Redis Key 和 Value 的设计原则有哪些?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观

面试考察点
-
生产实践意识:面试官不仅仅是想知道你背了几条规范,更是想考察你在真实项目中是否有良好的 Redis 使用习惯,能不能避免 "Key 乱起名、Value 随便存" 的野路子做法。
-
性能优化思维:Key 和 Value 的设计直接影响内存占用、查询效率、可维护性,考察你是否具备从细节处优化系统的意识。
-
系统设计能力:合理的 Key 命名规范和 Value 选型是团队协作和系统可维护性的基础,体现的是你的工程素养。
核心答案
Redis Key 和 Value 的设计原则可以归纳为 Key 命名 5 条 + Value 设计 4 条:
| 分类 | 原则 | 核心要点 |
|---|---|---|
| Key | 可读性 | 冒号分层,见名知意,如 user:info:1001 |
| Key | 业务隔离 | 加业务前缀,避免冲突 |
| Key | 长度控制 | 别太长(费内存),别太短(不可读) |
| Key | 设置过期 | 避免永久 Key 堆积导致内存泄漏 |
| Key | 避免大 Key | 单个 Key 的 Value 不宜过大 |
| Value | 选对数据类型 | Hash 存对象,ZSet 做排序,别全用 String |
| Value | 控制大小 | Value 尽量精简,避免存大数据 |
| Value | 合理序列化 | 选紧凑的序列化方案(JSON / Protobuf) |
| Value | 数据压缩 | 大 Value 考虑压缩后存储 |
一句话结论:Key 要 "可读、隔离、可控、可过期",Value 要 "选对类型、控制大小、合理编码"。
深度解析
一、Key 命名原则
1. 冒号分层,见名知意
Key 的命名应该像文件路径一样分层,用冒号 : 分隔,让人一眼就能看懂这个 Key 存的是什么。
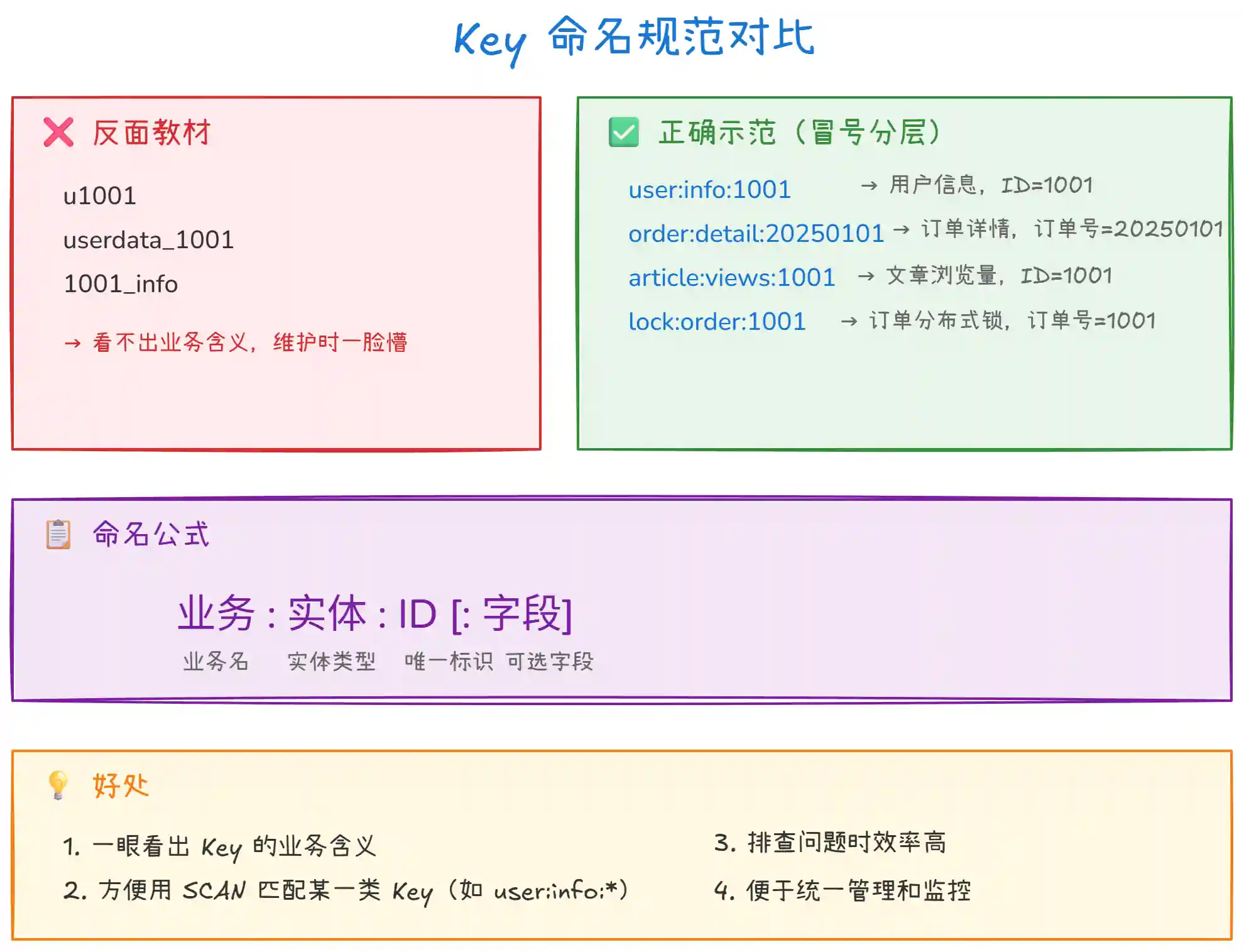
上图的要点:
-
反面教材:Key 命名太随意,
u1001、userdata_1001这些写法,过两个月你自己都看不懂,更别提交给其他同事维护。 -
正确示范:用冒号
:分层,格式为 "业务:实体:ID[:字段]"。比如user:info:1001一眼就知道是用户信息,用户 ID 是 1001。排查问题时可以直接GET user:info:1001查看数据。 -
冒号
:是约定俗成的分隔符:Redis 客户端工具(如 RedisInsight、Another Redis Desktop Manager)也默认用冒号做层级展示,用其他符号就没有这个效果。
2. 加业务前缀,避免冲突
多个业务共用一个 Redis 实例时,必须加业务前缀做隔离。
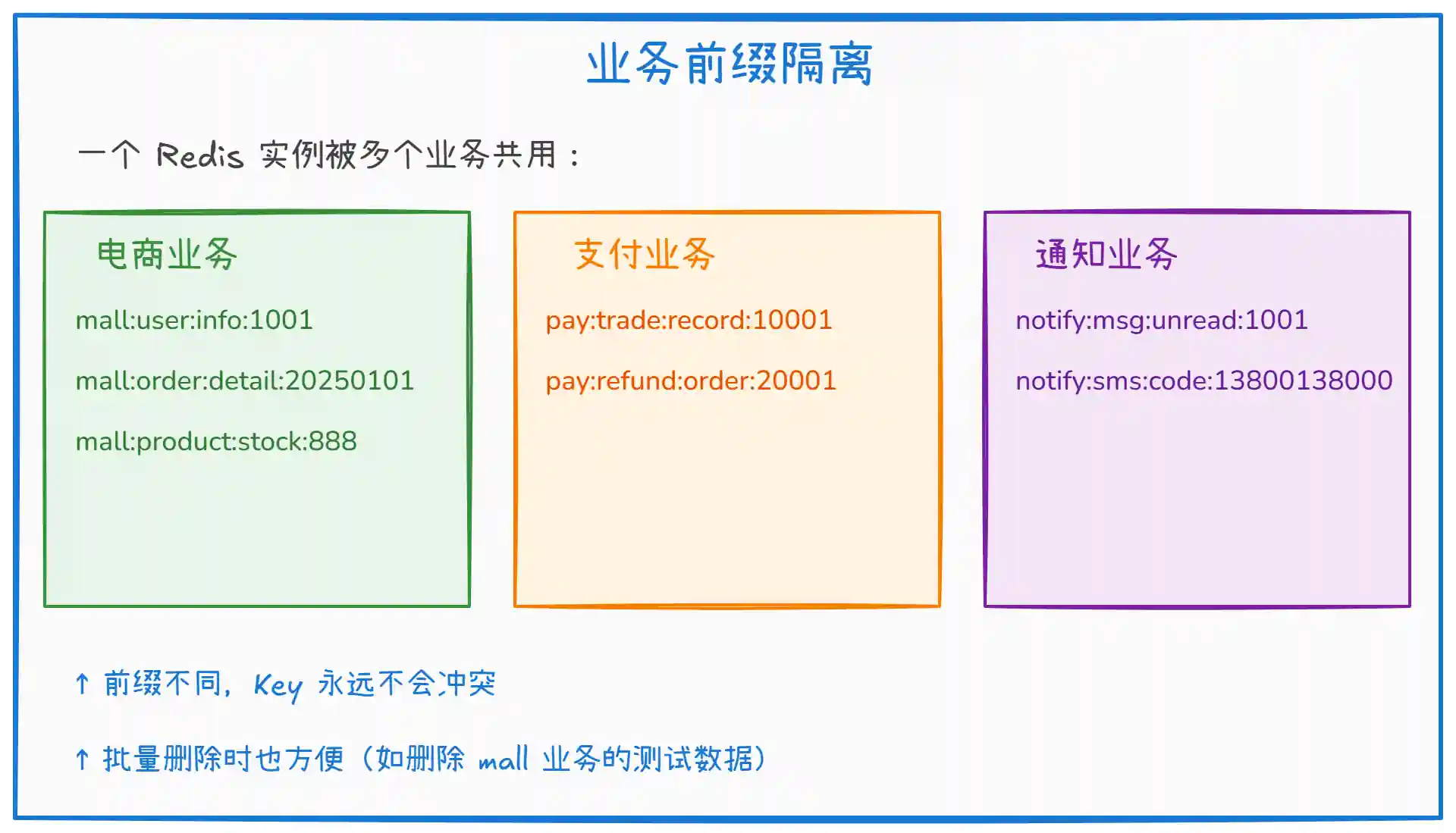
上图展示了业务前缀隔离的用法:
-
多个业务共用 Redis 时,如果 Key 不加前缀,A 业务的
user:info:1001和 B 业务的user:info:1001就冲突了。加个业务前缀(如mall、pay、notify)就能彻底避免。 -
清理数据也方便:比如要删除某个业务的全部测试数据,可以直接按前缀匹配
SCAN删除。
3. 控制长度,权衡可读性和内存
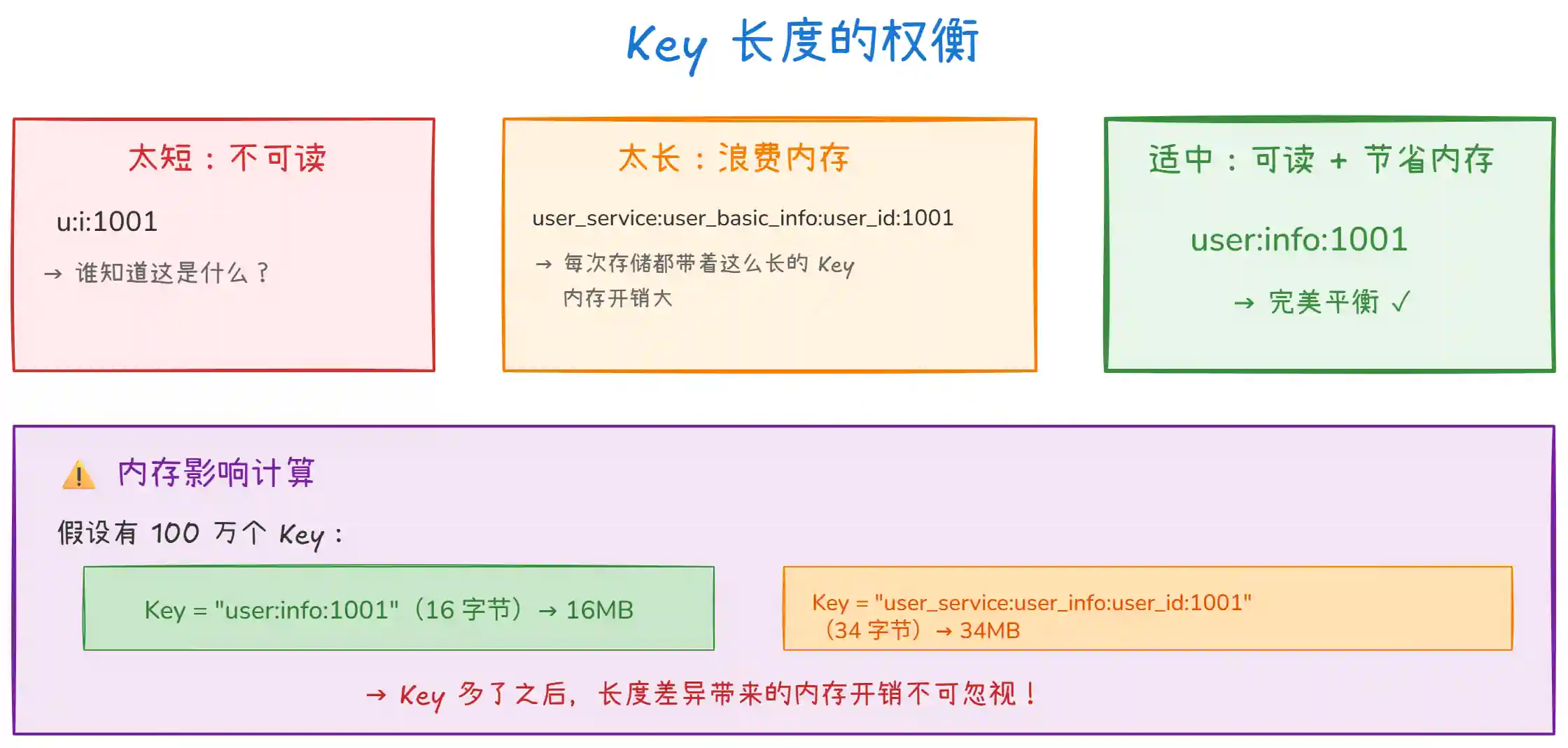
上图说明了 Key 长度的权衡:
-
太短不可读:
u:i:1001省了几个字节,但过两个月你自己都不知道这存的啥。 -
太长费内存:100 万个 Key,每个 Key 多 20 字节,就多占 20MB。Key 数量再大一些,这个差距更明显。
-
适中原则:
user:info:1001这种长度,既能看懂含义,又不至于太长浪费内存。
4. 必须设置过期时间
这是最容易被忽视、但后果最严重的原则。
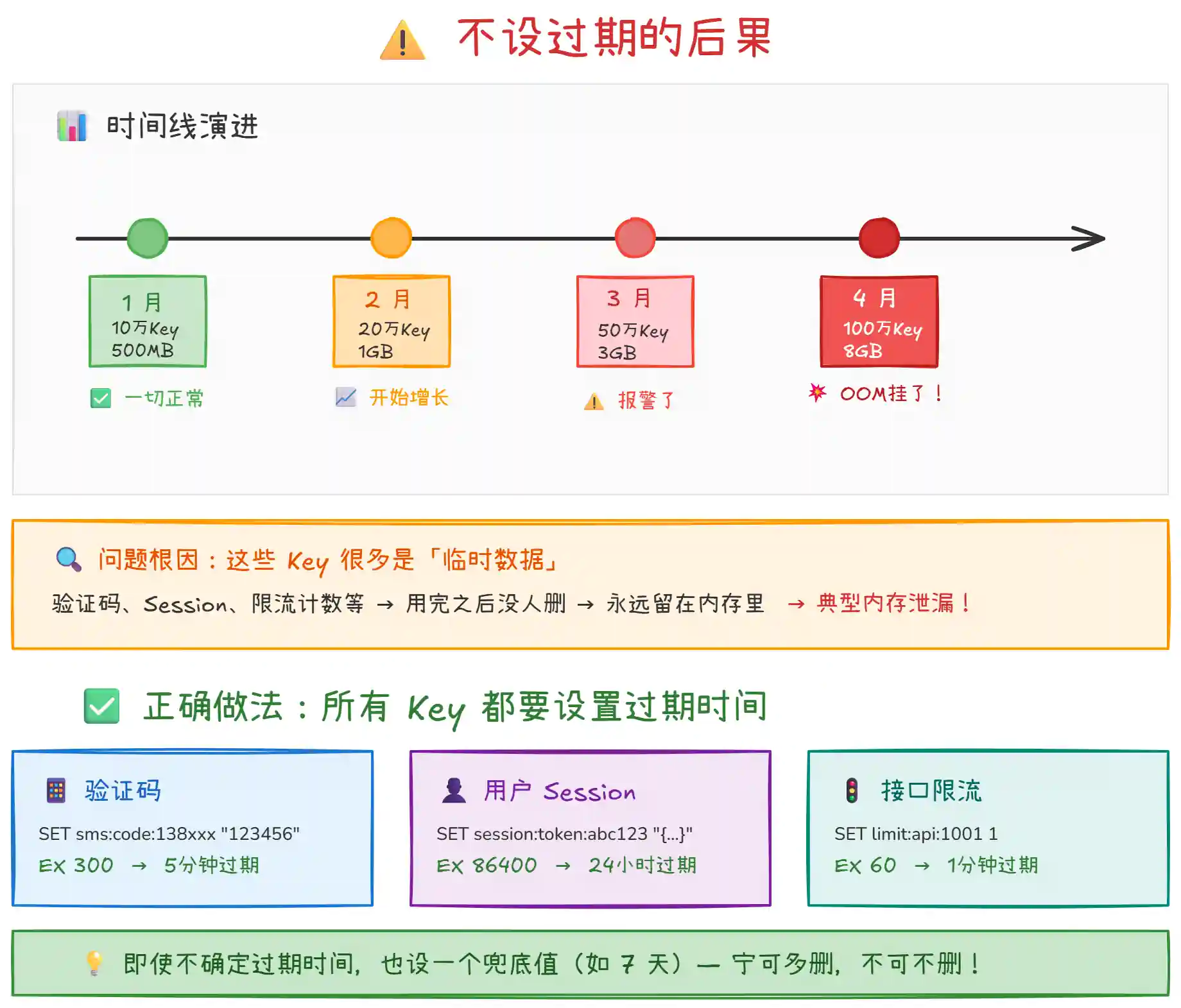
上图展示了不设过期时间的严重后果:
-
内存持续增长:不断写入新 Key,旧 Key 永远不删除,内存只增不减。几个月后 Redis 内存被打满,触发 OOM 或者淘汰策略,生产事故就来了。
-
所有 Key 都要设过期:即使是 "长期有效" 的缓存数据(如配置信息),也建议设一个较长的兜底过期时间(如 7 天、30 天),而不是永不过期。万一业务下线了、代码改了,至少过期后内存能自动回收。
5. 避免大 Key
大 Key 是 Redis 生产环境的 "头号杀手" 之一。

上图说明了大 Key 的定义和危害:
-
阻塞主线程:
DEL一个包含几万元素的 Hash,Redis 需要逐个释放,可能耗时几百毫秒。在这期间,其他所有请求都排队等待,造成请求超时。 -
网络拥塞:
HGETALL一个大 Hash 返回几 MB 数据,占满网卡带宽,影响同一节点上的所有请求。 -
解决方案:大 Value 压缩或拆分,大集合拆成小集合,删除用
UNLINK异步删除。
二、Value 设计原则
1. 选对数据类型
这是 Value 设计最重要的原则。很多开发者不管什么数据都往 String 里塞,JSON 一把梭,这在生产环境是大忌。
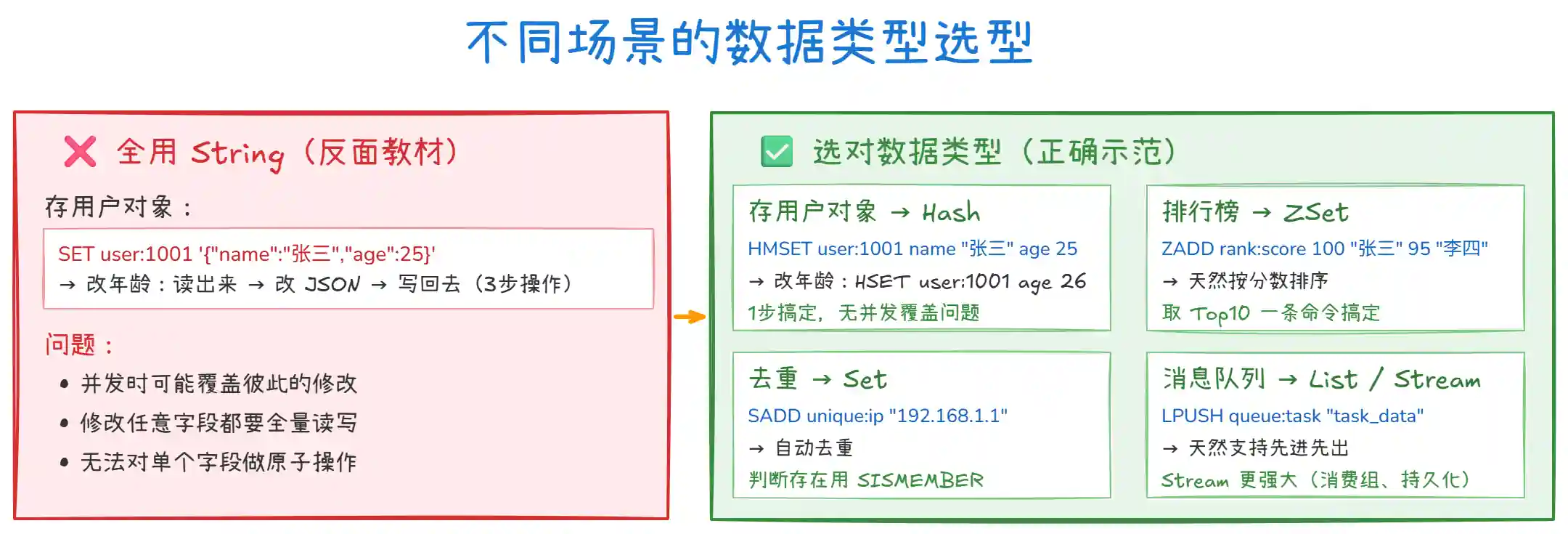
上图对比了 "全用 String" 和 "选对数据类型" 的差异:
-
用
String存对象的问题:修改某个字段需要 "读 → 改 → 写" 三步操作,并发时可能互相覆盖。而且每次都传整个 JSON,网络带宽也浪费。 -
用
Hash存对象:直接HSET改一个字段,一步到位,不涉及其他字段。既省带宽又避免了并发问题。 -
选型口诀:对象用
Hash、排序用ZSet、去重用Set、队列用List、计数用String。
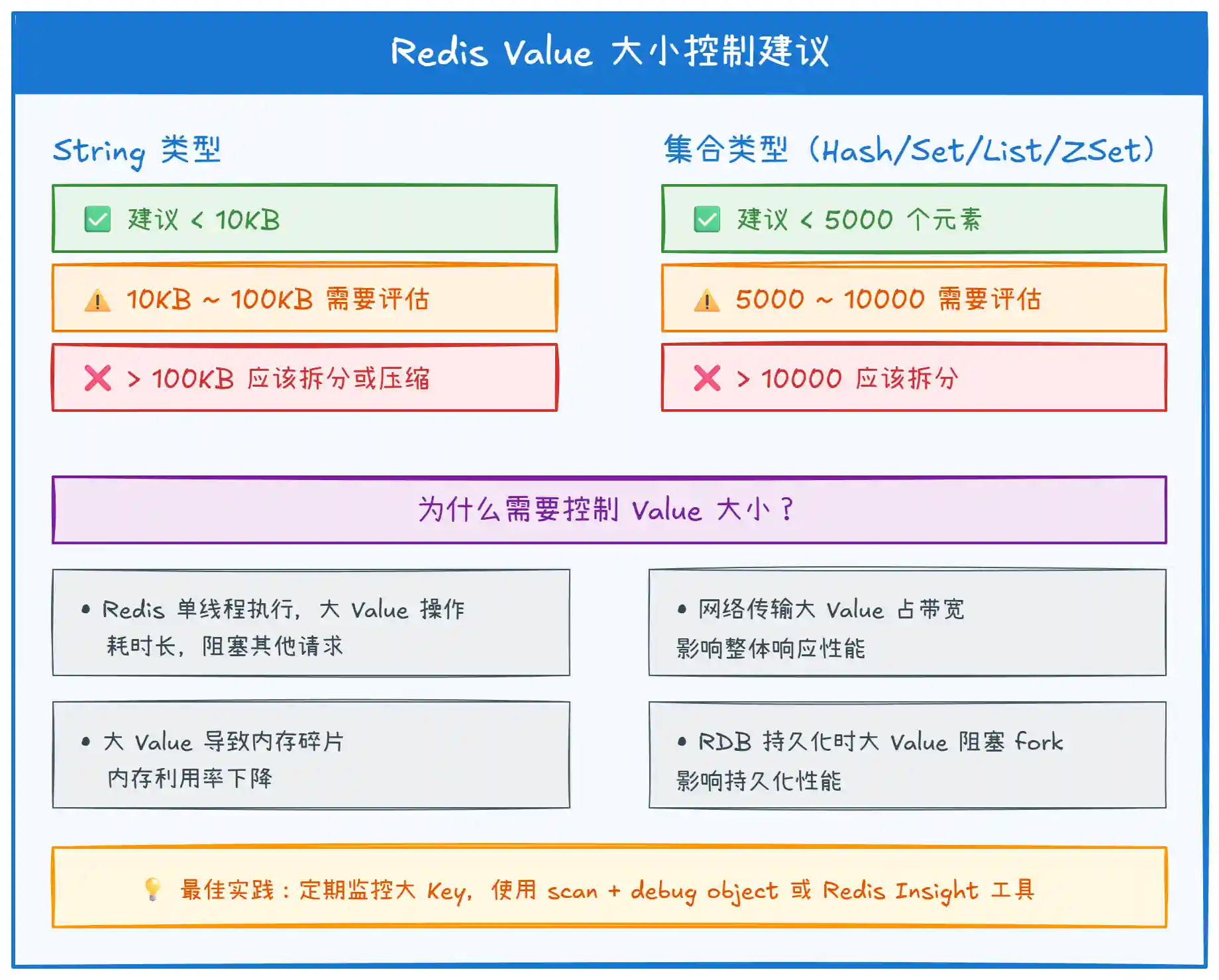
2. 控制Value 大小
3. 合理选择序列化方案
// ❌ 反面教材:用 Java 原生序列化
// 问题:体积大、不可跨语言、有安全风险
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(user);
byte[] bytes = bos.toByteArray(); // 体积可能比 JSON 大 3~5 倍
// ✅ 正确示范:用 JSON 或 Protobuf
// JSON:可读性好,调试方便,体积适中
String json = objectMapper.writeValueAsString(user);
redisTemplate.opsForValue().set("user:1001", json);
// Protobuf:体积最小(比 JSON 小 3~5 倍),适合对性能要求极高的场景
byte[] proto = user.toProtobuf();
redisTemplate.opsForValue().set("user:1001", proto);
序列化方案的选择建议:
| 序列化方案 | 体积 | 可读性 | 跨语言 | 适用场景 |
|---|---|---|---|---|
| Java 原生 | 大 | 不可读 | 仅 Java | ❌ 不推荐 |
| JSON | 中 | 可读 | 支持 | ✅ 通用推荐 |
| Protobuf | 小 | 不可读 | 支持 | ✅ 高性能场景 |
| MsgPack | 较小 | 不可读 | 支持 | JSON 的二进制版 |
4. 大 Value 考虑压缩
// Value 较大时,压缩后存储
String json = objectMapper.writeValueAsString(bigData);
// GZIP 压缩
ByteArrayOutputStream bos = new ByteArrayOutputStream();
GZIPOutputStream gzip = new GZIPOutputStream(bos);
gzip.write(json.getBytes(StandardCharsets.UTF_8));
gzip.close();
byte[] compressed = bos.toByteArray();
// 压缩率通常 60%~80%,10KB 压缩后可能只有 2~4KB
redisTemplate.opsForValue().set("data:big:1001", compressed);
压缩的取舍:
- 什么时候压缩:Value > 1KB 时考虑压缩,节省内存和网络带宽。
- 什么时候别压缩:Value < 1KB 时,压缩/解压的 CPU 开销可能比省下的内存更贵。
- 常用压缩算法:GZIP(压缩率高)、LZ4(速度极快)、Snappy(速度和压缩率平衡)。
面试高频追问
-
追问一:Redis 中大 Key 怎么排查?
- 用
redis-cli --bigkeys扫描找出最大的 Key。用MEMORY USAGE key查看单个 Key 的内存占用。用DEBUG OBJECT key查看 Value 的编码信息和长度。注意这些命令本身也可能阻塞,建议在从节点或低峰期执行。
- 用
-
追问二:大 Key 怎么删除才安全?
- 不要用
DEL(同步阻塞)。用UNLINK(Redis 4.0+,异步删除)。对于 Hash,用HSCAN+HDEL分批删除字段。对于 List,用LTRIM分批截断。对于 Set/ZSet,用SSCAN/ZSCAN+SREM/ZREM分批删除。
- 不要用
-
追问三:Key 的过期删除策略是什么?
- Redis 采用 "惰性删除 + 定期删除" 双重策略。惰性删除:访问 Key 时才检查是否过期,过期了就删除。定期删除:每 100ms 随机抽查一批 Key,过期的删掉。两种策略配合,既不会大量 Key 堆积,也不会频繁扫描消耗 CPU。
常见面试变体
- "Redis 的 Key 命名规范是什么?你们项目是怎么约定的?"
- "什么是大 Key?有什么危害?怎么处理?"
- "Redis 的 Value 应该怎么设计?不同场景选什么数据类型?"
- "你们项目中 Redis 用到了哪些数据类型?为什么这么选?"
记忆口诀
Key 原则:"冒号分层见名意,业务前缀防冲突,长度适中省内存,过期时间必须有,大 Key 拆分保稳定"。
Value 原则:"选对类型不瞎存,大小控制防阻塞,序列化要挑合适,大值压缩省空间"。
总结
Redis Key 设计的核心是 "可读 + 隔离 + 可控 + 可过期":冒号分层命名、加业务前缀、控制长度、必须设过期时间、避免大 Key。Value 设计的核心是 "选对类型 + 控制大小 + 合理编码":根据业务场景选择合适的 Redis 数据类型、控制单个 Value 的体积、选择紧凑的序列化方案、大 Value 考虑压缩。这些原则看似简单,但在生产环境中严格执行的系统,出问题的概率会大大降低。