什么是 Redis 热点 Key 问题,如何解决?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道热点 Key 的定义,更是想知道你是否能区分热点 Key 和大 Key 的不同(一个是 "访问太多",一个是 "数据太大"),以及热点 Key 对 Redis 集群的具体影响。
-
排查能力:考察你是否知道生产环境中如何发现热点 Key(
MONITOR、redis-cli --hotkeys、业务监控等),而不是等出了问题才去排查。 -
方案设计能力:能否针对不同场景给出对应的解决方案(本地缓存、读写分离、Key 分片),并说明各自的适用场景和优缺点。
核心答案
热点 Key 是指被大量客户端频繁访问的 Key,其 QPS 远高于其他 Key,导致单个 Redis 节点成为性能瓶颈。
| 维度 | 热点 Key | 大 Key |
|---|---|---|
| 问题本质 | 访问频率过高 | 数据体积过大 |
| 核心危害 | 单节点 CPU / 网络被打满 | 主线程阻塞、网络拥塞 |
| 典型场景 | 秒杀商品、热门文章、热搜话题 | 一个 10MB 的 JSON、百万级集合 |
| 解决思路 | 分散访问压力 | 拆分数据体积 |
一句话结论:热点 Key 的核心问题是 访问集中在一个节点上,解决方案是 本地缓存(减少请求)+ 读写分离(分散读压力)+ Key 分片(分散到多个节点)。
深度解析
一、热点 Key 到底有什么危害?
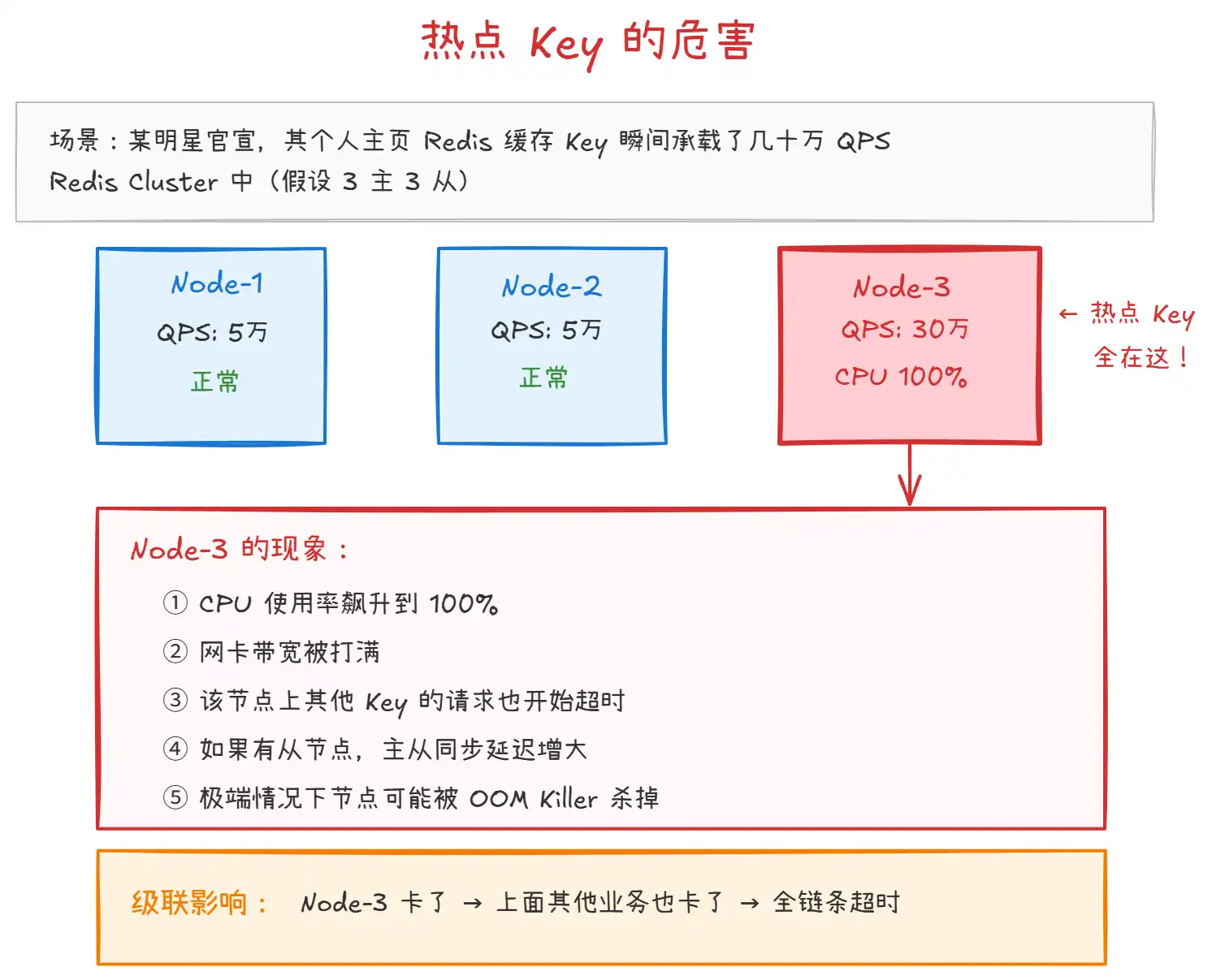
上图展示了热点 Key 在 Redis Cluster 中的危害:
- 单节点过载:热点 Key 集中在某个节点上,该节点的 CPU、网卡带宽被瞬间打满,而其他节点可能很空闲。
- 影响其他业务:同一节点上的其他 Key 也会因为资源被占满而响应变慢,产生 "邻居效应"。
- 主从同步延迟:如果热点 Key 涉及写操作,主节点压力大时,主从复制延迟增大,读从节点可能拿到旧数据。
二、热点 Key 的典型场景
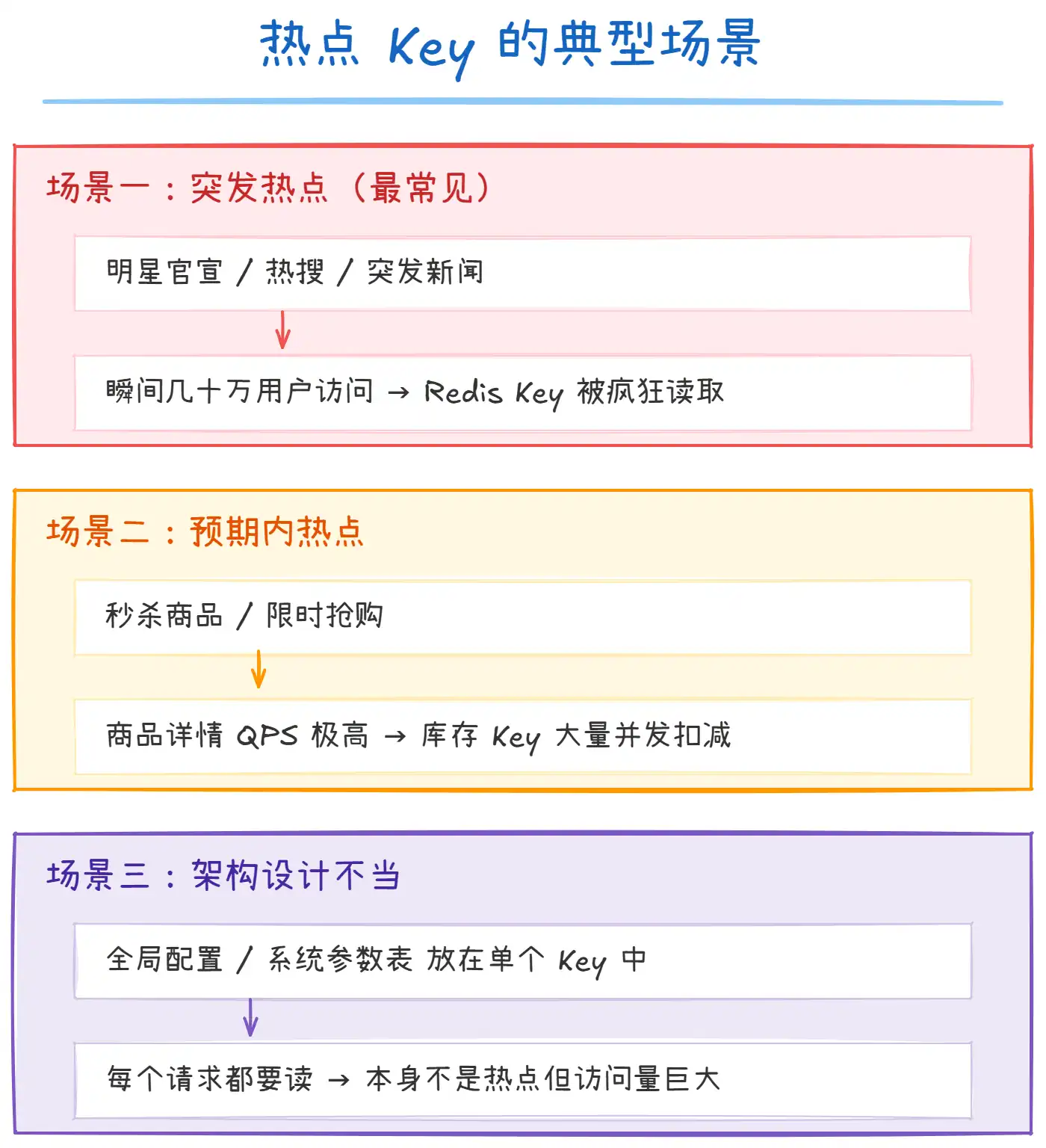
上图列出了热点 Key 的三种典型场景:
- 突发热点:明星官宣、热搜话题、突发新闻等,短时间内大量用户访问同一页面,对应的 Redis Key 被疯狂读取。这类热点 不可预测,最危险。
- 预期内热点:秒杀商品、限时抢购等,在活动期间某些 Key 的 QPS 会飙到极高。这类热点 可以提前准备。
- 架构设计不当:把全局配置、系统参数放在单个 Key 中,每个请求都要读取,造成人为的热点。
三、如何发现热点 Key?
方法一:redis-cli --hotkeys(Redis 4.0+)
# 需要先开启 maxmemory-policy 为 LFU 系列策略
redis-cli --hotkeys
# 输出示例:
# [Hot Key] user:profile:10086 (access count: 583210)
# [Hot Key] seckill:goods:1001 (access count: 421305)
# [Hot Key] hot:news:202 (access count: 389102)
关键点:
- 基于 Redis 的 LFU 计数器统计,能直接列出访问频率最高的 Key。
- 前提条件:必须将淘汰策略设为
volatile-lfu或allkeys-lfu,否则无法使用。
方法二:MONITOR 命令(临时排查)
# 实时监控 Redis 执行的所有命令(危险!仅用于临时排查)
redis-cli MONITOR | grep "GET\|HGET" | awk '{print $NF}' | sort | uniq -c | sort -nr | head -20
# 输出示例:
# 583210 GET user:profile:10086
# 421305 GET seckill:goods:1001
# 389102 GET hot:news:202
关键点:
MONITOR会输出 Redis 执行的每一条命令,可以用管道统计哪些 Key 被访问最多。- 严重警告:
MONITOR本身会消耗 Redis 性能(高 QPS 下可能导致 10%~30% 性能下降),只能短时间使用,不能长期开启。
方法三:业务层面监控
/**
* 简单的热点 Key 检测器
* 统计每个 Key 的访问频率,超过阈值告警
*/
public class HotKeyDetector {
// Key 访问计数器(可用 Guava Cache 设置滑动窗口)
private final Cache<String, AtomicLong> counterCache = CacheBuilder.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS) // 1 秒滑动窗口
.build();
// 热点阈值:1 秒内访问超过 1000 次
private static final long HOT_THRESHOLD = 1000;
public void recordAccess(String key) {
AtomicLong counter = counterCache.get(key, () -> new AtomicLong(0));
long count = counter.incrementAndGet();
if (count == HOT_THRESHOLD) {
// 触发告警
alertService.warn("检测到热点 Key:" + key + ",QPS:" + count);
}
}
}
关键点:
- 在应用层统计每个 Key 的访问频率,超过阈值触发告警。
- 这种方式对 Redis 零侵入,不影响 Redis 性能,适合长期运行。
- 可以结合 Sentinel、Prometheus 等监控系统做可视化展示。
四、热点 Key 的解决方案
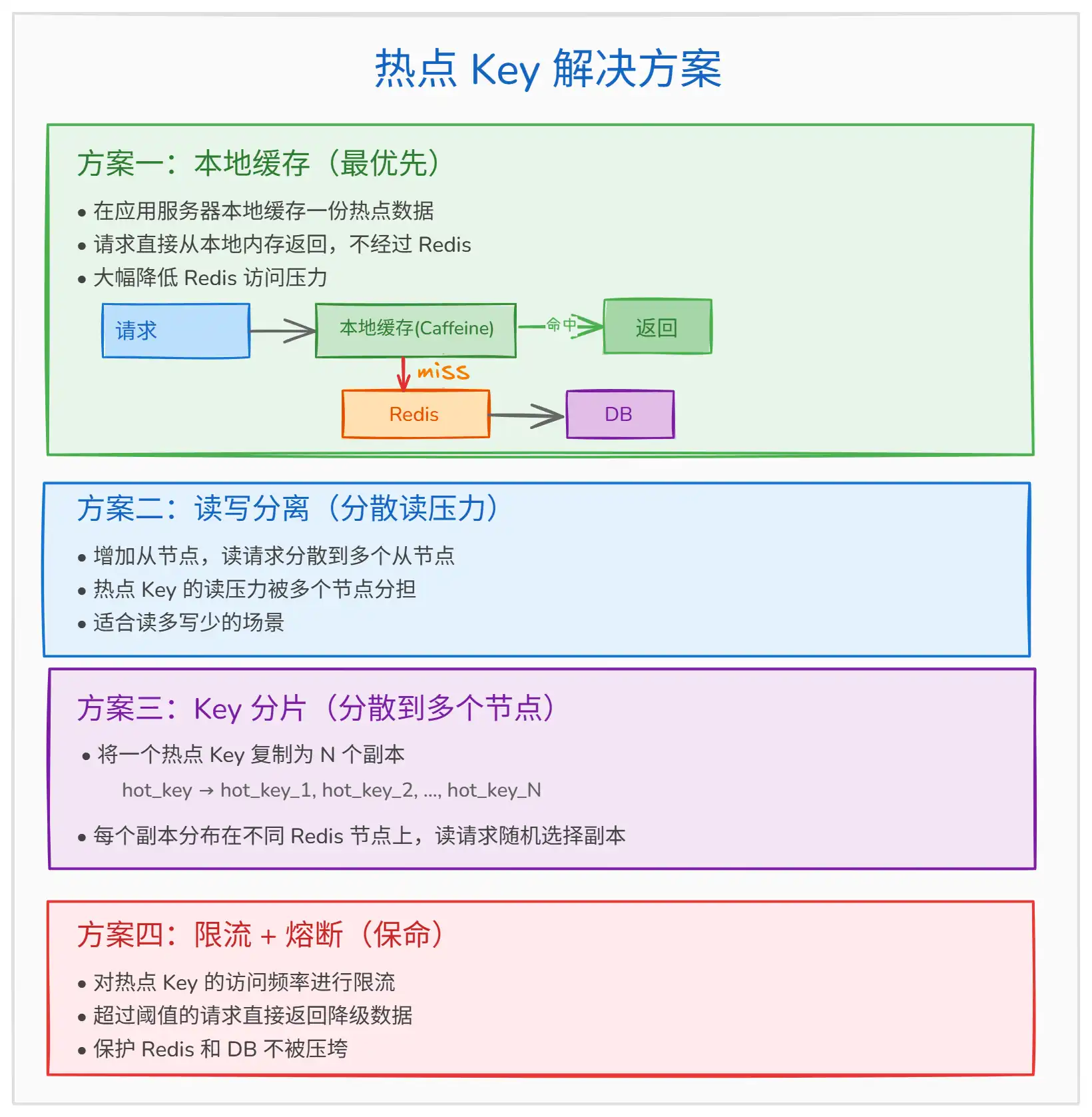
上图展示了热点 Key 的四种解决方案:
- 本地缓存(最优先):在应用服务器本地缓存一份热点数据,请求直接从本地内存返回,不经过 Redis,大幅降低 Redis 访问压力。
- 读写分离:增加从节点,读请求分散到多个从节点,热点 Key 的读压力被多个节点分担,适合读多写少的场景。
- Key 分片:将一个热点 Key 复制为 N 个副本,分布在不同节点上,读请求随机选择一个副本读取。
- 限流 + 熔断:对热点 Key 的访问频率进行限流,超过阈值的请求直接返回降级数据,保护 Redis 和 DB 不被压垮。
五、方案详解与代码示例
方案一:本地缓存(Caffeine)
/**
* 使用 Caffeine 本地缓存解决热点 Key
* 适合:数据量小、更新不频繁、读多写少
*/
public class LocalCacheSolution {
// Caffeine 本地缓存
private final Cache<String, String> localCache = Caffeine.newBuilder()
.maximumSize(10000) // 最多缓存 1 万个 Key
.expireAfterWrite(5, TimeUnit.SECONDS) // 5 秒过期(容忍短暂不一致)
.recordStats() // 记录统计信息
.build();
public String getHotData(String key) {
// 1. 先查本地缓存
String value = localCache.getIfPresent(key);
if (value != null) {
return value; // 本地缓存命中,直接返回,不访问 Redis
}
// 2. 本地缓存 miss,查 Redis
value = redis.get(key);
if (value != null) {
localCache.put(key, value); // 回写本地缓存
return value;
}
// 3. Redis 也 miss,查 DB
value = db.query(key);
if (value != null) {
redis.set(key, value, 30, TimeUnit.MINUTES);
localCache.put(key, value);
}
return value;
}
}
关键点:
- 使用 Caffeine 作为本地缓存(高性能、支持过期淘汰),5 秒过期容忍短暂的数据不一致。
- 热点 Key 的请求大部分会命中本地缓存,Redis 的 QPS 可能从 30 万降到几千。
- 注意:本地缓存适用于 数据量小、更新不频繁 的场景。如果数据更新频繁,要注意本地缓存和 Redis 的一致性问题。
方案二:Key 分片
/**
* 热点 Key 分片方案
* 将一个热点 Key 复制为 N 个副本,分散到不同节点
*/
public class HotKeyShardingSolution {
private static final int SHARD_COUNT = 16; // 分片数量
// 写入时:同时写入所有分片
public void setHotKey(String key, String value) {
for (int i = 0; i < SHARD_COUNT; i++) {
String shardKey = key + ":shard:" + i;
redis.set(shardKey, value, 30, TimeUnit.MINUTES);
}
}
// 读取时:随机选择一个分片读取
public String getHotKey(String key) {
int shard = ThreadLocalRandom.current().nextInt(SHARD_COUNT);
String shardKey = key + ":shard:" + shard;
return redis.get(shardKey);
}
}
关键点:
- 写入时同时写 N 个分片,读取时随机选一个分片,把 QPS 均摊到 N 个节点上。
- 比如 30 万 QPS 的热点 Key,分 16 片后每个节点只承受约 1.9 万 QPS。
- 代价:写入开销增大(写 N 次)、内存占用增大(存 N 份)、数据一致性维护成本高。
- 适合 读远多于写 的场景(如秒杀商品详情)。
方案三:读写分离 + 热点探测(京东零售方案)
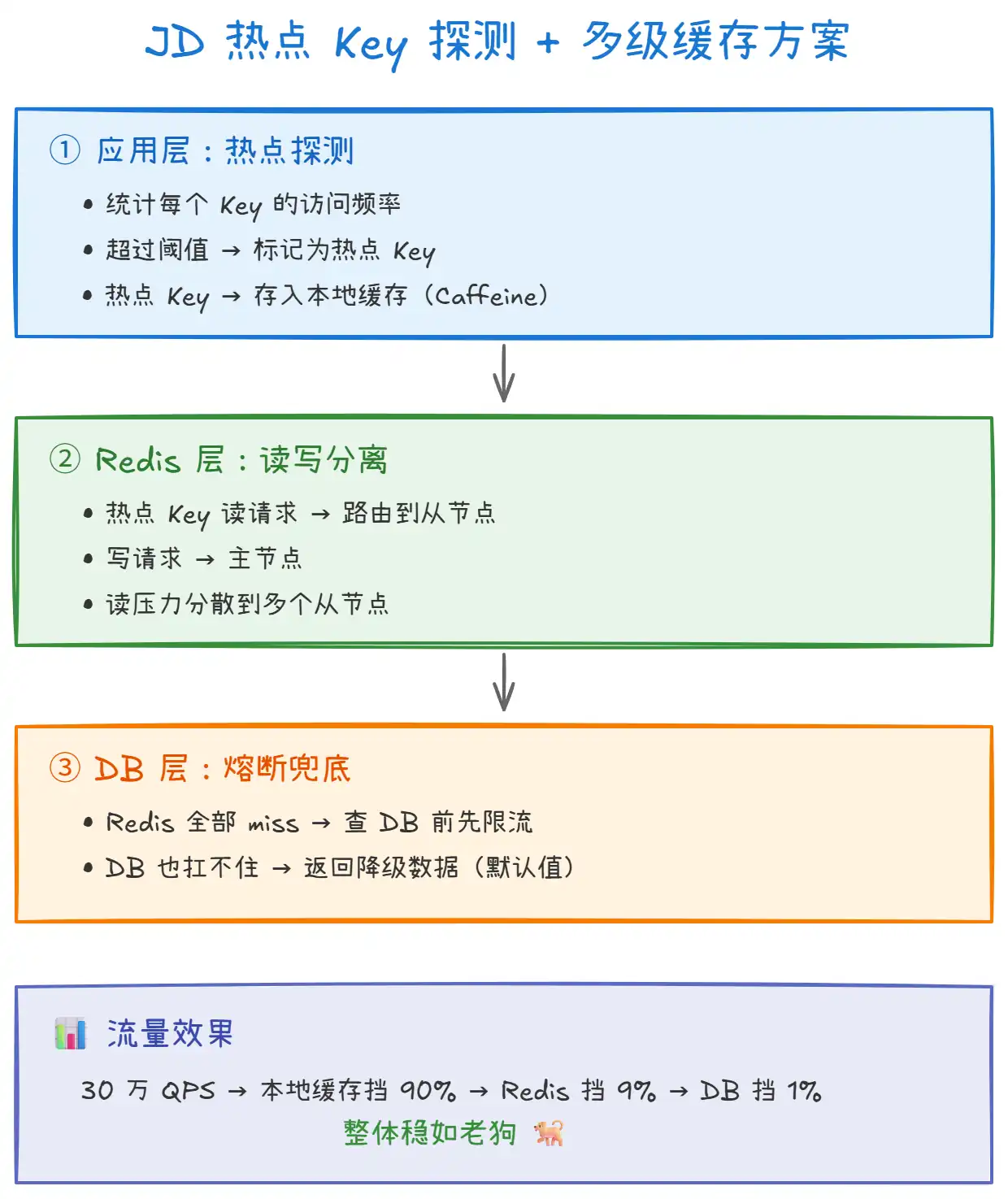
上图展示了京东零售的热点 Key 多级缓存方案:
- 第一级:本地缓存(挡住 90% 请求):应用层统计 Key 访问频率,超过阈值自动标记为热点 Key,存入 Caffeine 本地缓存。
- 第二级:Redis 读写分离(挡住 9% 请求):热点 Key 的读请求路由到从节点,分散读压力。
- 第三级:DB 熔断兜底(1% 请求):Redis 全部 miss 时,查 DB 前先限流,DB 扛不住则返回降级数据。
- 三级缓存协同工作,30 万 QPS 的热点 Key 也能稳定应对。
六、方案对比总结
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 本地缓存 | 性能最好,直接挡在应用层 | 多实例数据不一致,内存有限 | 数据量小、更新不频繁 |
| Key 分片 | 读写都能分散,通用性强 | 写入开销大,维护成本高 | 读远多于写 |
| 读写分离 | 对应用透明,运维层面解决 | 主从延迟,从节点成本 | 读多写少,有从节点资源 |
| 限流降级 | 兜底保命,实现简单 | 部分用户看到降级数据 | 兜底方案,配合其他方案使用 |
生产推荐组合:本地缓存(首选)+ 读写分离(分散读压力)+ 限流降级(兜底保命)。
面试高频追问
-
追问一:热点 Key 和大 Key 有什么区别?
热点 Key 是 访问频率过高,问题在于单节点 CPU / 网络被打满;大 Key 是 数据体积过大,问题在于操作耗时长、阻塞主线程。两者可能同时存在(比如一个又大又被频繁访问的 Key),但解决思路完全不同:热点 Key 要分散访问,大 Key 要拆分数据。
-
追问二:本地缓存和 Redis 缓存的一致性怎么保证?
本地缓存的过期时间设短一些(如 3~5 秒),容忍短暂的不一致。如果对一致性要求高,可以用 Redis Pub/Sub 或 MQ 广播 通知所有应用实例失效本地缓存。也可以接受最终一致性,大多数热点数据(商品详情、文章内容)短暂不一致是可接受的。
-
追问三:如何提前预知热点 Key?
对于可预期的热点(如秒杀、大促),可以提前将热点数据加载到本地缓存中,活动开始前就预热好。对于突发热点,需要依赖热点探测机制实时发现并自动缓存。结合监控告警,当某个 Key 的 QPS 超过阈值时自动触发本地缓存。
常见面试变体
- 变体一:"Redis 中某个 Key 访问量特别大怎么办?"
- 变体二:"秒杀场景下 Redis 的热点 Key 如何处理?"
- 变体三:"如何发现 Redis 中的热点 Key?"
- 变体四:"本地缓存和 Redis 缓存怎么配合使用?"
记忆口诀
热点 Key:访问太多,单节点扛不住 —— "流量太集中"。
解决方案优先级:本地缓存(挡最多)> Key 分片(分散节点)> 读写分离(分散读)> 限流降级(兜底)。
与大 Key 区别:热点是 "来的人太多",大 Key 是 "东西太大搬不动"。
生产最佳实践:热点探测 + 本地缓存 + 读写分离 + 限流降级,四板斧组合使用。
总结
Redis 热点 Key 是指被大量客户端频繁访问的 Key,会导致单个节点 CPU 和网络被打满。发现热点 Key 可以用 --hotkeys、MONITOR、业务层监控等手段。解决方案的核心是 分散访问压力:优先使用本地缓存(Caffeine)挡住大部分请求,配合 Key 分片或读写分离分散 Redis 的读压力,最后用限流降级兜底保命。