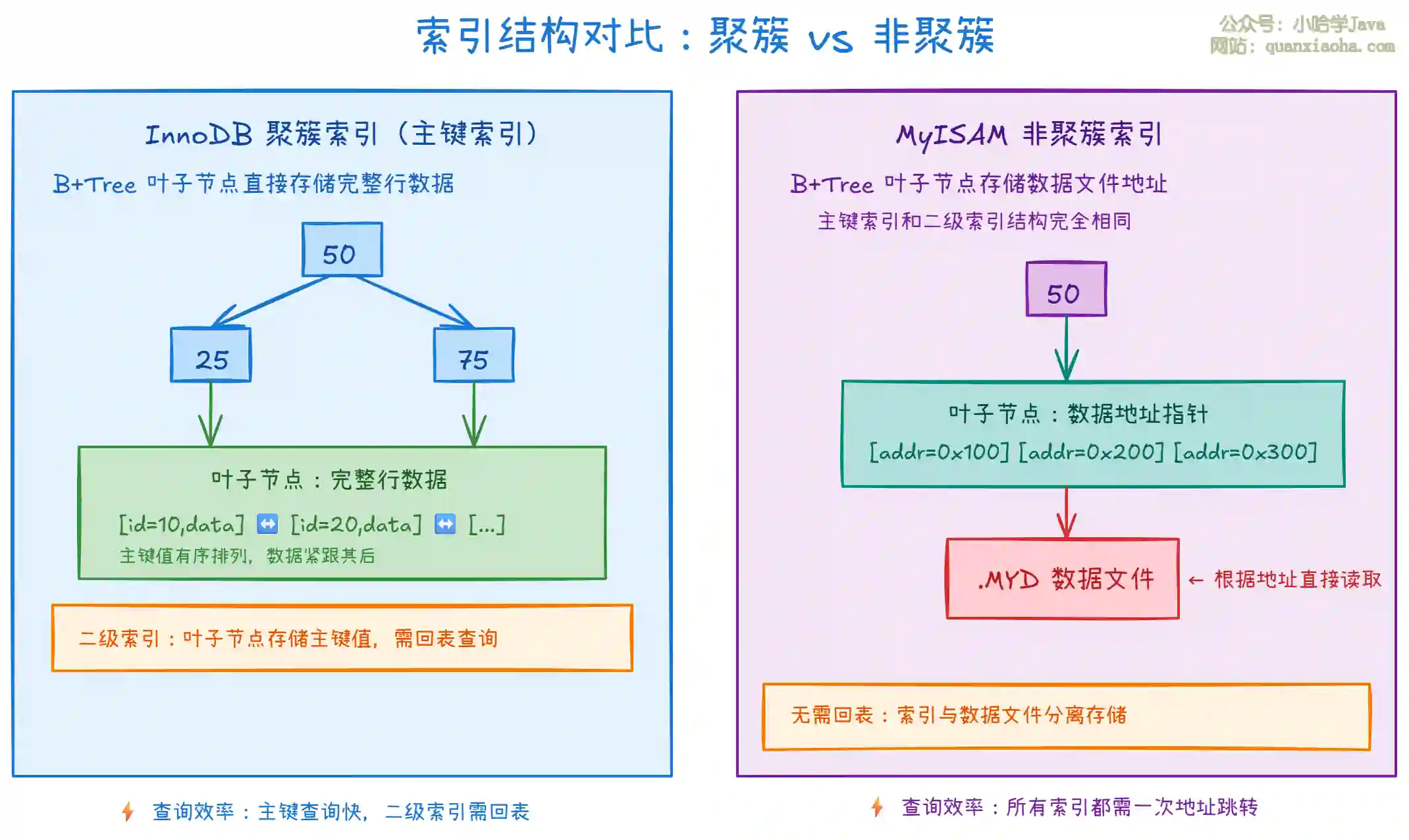
上图展示了两种存储引擎的索引结构差异:
-
InnoDB 聚簇索引:
- 主键索引的叶子节点直接存储完整行数据,数据和索引合二为一
- 数据按主键顺序物理存储,范围查询效率高
- 二级索引叶子节点存储主键值而非数据地址
- 通过二级索引查询需要"回表":先查二级索引拿到主键,再回主键索引查数据
- 主键查询效率极高,只需一次 B+Tree 查找
-
MyISAM 非聚簇索引:
- 所有索引(包括主键索引)的叶子节点都存储数据文件的物理地址偏移量
- 主键索引和二级索引的结构完全相同,没有主次之分
- 查询时不需要回表,直接根据地址跳转读取数据
- 但每次查询都需要额外的地址跳转操作
设计建议:InnoDB 中主键应该尽量短(减少二级索引存储开销),且尽量自增(减少页分裂)。
四、存储文件结构
# InnoDB 存储文件
├── table_name.frm # 表结构定义(MySQL 8.0 后合并到 .ibd)
└── table_name.ibd # 表数据 + 索引(独享表空间模式)
# MyISAM 存储文件
├── table_name.frm # 表结构定义
├── table_name.MYD # 数据文件(MYData)
└── table_name.MYI # 索引文件(MYIndex)
关键差异:
InnoDB数据和索引存储在一起(.ibd文件),采用聚簇索引结构MyISAM数据和索引分离存储(.MYD+.MYI),可以将数据文件和索引文件放在不同磁盘上提升 I/O 性能
五、COUNT(*) 性能差异
-- MyISAM: 直接读取计数器,O(1) 时间复杂度
SELECT COUNT(*) FROM myisam_table; -- 极快!
-- InnoDB: 需要扫描全表,O(n) 时间复杂度
SELECT COUNT(*) FROM innodb_table; -- 大表很慢!
原因分析:
MyISAM在内存中维护了一个计数器,记录表的总行数,执行COUNT(*)时直接返回InnoDB由于 MVCC 机制,不同事务可能看到不同的行数(有的行对某些事务不可见),无法维护全局计数器,必须扫描全表统计
InnoDB 优化方案:
-- 方案一:使用近似值(推荐,性能好)
SHOW TABLE STATUS LIKE 'innodb_table';
-- 方案二:维护计数表
CREATE TABLE row_counts (
table_name VARCHAR(64) PRIMARY KEY,
row_count BIGINT
);
-- 业务代码中维护计数
INSERT INTO row_counts VALUES ('orders', 0);
UPDATE row_counts SET row_count = row_count + 1 WHERE table_name = 'orders';
六、适用场景总结

面试高频追问
-
为什么 MySQL 5.5 之后默认使用 InnoDB?
- 事务支持:现代应用几乎都需要事务保证数据一致性
- 崩溃恢复:MyISAM 宕机后数据可能损坏,无法恢复
- 并发性能:行级锁 + MVCC 支持高并发读写
- 外键约束:保证数据引用完整性
-
InnoDB 的 MVCC 是怎么实现的?
- 通过
undo log保存数据的历史版本链 - 每行数据有两个隐藏列:
DB_TRX_ID(最后修改的事务ID)、DB_ROLL_PTR(回滚指针) - 读操作根据
Read View判断哪个版本对自己可见,无需加锁
- 通过
-
InnoDB 为什么推荐使用自增主键?
- 聚簇索引按主键顺序存储,自增主键减少页分裂和碎片
- 顺序写入避免随机 IO,大幅提升写入性能
- 二级索引存储主键值,整数主键占用空间更小
-
MyISAM 和 InnoDB 的 B+Tree 有什么区别?
InnoDB:主键是聚簇索引,叶子节点存完整数据;二级索引存主键值MyISAM:所有索引都是非聚簇的,叶子节点存数据文件地址
常见面试变体
- "MySQL 有哪些存储引擎?它们有什么区别?"
- "为什么大多数公司都用 InnoDB?"
- "MyISAM 和 InnoDB 的索引结构有什么区别?"
- "高并发场景下应该选择什么存储引擎?为什么?"
记忆口诀
事务行锁外键强,InnoDB 是首选; 只读统计全文快,MyISAM 有一席。 聚簇索引数据连,非聚簇索引用址跳。
总结
InnoDB 支持事务、行级锁、外键、崩溃恢复,采用聚簇索引,是现代 MySQL 的默认引擎,适合高并发 OLTP 场景。MyISAM 只支持表级锁,无事务和崩溃恢复,但 COUNT(*) 性能极佳,适合读多写少的分析型场景。实际项目中 99% 的场景都应该选择 InnoDB。