Redis 数据类型有哪几种?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道你能背出几个类型名称,更是想看你是否了解每种类型的特点和适用场景,能否在实际项目中做出合理选型。
-
底层原理:考察你是否理解 Redis 各数据类型的底层编码实现(如
ziplist、quicklist、hashtable等),这体现了你对 Redis 性能优化的理解深度。 -
实战经验:能否结合具体业务场景说明使用哪种数据类型,体现的不是 "会用 API",而是 "知道为什么这么用"。
核心答案
Redis 提供 5 种基础数据类型 + 4 种扩展数据类型,共计 9 种:
| 数据类型 | 底层编码 | 说明 | 典型场景 |
|---|---|---|---|
String |
int / embstr / raw |
最基本的类型,可存字符串、整数、浮点数 | 缓存、计数器、分布式锁 |
List |
quicklist(双向链表 + ziplist) |
有序可重复的字符串列表 | 消息队列、最新消息排行 |
Hash |
ziplist / hashtable |
键值对集合,类似 Java 的 HashMap |
存储对象、用户信息 |
Set |
intset / hashtable |
无序不重复的字符串集合 | 标签、共同好友、去重 |
ZSet(Sorted Set) |
ziplist / skiplist + hashtable |
有序不重复集合,每个元素关联一个 score |
排行榜、延迟队列 |
| 扩展类型 | 说明 | 典型场景 |
|---|---|---|
Bitmap |
位操作,基于 String 实现 |
签到打卡、用户活跃统计 |
HyperLogLog |
基数估算,基于 String 实现 |
UV 统计(允许误差) |
GEO |
地理位置信息,基于 ZSet 实现 |
附近的人、距离计算 |
Stream |
消息流(Redis 5.0 新增) | 消息队列(比 List 更完善) |
深度解析
一、五种基础数据类型
1. String(字符串)
String 是 Redis 中最简单的数据类型,一个 Key 对应一个 Value。它可以存储字符串、整数、浮点数,最大能存 512MB 的数据。
底层编码有三种:
int:当值为整数且不超过long范围时使用,8 字节长整型embstr:当字符串长度 ≤ 44 字节时使用,一次内存分配,紧凑存储raw:当字符串长度 > 44 字节时使用,SDS(Simple Dynamic String)实现
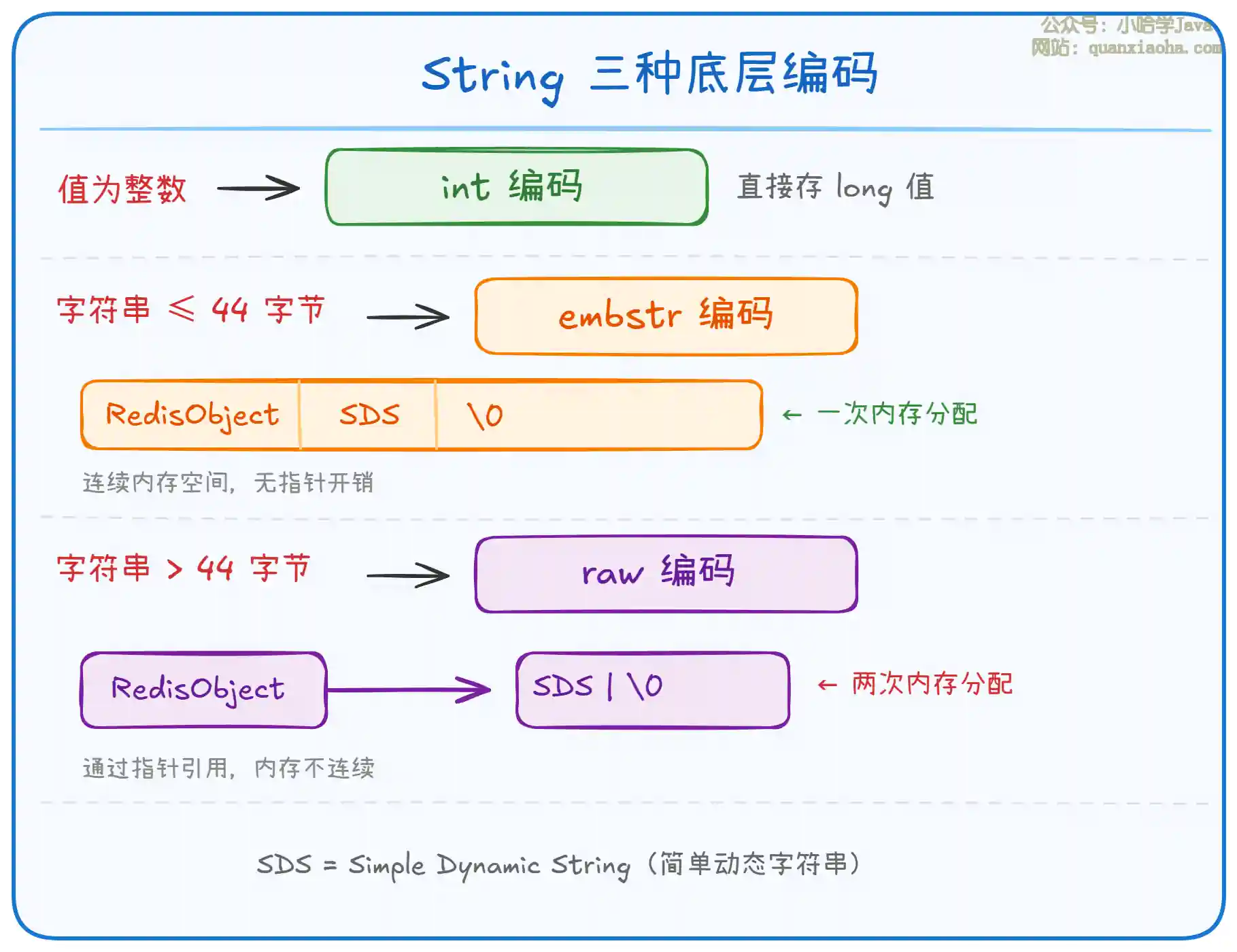
上图展示了 String 类型在不同场景下的三种编码方式。关键点如下:
-
int编码:值为整数时,直接存储在RedisObject的ptr字段中,无需额外分配内存,效率最高。 -
embstr编码:短字符串(≤ 44 字节)时,RedisObject和SDS在一次内存分配中连续存放,CPU 缓存命中率高,分配和释放都只需一次操作。 -
raw编码:长字符串(> 44 字节)时,RedisObject和SDS分开分配,ptr指针指向独立的SDS内存块。需要两次内存分配,但不受连续内存的限制。
常见使用场景:
# 简单缓存
SET user:1001 "张三"
GET user:1001
# 计数器(原子操作)
SET article:1001:views 0
INCR article:1001:views # views + 1
INCRBY article:1001:views 10 # views + 10
# 分布式锁
SET lock:order:1001 "unique_id" NX EX 30
2. List(列表)
List 是一个有序可重复的字符串链表,支持从两端插入和弹出元素。
底层采用 quicklist(快速列表)实现,它是 ziplist(压缩列表) + 双向链表的组合体。
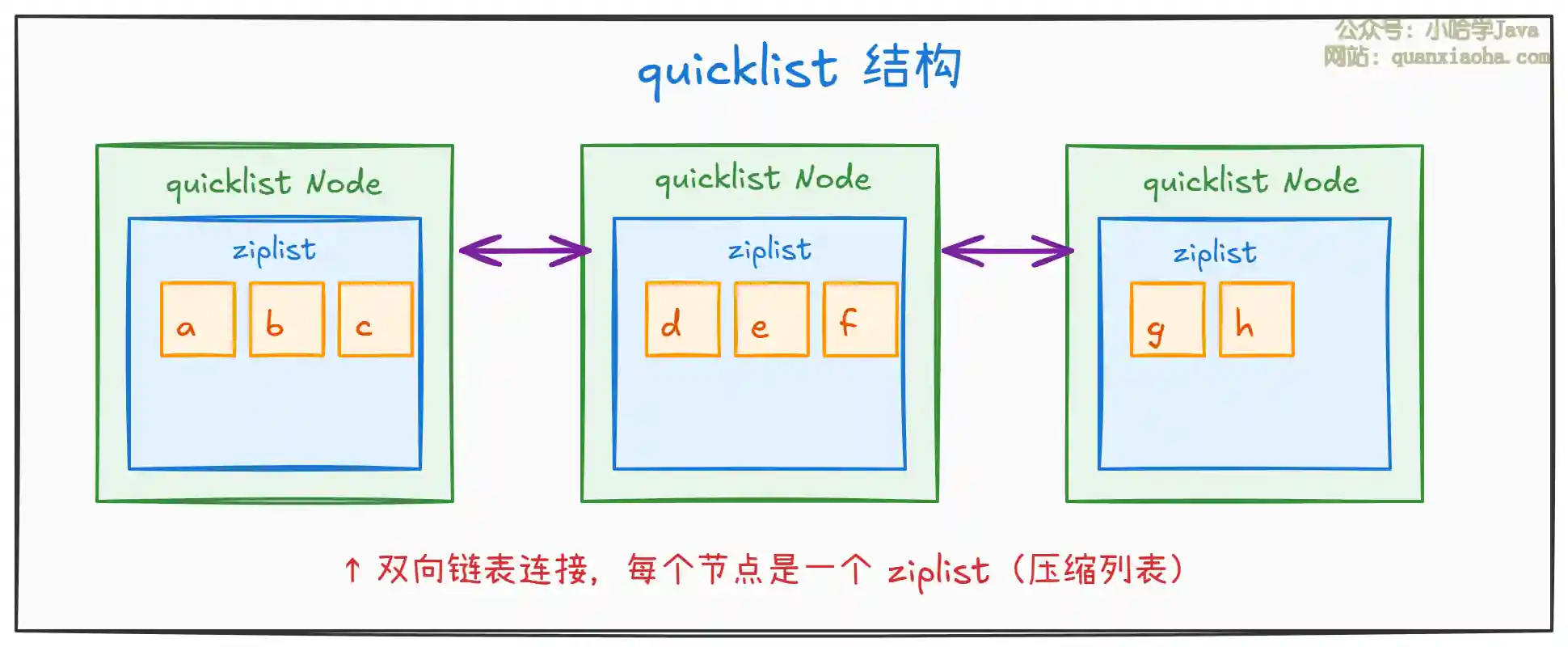
上图展示了 List 底层的 quicklist 结构。核心设计思想:
-
双向链表:每个节点(
quicklistNode)通过prev和next指针相连,支持双向遍历。 -
每个节点是一个
ziplist:不是每个元素一个节点,而是一个节点存多个连续元素(ziplist),兼顾内存紧凑和操作效率。 -
为什么这样设计:纯双向链表每个元素都有前后指针,内存开销大;纯
ziplist虽然紧凑,但元素太多时插入删除需要大量内存搬移。quicklist取两者之长,每个ziplist节点控制在合理大小(默认 8KB),中间节点还可以用 LZF 压缩。
常见使用场景:
# 消息队列(LPUSH + BRPOP 实现阻塞队列)
LPUSH queue:task "task_data"
BRPOP queue:task 30 # 阻塞等待 30 秒
# 最新列表(如朋友圈时间线)
LPUSH timeline:user:1001 "msg_id:2001"
LRANGE timeline:user:1001 0 9 # 获取最新 10 条
3. Hash(哈希)
Hash 是一个键值对集合,类似 Java 中的 HashMap,适合用来存储对象。
底层编码有两种:
ziplist:当元素数量较少(默认 ≤ 128 个)且所有值都较短(默认 ≤ 64 字节)时使用hashtable:当不满足ziplist条件时,转为真正的哈希表
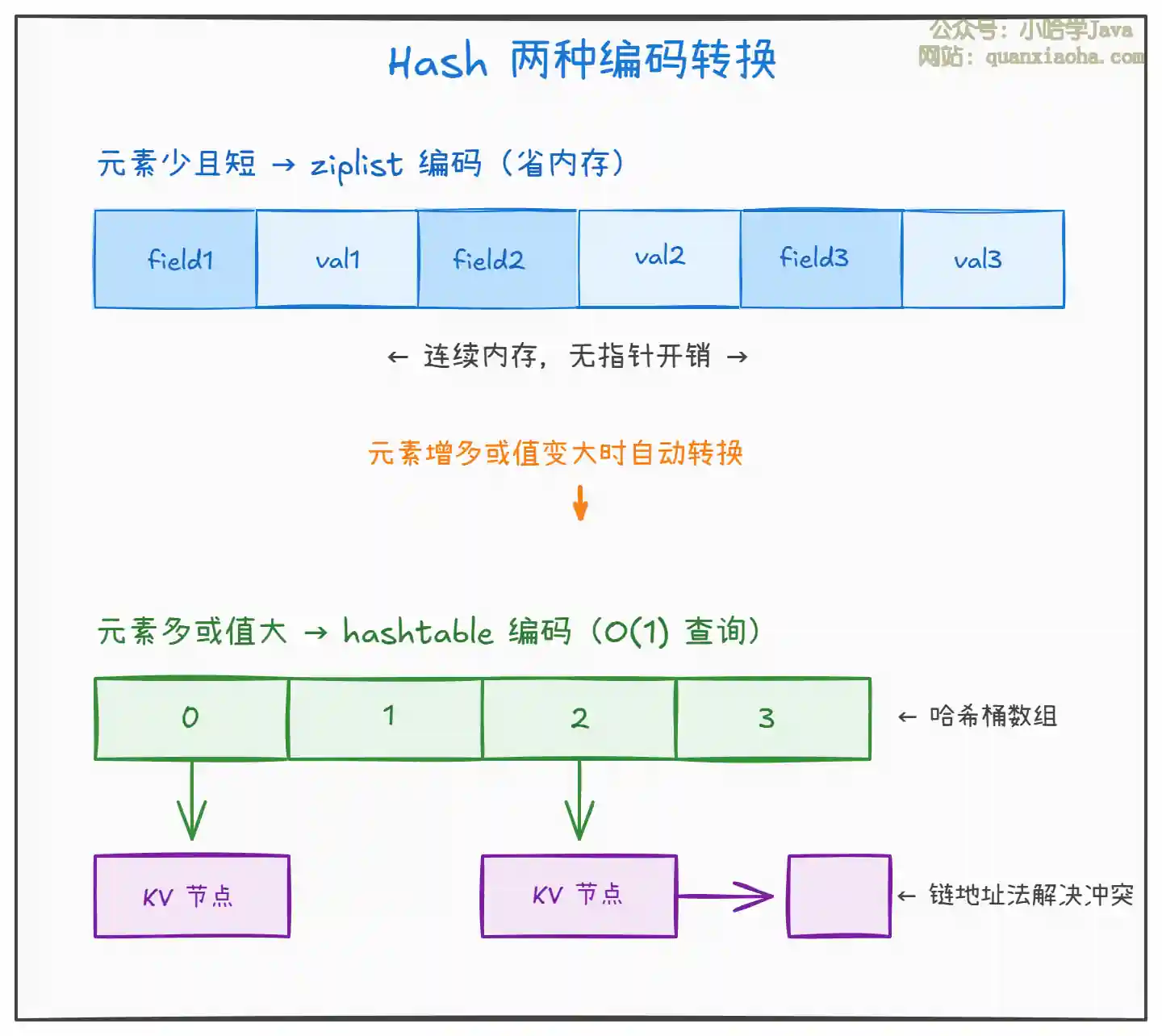
上图展示了 Hash 类型的两种编码及转换逻辑:
-
ziplist编码:字段和值以连续的方式存储在压缩列表中,没有指针开销,内存极其紧凑。适合存储少量字段的对象。缺点是查找时需要遍历,时间复杂度 O(n),但元素少时影响可忽略。 -
hashtable编码:与 Java 的HashMap类似,通过哈希函数定位桶,再用链地址法处理哈希冲突。查找时间复杂度 O(1)。当元素增多或值变大时自动从ziplist转换过来。
常见使用场景:
# 存储用户信息
HMSET user:1001 name "张三" age 25 city "北京"
HGET user:1001 name # "张三"
HMGET user:1001 name age # "张三" "25"
# 修改单个字段(不需要读取整个对象)
HSET user:1001 age 26
小贴士:相比用
String存储 JSON 对象,Hash的优势在于可以只读写单个字段,无需序列化/反序列化整个对象,既省带宽又省时间。
4. Set(集合)
Set 是一个无序不重复的字符串集合,支持集合间的交集、并集、差集运算。
底层编码有两种:
intset(整数集合):当所有元素都是整数且数量 ≤ 512 时使用hashtable:不满足上述条件时使用,Value 全部设为null

常见使用场景:
# 标签系统
SADD article:1001:tags "Java" "Redis" "面试"
SMEMBERS article:1001:tags
# 共同好友(交集)
SINTER user:1001:friends user:1002:friends
# 去重
SADD unique:visitors "192.168.1.1"
SISMEMBER unique:visitors "192.168.1.1" # 判断是否已存在
5. ZSet(有序集合)
ZSet(Sorted Set)在 Set 的基础上,给每个元素关联一个 score(分数),按分数自动排序。
底层编码有两种:
ziplist:元素少且短时使用skiplist+hashtable:元素较多时使用,跳表保证范围查询效率,哈希表保证 O(1) 查找分数
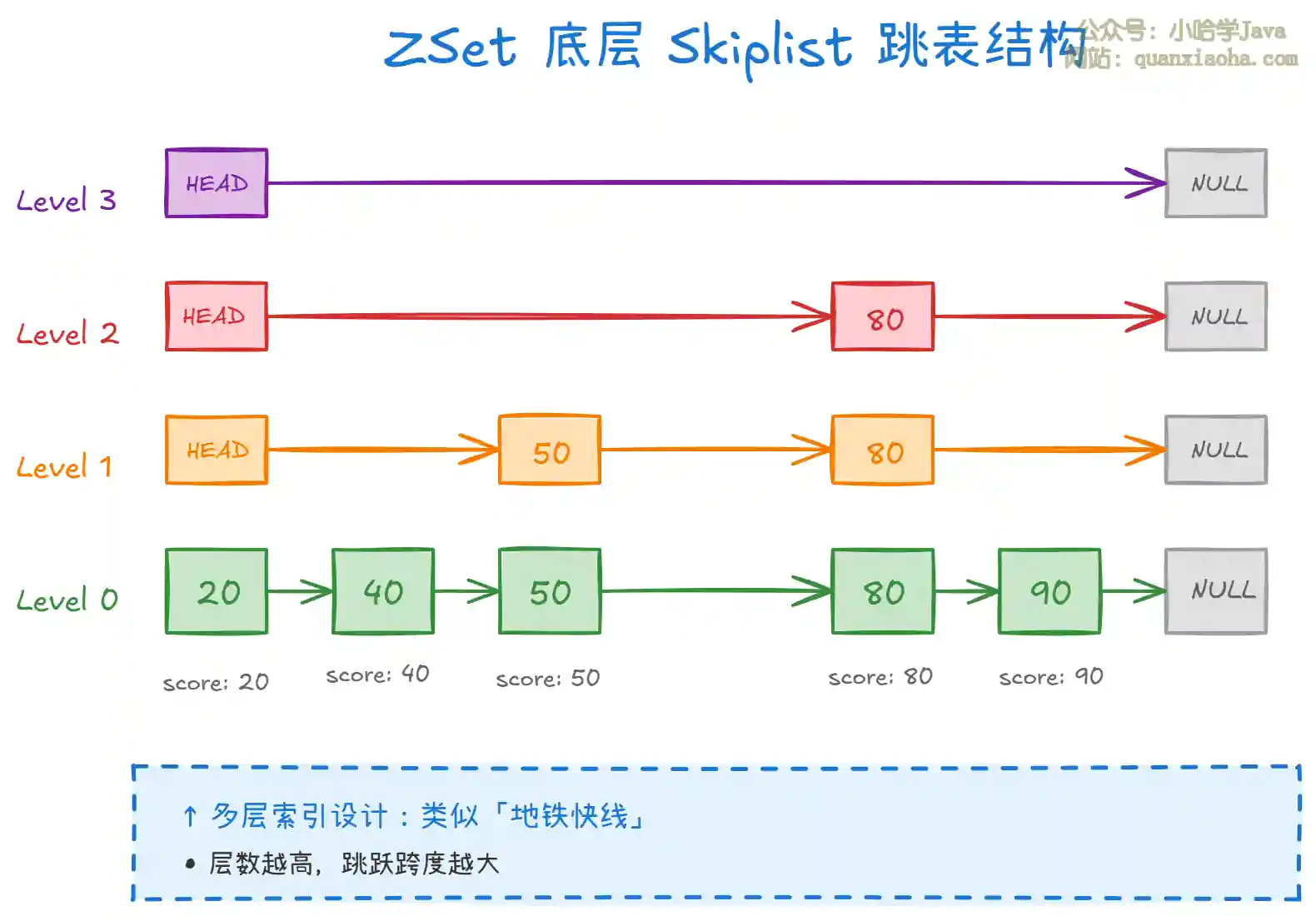
上图展示了 ZSet 底层的跳表(skiplist)结构。跳表的核心思想:
-
多层索引:每个节点随机决定层数,层数越高节点越少。查找时从最高层开始,逐层往下找,类似二分查找的思路。
-
查找效率:平均 O(logN),媲美红黑树,但实现更简单,范围查询更方便(只需在底层链表上遍历)。
-
为什么不用红黑树:跳表的范围查询更高效,实现更简单(不用旋转维护平衡),内存占用也可以通过调节层高来控制。
-
hashtable的作用:跳表虽然查找快,但按member查score仍需 O(logN)。配合hashtable后,可以通过member直接 O(1) 找到对应节点。
常见使用场景:
# 排行榜
ZADD rank:score 100 "张三" 95 "李四" 88 "王五"
ZREVRANGE rank:score 0 2 WITHSCORES # Top3
# 延迟队列(score 存时间戳)
ZADD delay:queue 1711500000000 "order:1001"
ZRANGEBYSCORE delay:queue 0 <当前时间戳> # 获取到期任务
二、四种扩展数据类型
1. Bitmap(位图)
基于 String 实现,把 String 当成 bit 数组来操作,适合处理海量布尔值数据。
# 用户签到(key=年月, offset=日期, value=0/1)
SETBIT sign:1001:202603 26 1 # 3 月 26 日签到
GETBIT sign:1001:202603 26 # 查询某天是否签到
BITCOUNT sign:1001:202603 # 统计本月签到天数
极其节省内存:一个月的签到数据只需约 4 字节(31 个 bit)。
2. HyperLogLog
基于概率的基数估算算法,标准误差 0.81%。每个 Key 只需 12KB 内存就能估算 2^64 个不同元素的基数。
# UV 统计
PFADD uv:20260327 "user1" "user2" "user3"
PFCOUNT uv:20260327 # 估算独立访客数
PFMERGE uv:week uv:mon uv:tue # 合并多天数据
3. GEO(地理位置)
基于 ZSet 实现,使用 GeoHash 编码经纬度为 score,支持距离计算和范围查询。
# 附近的人
GEOADD nearby 116.40 39.90 "天安门" 116.41 39.91 "王府井"
GEORADIUS nearby 116.40 39.90 1 km # 查找 1km 内的地点
GEODIST nearby "天安门" "王府井" km # 计算两点距离
4. Stream(消息流)
Redis 5.0 新增,是更完善的消息队列方案,支持消费组、消息确认、持久化,类似轻量版 Kafka。
# 生产消息
XADD stream:order * order_id 1001 amount 99.9
# 消费组消费
XGROUP CREATE stream:order group1 $
XREADGROUP GROUP group1 consumer1 COUNT 1 BLOCK 5000 STREAMS stream:order >
面试高频追问
-
追问一:
String的embstr和raw编码的边界值是多少?为什么是 44 字节?- Redis 7.0 之前边界是 44 字节(
RedisObject16 字节 +SDS头 3 字节 + 内容 +\0≤ 64 字节,刚好是jemalloc的一个内存块大小)。Redis 7.0 之后使用EmbeddedString,阈值为 44 字节。
- Redis 7.0 之前边界是 44 字节(
-
追问二:
ziplist什么时候会转换为hashtable或skiplist?- 两个条件满足任一即转换:元素数量超过阈值(
Hash/Set/ZSet默认 128)或单个元素大小超过阈值(默认 64 字节)。可通过hash-max-ziplist-entries、hash-max-ziplist-value等参数调整。
- 两个条件满足任一即转换:元素数量超过阈值(
-
追问三:
List在 Redis 3.2 之前和之后的实现有什么区别?- Redis 3.2 之前使用
ziplist或LinkedList;3.2 之后统一使用quicklist(ziplist+ 双向链表),兼顾内存和性能。
- Redis 3.2 之前使用
常见面试变体
- "Redis 中
Hash类型适合存储什么?和String存储 JSON 对象有什么区别?" - "Redis 的
ZSet底层是怎么实现的?为什么用跳表而不用红黑树?" - "Redis 有哪些适用于统计场景的数据类型?"
- "Redis
Stream和List做消息队列有什么区别?"
记忆口诀
五大基础类型:"串列哈集序"(String、List、Hash、Set、ZSet)
底层编码:小数据用 ziplist 省内存,大数据用 hashtable / skiplist 保性能,Redis 自动切换无需操心。
扩展类型:"位超地流"(Bitmap、HyperLogLog、GEO、Stream)—— 位图算签到、超日志算 UV、地理查附近、流式做消息。
总结
Redis 共有 5 种基础数据类型(String、List、Hash、Set、ZSet)和 4 种扩展类型(Bitmap、HyperLogLog、GEO、Stream)。每种类型都有多种底层编码实现,Redis 会根据数据量自动选择最优编码。面试时不仅要能说出类型名称,更要理解底层结构、编码转换条件和实际业务场景的选型依据。