谈谈 Redis 集群模式?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道 Redis 有几种集群模式,更是想知道你是否能说清楚 主从复制、哨兵、Cluster 三者的演进关系、各自解决的核心问题(高可用?扩展性?),以及它们之间的区别。
-
原理理解深度:考察你是否了解主从复制的 全量 / 增量同步机制、哨兵的 故障转移流程、Cluster 的 16384 slot 分片与路由机制,而不是只会背概念。
-
方案选型能力:能否根据业务场景(数据量、QPS、是否需要强一致)选择合适的集群方案,并说出生产环境的最佳实践。
核心答案
Redis 有 3 种 集群模式,按演进顺序:
| 模式 | 核心能力 | 解决的问题 | 适用场景 |
|---|---|---|---|
| 主从复制 | 数据复制,读写分离 | 数据冗余备份、读扩展 | 读多写少,数据量小 |
| 哨兵(Sentinel) | 自动故障转移 | 主从模式下主节点宕机的自动恢复 | 中小规模,需要高可用 |
| Cluster 集群 | 分片 + 高可用 | 数据量和 QPS 超过单节点上限 | 大规模生产环境 |
一句话结论:主从复制解决 “数据备份和读扩展”,哨兵在主从基础上解决 “自动故障转移”,Cluster 在哨兵基础上解决 “水平扩展(写扩展 + 存储扩展)”。生产环境 大规模用 Cluster,中小规模用 Sentinel + 主从。
深度解析
一、主从复制
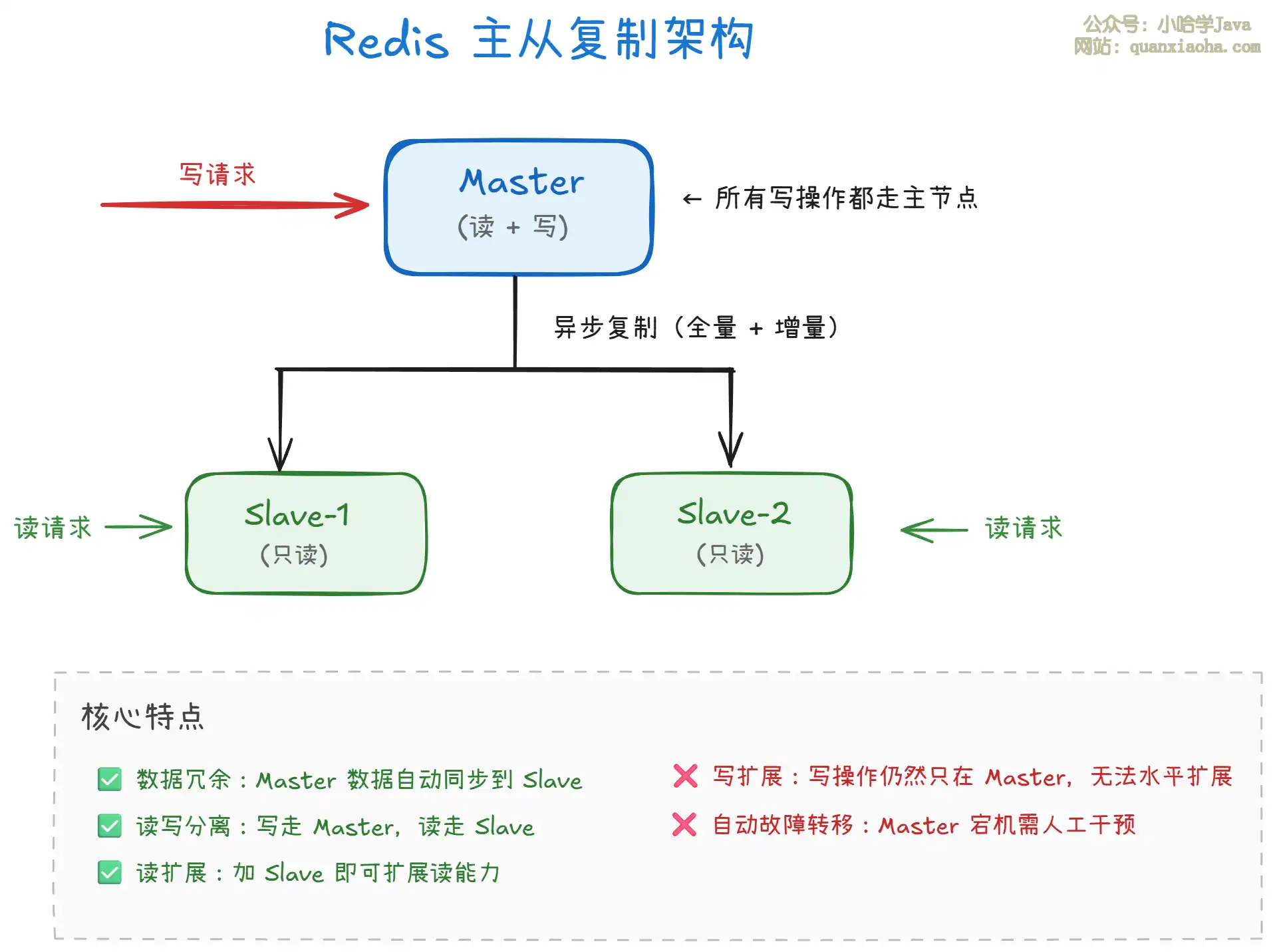
上图展示了主从复制的架构:
- 一个 Master + 多个 Slave:所有写操作在 Master 上执行,数据异步复制到 Slave。Slave 是只读的,可以分担读请求。
- 读写分离:写走 Master,读走 Slave,实现了 读扩展。适合读多写少的场景。
- 局限:写操作只能在 Master 上,无法通过加机器扩展写能力。Master 宕机后需要人工切换,没有自动故障转移。
主从复制的工作流程:
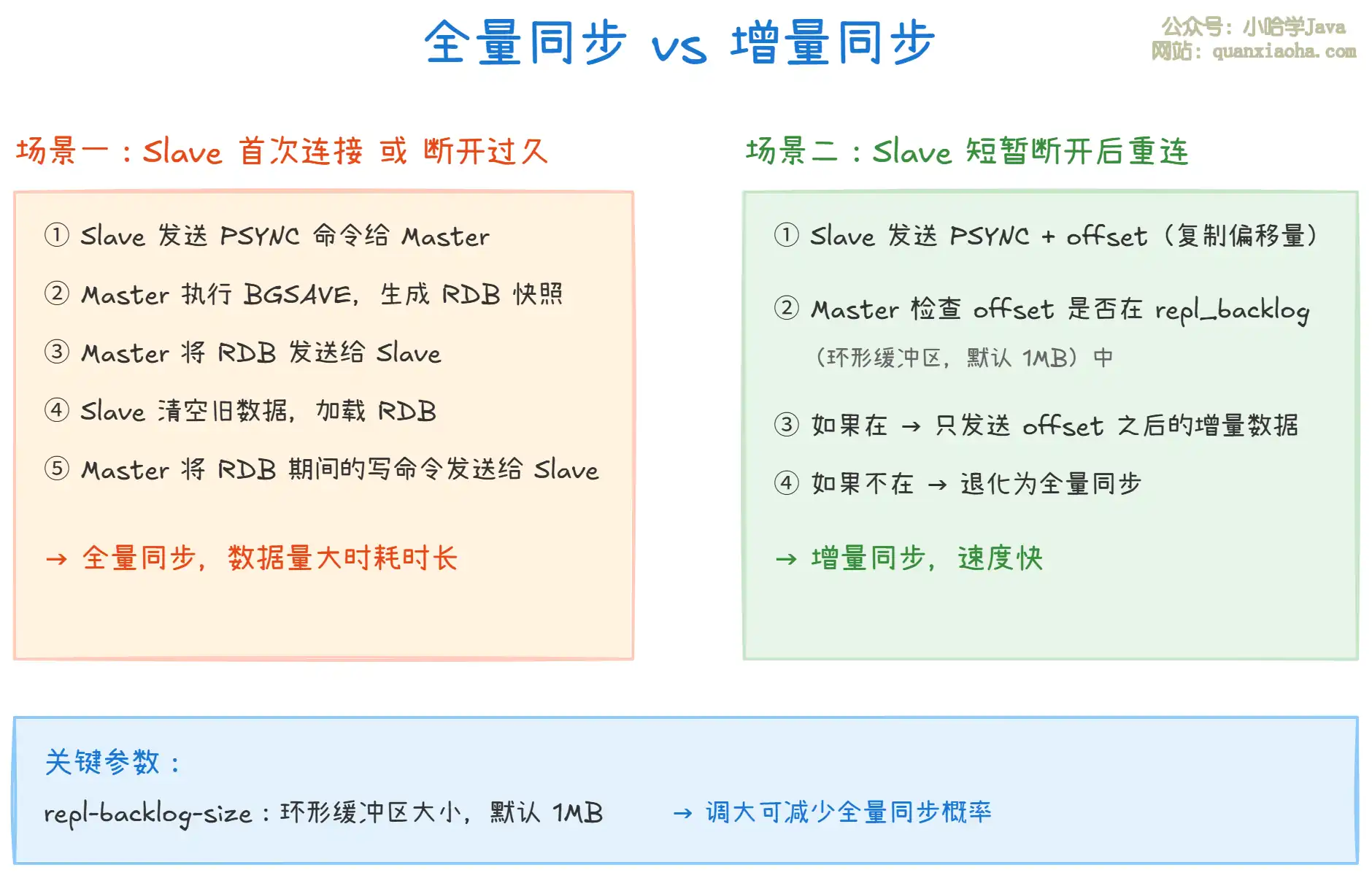
上图展示了主从复制的两种同步方式:
- 全量同步:Slave 首次连接 Master 或断开时间过长时触发。Master 执行
BGSAVE生成 RDB 快照发给 Slave,Slave 清空旧数据后加载 RDB。数据量大时耗时长,会阻塞 Master。 - 增量同步:Slave 短暂断开后重连时触发。Master 检查 Slave 的复制偏移量(offset)是否还在
repl_backlog(环形缓冲区)中,如果在就只发送增量数据,否则退化为全量同步。 - 关键参数:
repl-backlog-size控制环形缓冲区大小,默认 1MB。如果断开期间 Master 写入的数据超过缓冲区大小,就无法增量同步,必须全量。生产环境建议调大(如 256MB)。
二、哨兵模式(Sentinel)
主从复制最大的问题是 Master 宕机需要人工切换。哨兵模式就是为了解决这个问题。
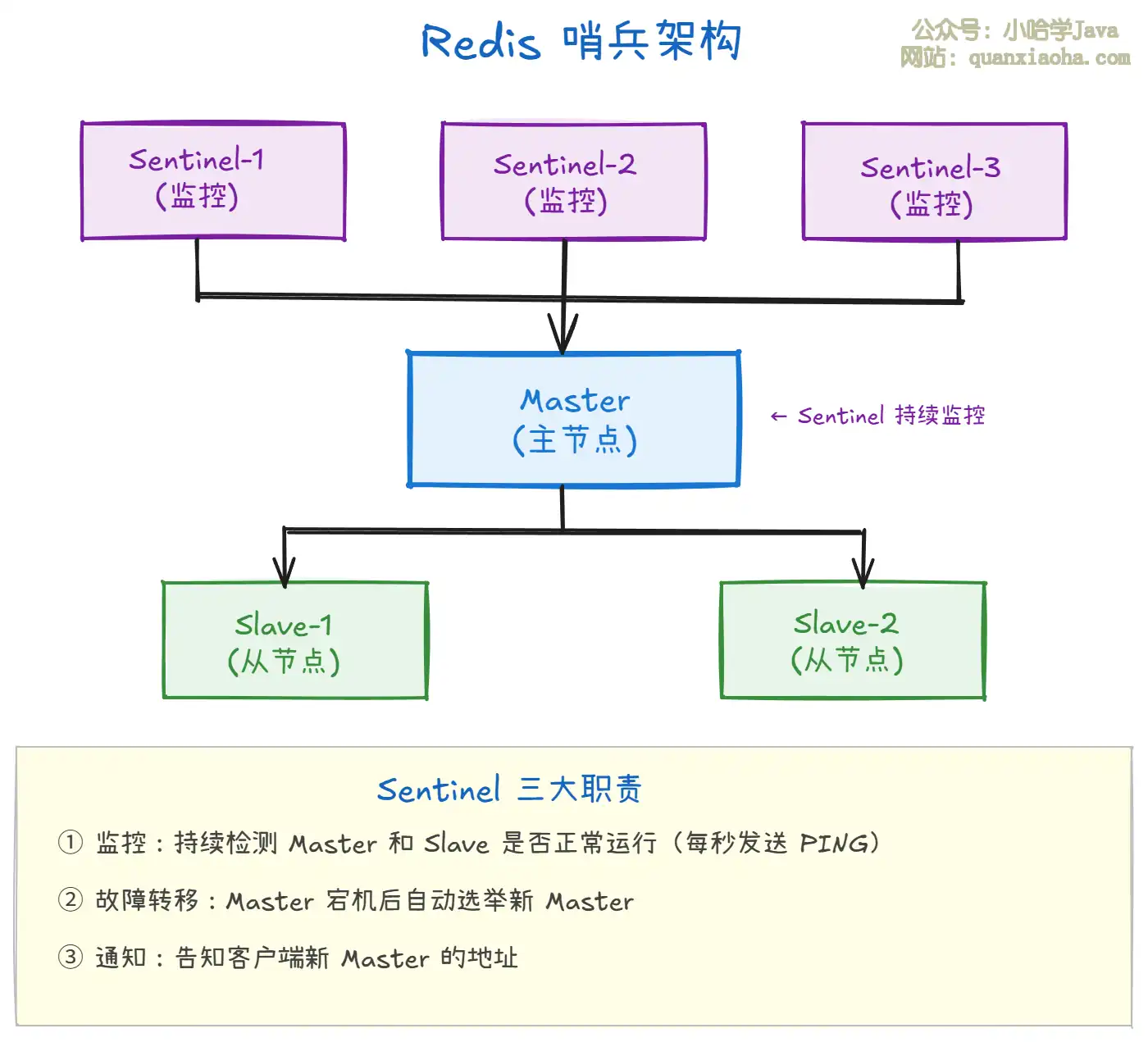
上图展示了哨兵模式的架构:
- Sentinel 是独立进程:不存储数据,只负责监控、故障转移和通知。通常部署 3 个以上(奇数个),保证高可用。
- 持续监控:Sentinel 每秒向 Master 和 Slave 发送
PING,如果节点在指定时间内没有回复,就标记为主观下线。 - 自动故障转移:Master 被判定客观下线后,Sentinel 自动从 Slave 中选举一个晋升为新 Master,并通知其他 Slave 和客户端。
故障转移流程(面试必问):
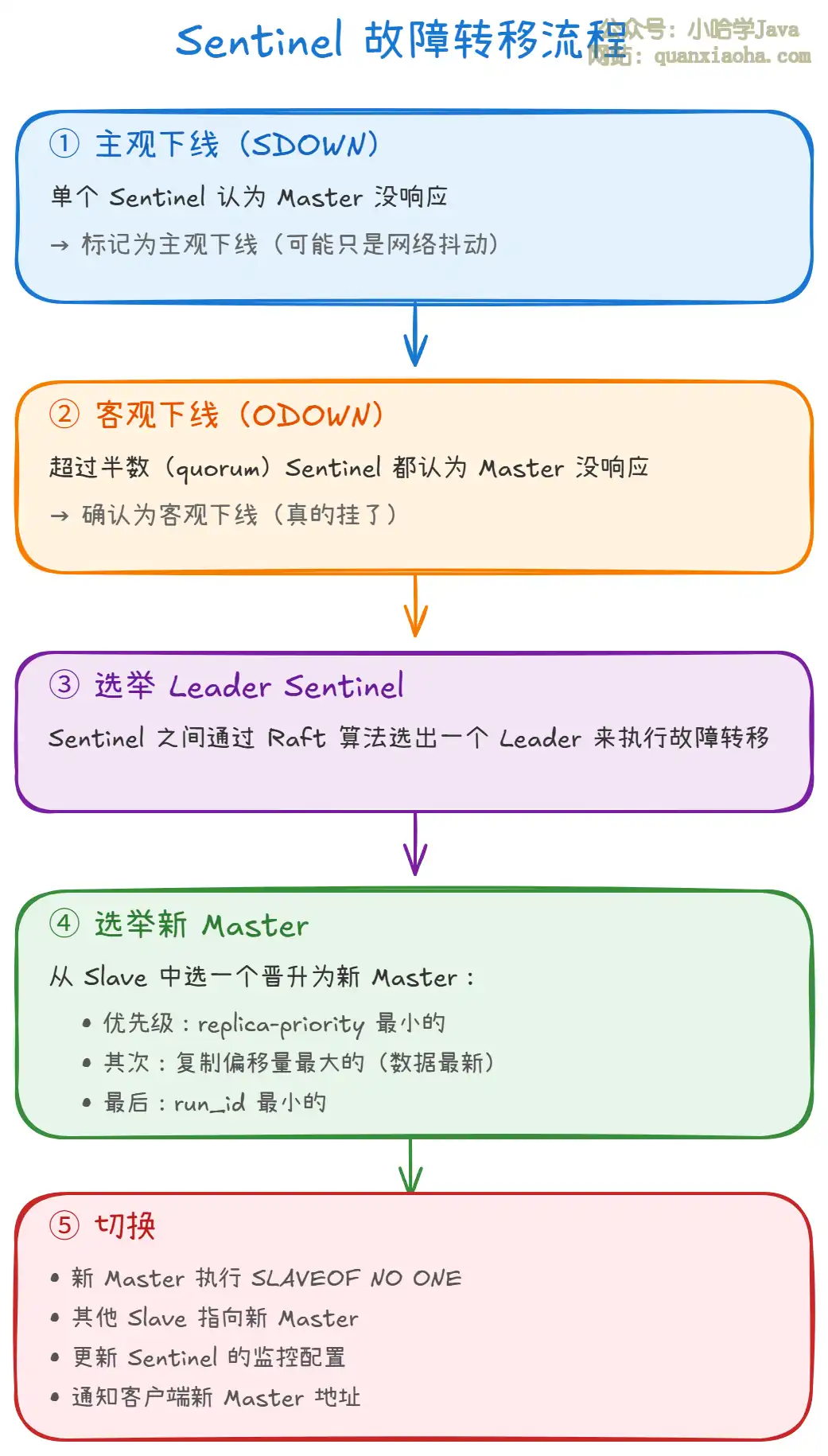
上图展示了 Sentinel 故障转移的完整流程:
- 主观下线(SDOWN):单个 Sentinel 认为 Master 没有响应。可能只是网络抖动,不一定真的挂了。
- 客观下线(ODOWN):超过
quorum个 Sentinel 都认为 Master 没响应,确认为真的挂了。 - 选举 Leader Sentinel:Sentinel 集群通过 Raft 算法选出一个 Leader 来执行故障转移。
- 选举新 Master:从 Slave 中按优先级选择 ——
replica-priority最小的优先,相同时选复制偏移量最大的(数据最新),再相同选run_id最小的。 - 切换:新 Master 执行
SLAVEOF NO ONE断开复制,其他 Slave 指向新 Master,Sentinel 通知客户端新地址。
三、Cluster 模式
主从和哨兵的写操作都在单个 Master 上,无法水平扩展。当数据量或 QPS 超过单节点上限时,就需要 Cluster。
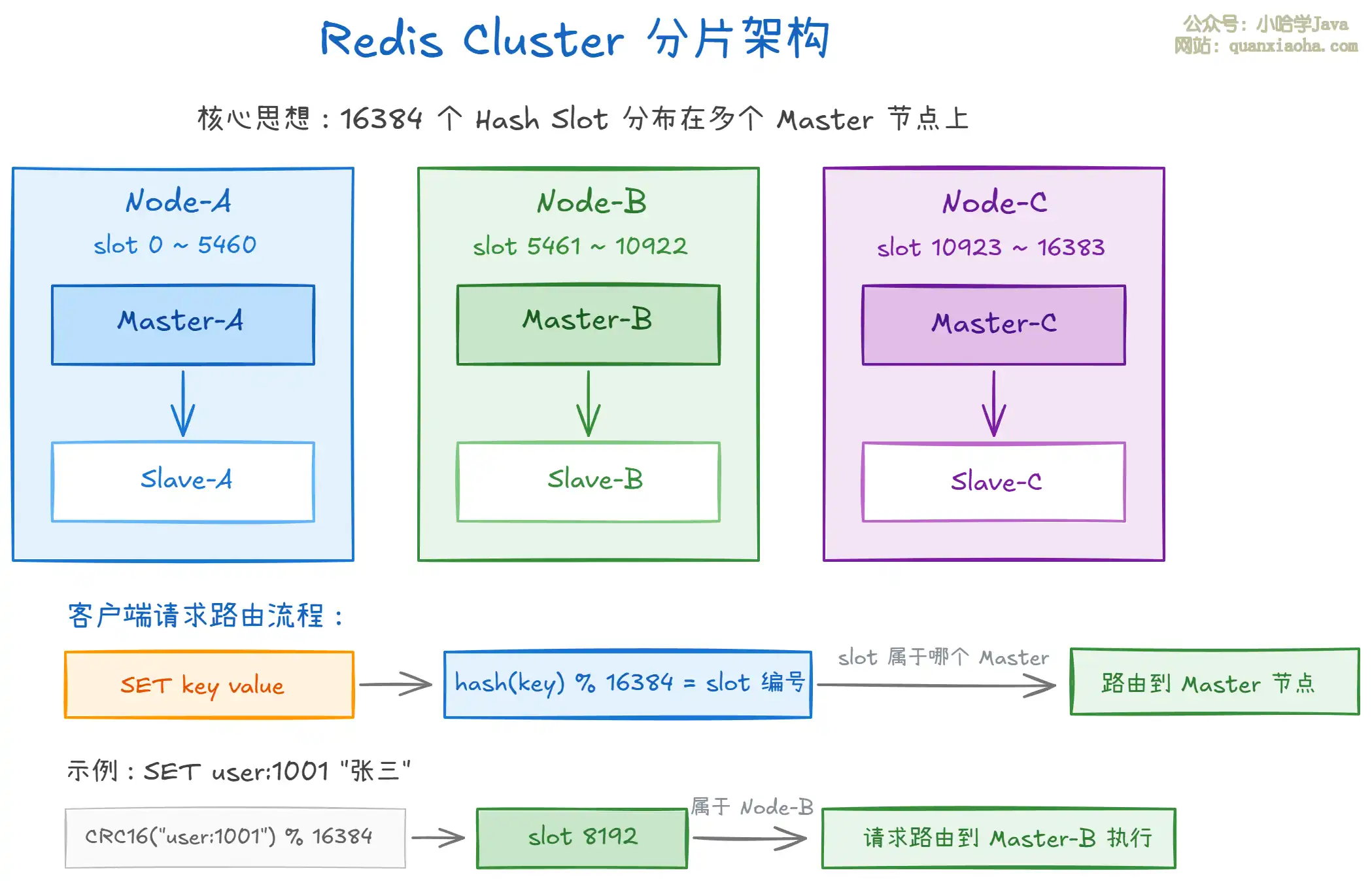
上图展示了 Redis Cluster 的分片架构:
- 16384 个 Hash Slot:Cluster 将所有数据划分为 16384 个 slot,分配给不同的 Master 节点。每个 Master 负责一部分 slot。
- 路由机制:客户端发送命令时,先对 key 做
CRC16(key) % 16384计算 slot 编号,再路由到负责该 slot 的 Master 节点。 - 每个 Master 配备 Slave:保证高可用。Master 宕机时,Slave 自动晋升为新 Master。
Cluster 的核心机制:
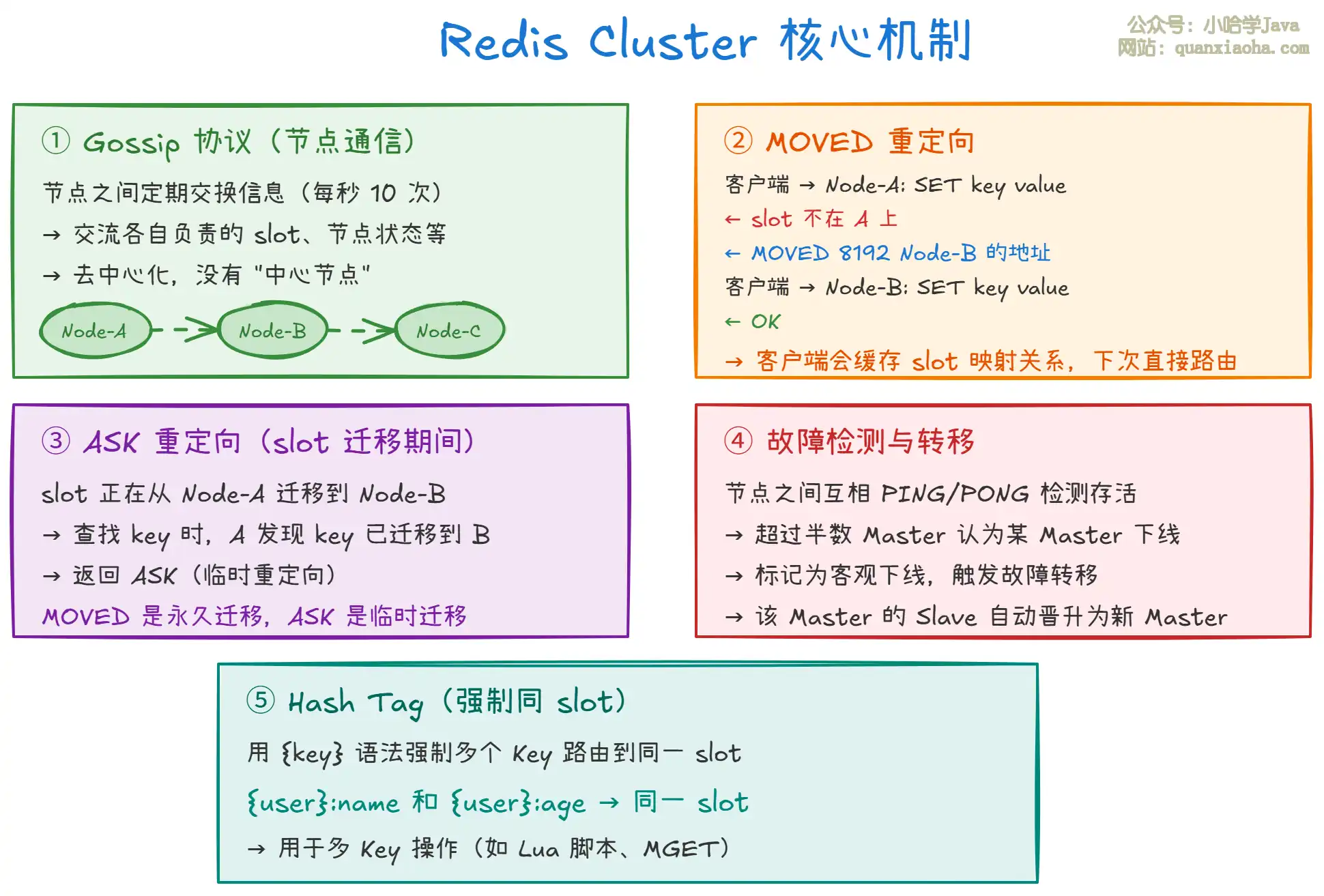
上图展示了 Cluster 的五个核心机制:
- Gossip 协议:节点之间定期交换状态信息(各自负责的 slot、节点存活状态等),去中心化,没有单点。
- MOVED 重定向:客户端请求到了错误的节点,该节点返回
MOVED指令告诉客户端正确的节点地址。客户端会缓存这个映射关系,下次直接路由。 - ASK 重定向:slot 迁移期间的临时重定向。
MOVED表示 slot 已永久迁移,ASK表示正在迁移中临时重定向。 - 故障检测与转移:节点互相 PING 检测存活,超过半数 Master 认为某节点下线,就触发故障转移,该节点的 Slave 晋升为新 Master。
- Hash Tag:用
{key}语法强制多个 Key 路由到同一 slot。比如{user}:name和{user}:age会落在同一个 slot 上,这样可以对它们做MGET或 Lua 脚本操作。
四、三种模式对比
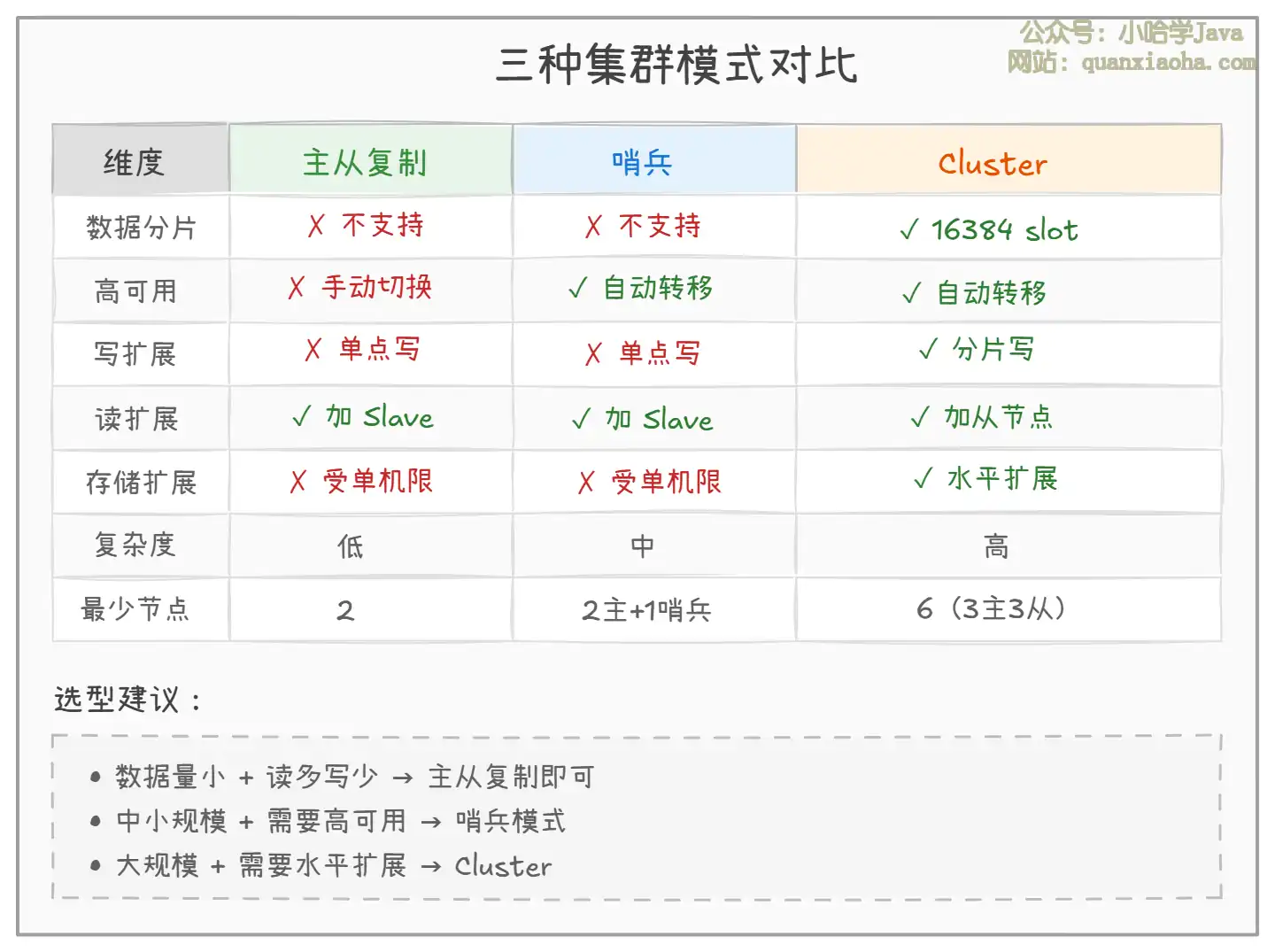
上图对比了三种集群模式的核心差异:
- 数据分片:只有 Cluster 支持数据分片(16384 slot),主从和哨兵的所有数据都在单个 Master 上。
- 高可用:主从复制需要人工切换,哨兵和 Cluster 都支持自动故障转移。
- 写扩展:主从和哨兵的写操作只能在单个 Master 上,Cluster 通过分片实现了写扩展。
- 存储扩展:主从和哨兵的存储受单机内存限制,Cluster 通过分片可以水平扩展存储容量。
- 复杂度:主从最简单,哨兵中等,Cluster 最复杂(需要考虑 slot 迁移、跨 slot 操作等)。
五、Cluster 的限制

上图列出了 Cluster 的主要限制:
- 多 Key 操作限制:
MGET、MSET等批量操作要求所有 Key 在同一 slot 上。解决方案是使用 Hash Tag(如{user}:name、{user}:age)。 - Lua 脚本限制:Lua 脚本操作的所有 Key 必须在同一 slot。
- 事务限制:
MULTI/EXEC事务中的 Key 也必须在同一 slot。 - 最小节点数:官方推荐至少 6 个节点(3 主 3 从),保证 slot 分布和高可用。
- 数据一致性:主从复制是异步的,Master 宕机时可能丢失少量尚未同步的数据。Cluster 追求的是高可用 + 最终一致性,不是强一致性。
面试高频追问
-
追问一:为什么 Cluster 用 16384 个 slot,而不是更多或更少?
Redis 作者 antirez 在 GitHub 上回答过这个问题。主要原因:节点之间通过 Gossip 协议交换 slot 映射信息,16384 个 slot 只需 2KB 的 bitmap 就能表示。如果 slot 数太多(如 65536),每个节点发送的 heartbeat 包就会变大,浪费网络带宽。16384 对于大多数集群规模(1000 个节点以内)完全够用。
-
追问二:Cluster 中某个 Master 和它的 Slave 同时宕机怎么办?
如果某个 slot 范围内的所有节点(Master + 所有 Slave)都宕机了,那这部分数据就完全不可用了。Cluster 有两种配置:
cluster-require-full-coverage yes(默认,只要有 slot 不可用,整个集群停止服务)和cluster-require-full-coverage no(只有不可用的 slot 的请求会报错,其他 slot 正常服务)。生产环境一般设为no。 -
追问三:客户端连接 Cluster 需要注意什么?
客户端需要支持 Cluster 协议(如 JedisCluster、Lettuce)。连接时不需要知道所有节点地址,只需要一个或几个节点地址,客户端会自动发现集群拓扑。请求到错误节点时会收到
MOVED重定向,客户端需要自动重试。智能客户端会缓存 slot → node 映射关系,后续请求直接路由。
常见面试变体
- 变体一:"Redis 主从复制原理是什么?"
- 变体二:"Redis 哨兵的故障转移流程是怎样的?"
- 变体三:"Redis Cluster 的路由机制是怎样的?"
- 变体四:"Redis Cluster 和 Sentinel 怎么选?"
记忆口诀
三种模式演进:主从(备份 + 读扩展)→ 哨兵(+ 自动故障转移)→ Cluster(+ 数据分片 + 写扩展)。
Cluster 核心:16384 slot 分片,CRC16 路由,Gossip 通信,自动故障转移。
Cluster 限制:多 Key 操作需同 slot,Lua/事务也受限制,异步复制非强一致。
选型:小规模哨兵,大规模 Cluster,数据备份用主从。
总结
Redis 有三种集群模式:主从复制 实现数据冗余和读写分离;哨兵模式 在主从基础上增加自动故障转移;Cluster 模式 通过 16384 slot 分片实现水平扩展。生产环境大规模场景用 Cluster(分片 + 高可用),中小规模用 Sentinel + 主从(高可用)。Cluster 的核心限制是跨 slot 操作需使用 Hash Tag,且异步复制不保证强一致性。