怎么解决 Redis 缓存和数据库的一致性问题?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道 "先删缓存" 还是 "后删缓存",更是想知道你是否能分析出每种方案在并发场景下的数据不一致问题,以及背后的时序原因。
-
方案设计能力:考察你是否了解 "延迟双删"、"订阅 Binlog 异步更新"、"设置 TTL 兜底" 等生产级别的解决方案,而不是只停留在理论层面。
-
工程思维:能否认识到 "缓存和数据库的强一致性在分布式系统中几乎不可能",接受 "最终一致性" 并设计对应的补偿机制。
核心答案
缓存和数据库的一致性有 4 种 常见方案:
| 方案 | 操作顺序 | 一致性 | 推荐程度 |
|---|---|---|---|
| 先更新数据库,再更新缓存 | DB → Cache | 并发更新会覆盖,数据错乱 | 不推荐 |
| 先删缓存,再更新数据库 | Del → DB → Read → Cache | 并发读会写回旧值 | 需配合延迟双删 |
| 先更新数据库,再删缓存(推荐) | DB → Del | 极端情况不一致,概率极低 | Cache Aside 模式 |
| 订阅 Binlog 异步更新(最可靠) | DB → Binlog → Cache | 最终一致性 | 生产首选 |
一句话结论:推荐 Cache Aside 模式(先更新 DB,再删缓存),搭配 TTL 兜底。如果对一致性要求更高,用 Canal 订阅 MySQL Binlog 异步更新缓存。不要追求强一致性,接受 最终一致性。
深度解析
一、方案一:先更新数据库,再更新缓存(不推荐)
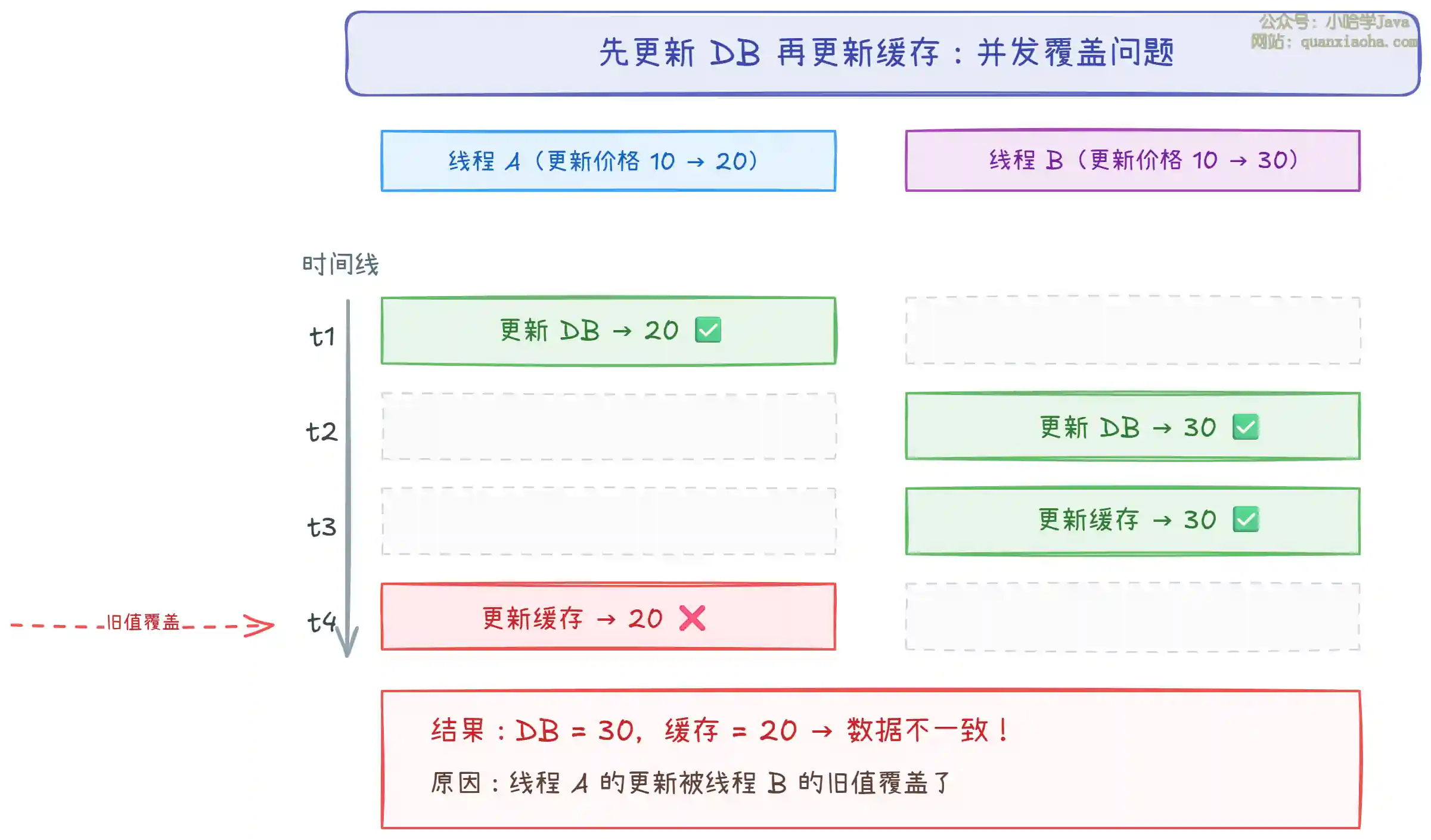
上图展示了 "先更新 DB 再更新缓存" 在并发场景下的问题:
- 线程 A 和线程 B 同时更新同一条数据。线程 A 先更新了数据库(20),但还没来得及更新缓存时,线程 B 已经完成了数据库和缓存的更新(30)。
- 线程 A 随后更新缓存为 20,把线程 B 正确的值 30 给覆盖了,出现了数据库和缓存数据不一致的问题。
- 根本问题:更新缓存的顺序和更新数据库的顺序可能不一致,后面的更新可能把前面的覆盖。
另外,如果缓存值是经过复杂计算得出的(比如多表联查、聚合统计),每次更新数据库都要重新计算并写入缓存,性能开销大,而且很多更新操作可能根本没有读请求,白算了一遍。
二、方案二:先删缓存,再更新数据库(有缺陷)
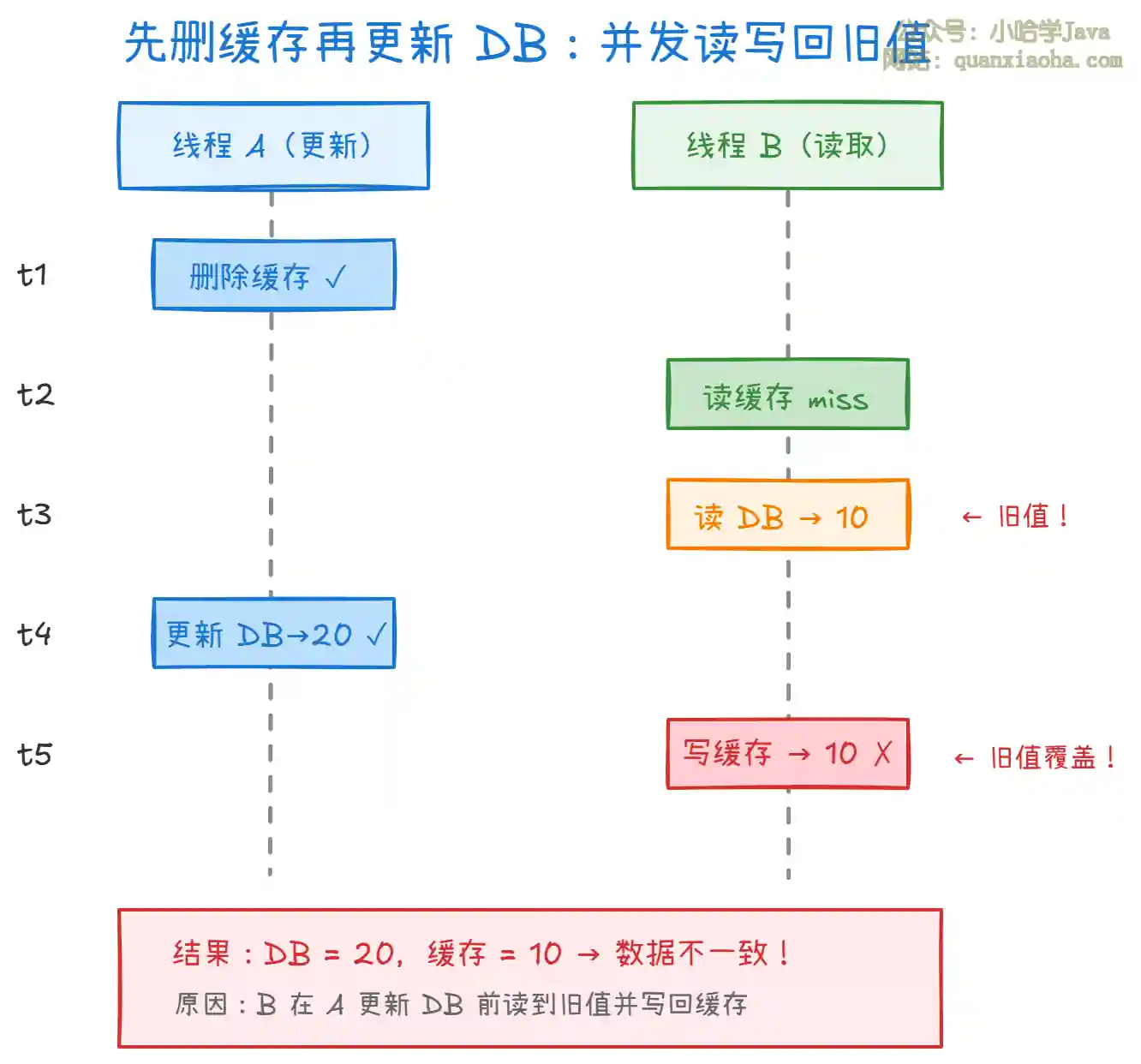
上图展示了 "先删缓存再更新 DB" 的问题:
- 线程 A 删除缓存后,还没来得及更新数据库。这时线程 B 来读数据,发现缓存 miss,去数据库读到了旧值(10)。
- 线程 B 把旧值 10 写回缓存。之后线程 A 才把数据库更新为 20。
- 结果数据库是新值 20,缓存里还是旧值 10,后续所有读请求都会命中缓存的旧值,直到缓存过期。
补救方案:延迟双删
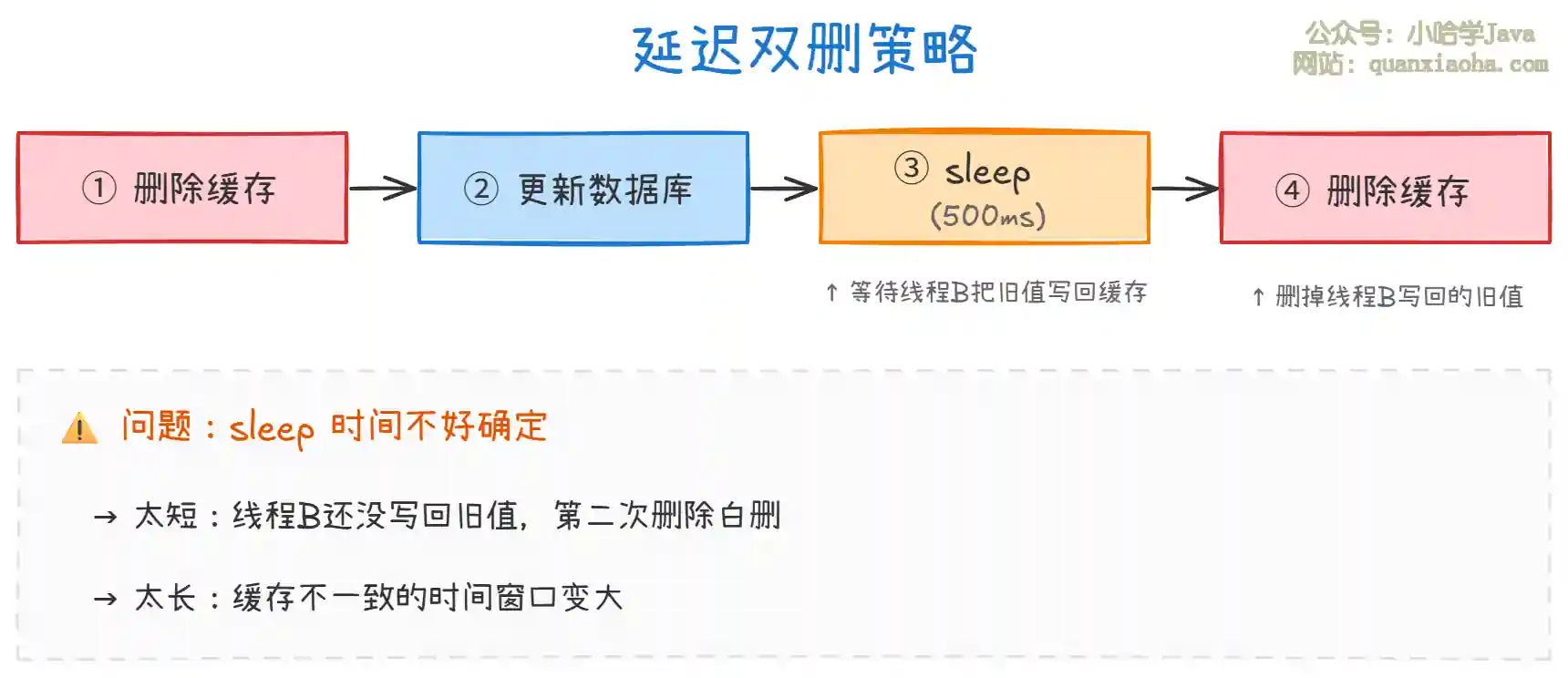
上图展示了延迟双删的核心思路:
- 在更新数据库后,等一段时间(让并发读请求把旧值写回缓存),再删一次缓存。
- 问题:sleep 时间很难确定,而且同步 sleep 会占用线程资源。实际中一般用异步消息(MQ 延迟消息)来实现第二次删除。
三、方案三:先更新数据库,再删缓存(Cache Aside,推荐)
这是业界最广泛使用的方案,也叫 Cache Aside Pattern(旁路缓存模式)。
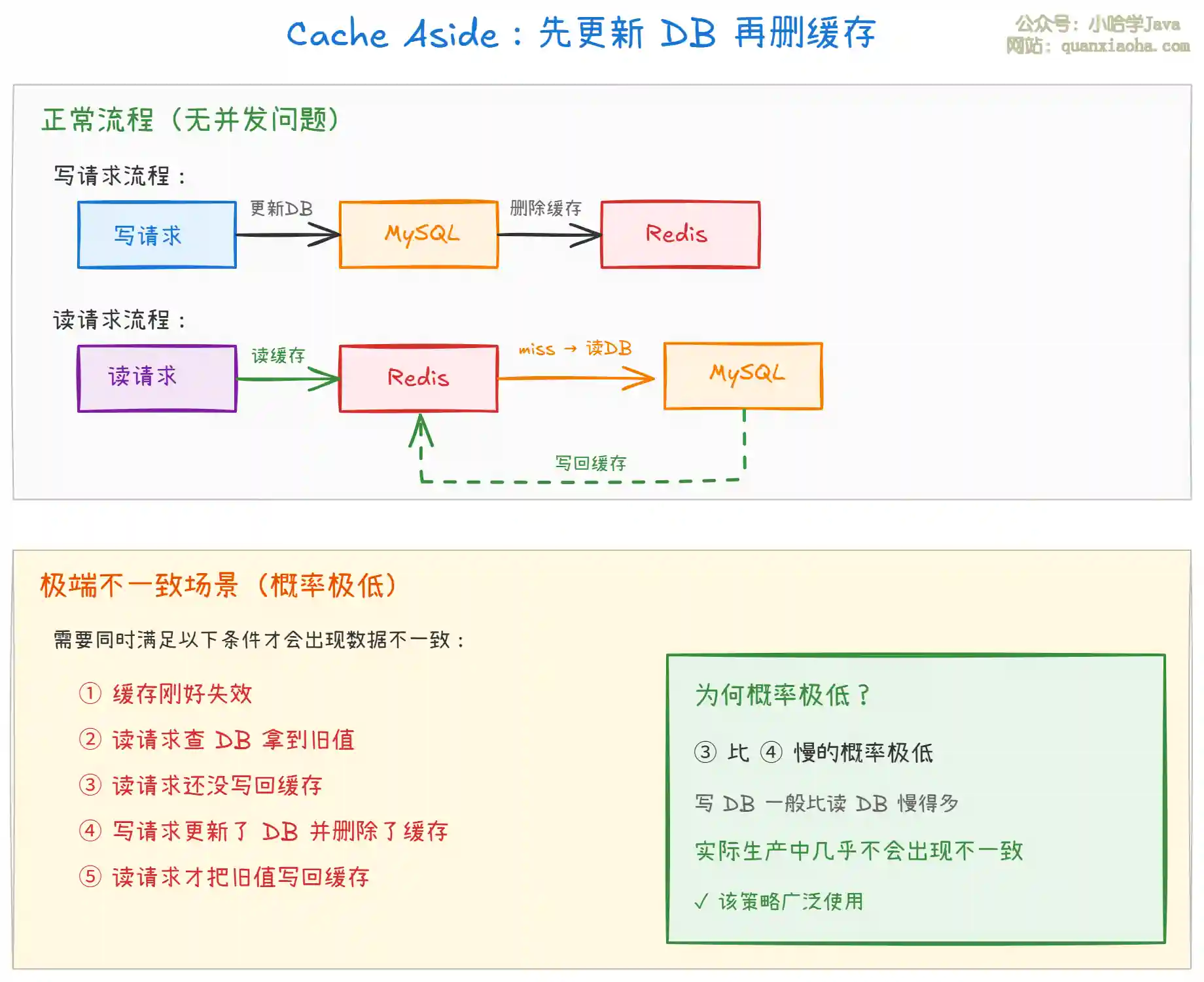
上图展示了 Cache Aside 模式的完整逻辑:
- 写操作:先更新数据库,再删除缓存。注意是 删除 而不是更新,因为删除更轻量,且能避免并发更新导致的覆盖问题。
- 读操作:先读缓存,命中直接返回;未命中则读数据库,写回缓存。
- 极端不一致的概率极低:只有 "读请求写缓存" 的速度比 "写请求更新 DB + 删除缓存" 还慢时才会出问题,而写 DB 一般比读 DB 慢得多(涉及锁、磁盘 IO),所以实际中几乎不会发生。
为什么 "删缓存" 比 "更新缓存" 好?
| 维度 | 更新缓存 | 删除缓存 |
|---|---|---|
| 并发安全 | ❌ 并发更新可能互相覆盖 | ✅ 删除是幂等的,多次删除无副作用 |
| 性能 | ❌ 每次写都要算新值并更新 | ✅ 删除操作轻量 |
| 懒加载 | ❌ 无论有没有读都更新, 浪费内存 | ✅ 下次读时才从 DB 加载 |
四、方案四:订阅 Binlog 异步更新(生产最可靠)
如果对一致性要求更高,可以借助 MySQL 的 Binlog 来异步更新缓存。
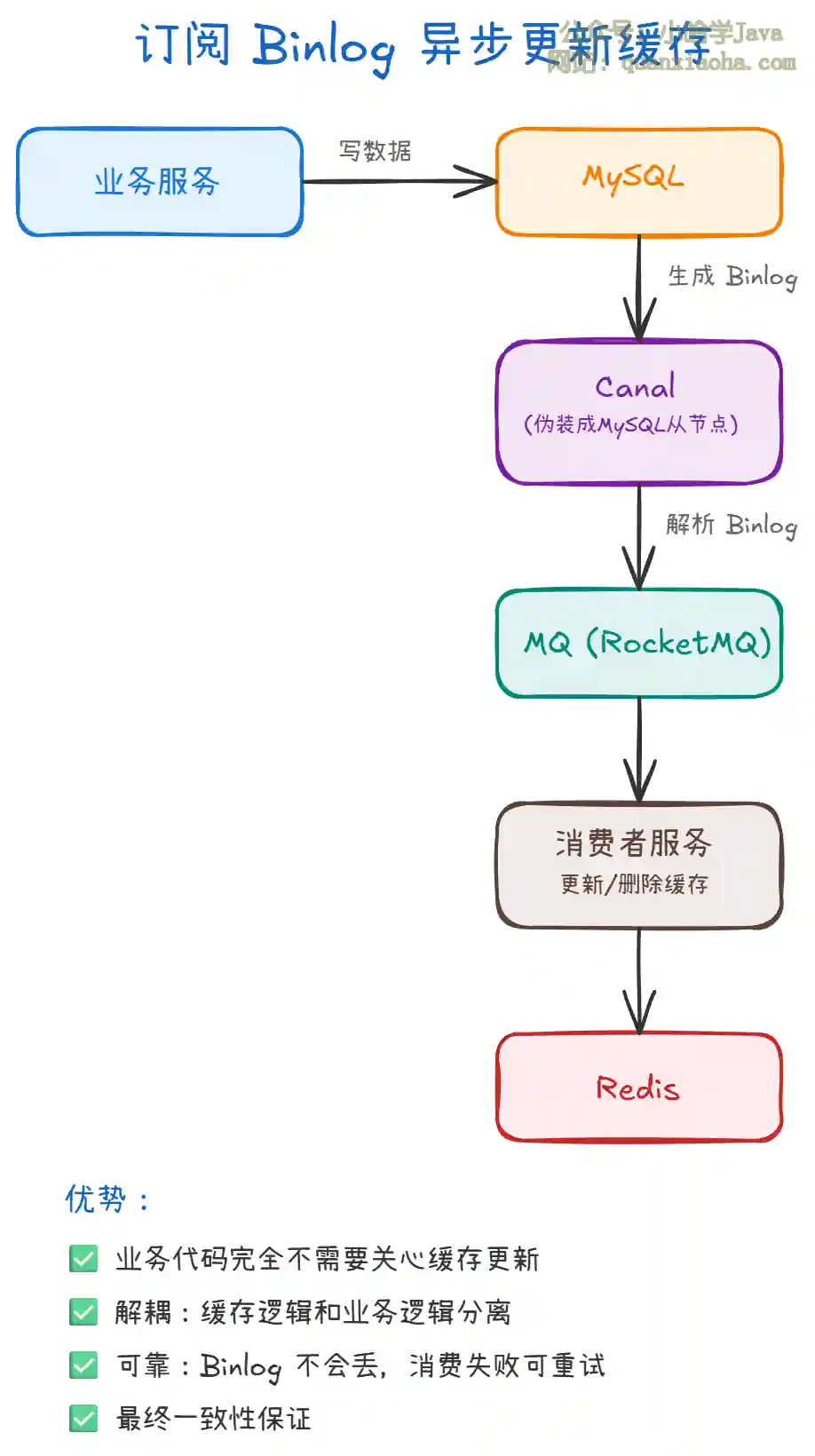
上图展示了 Binlog 方案的完整架构:
- Canal 是阿里开源的 MySQL Binlog 增量订阅组件,它伪装成 MySQL 的从节点,实时接收 Binlog 事件。
- 业务服务只管写数据库,完全不需要关心缓存。Canal 监听到数据变更后,通过 MQ(Kafka / RocketMQ)投递消息,消费者服务负责更新或删除缓存。
- 优势:业务代码零侵入、解耦彻底、Binlog 可靠不丢失、消费失败可重试,能保证最终一致性。
- 代价:引入了 Canal 和 MQ 组件,运维复杂度增加。
五、生产环境推荐方案
日常方案(Cache Aside + TTL 兜底):
- ① 先更新数据库
- ② 再删除缓存
- ③ 缓存设置 TTL 兜底(最终一致性保险)
- ④ 删除失败 → 重试(MQ 或本地重试表)
覆盖 99% 场景,简单可靠。
高可靠方案(+ Canal Binlog):
- ① 业务只写 DB
- ② Canal 订阅 Binlog
- ③ MQ 投递 + 消费者更新缓存
- ④ 消费失败自动重试
- ⑤ 仍然设置 TTL 兜底
适合对一致性要求高的核心业务。
关键原则:
- ❌ 不要追求强一致性 → 不现实
- ✅ 接受最终一致性 + TTL 兜底
- ✅ 删缓存比更新缓存更安全
- ✅ 删除失败要有重试机制
面试高频追问
-
追问一:为什么不直接更新缓存,而要删除缓存?
更新缓存在并发场景下存在 覆盖问题:两个线程同时更新,后更新的值可能被先更新的旧值覆盖。而删除是幂等操作,多次删除没有副作用,下次读时自然从 DB 加载最新值。另外,更新缓存需要知道新值是什么,可能涉及复杂计算;删除则不需要,更轻量。
-
追问二:Cache Aside 模式下,删除缓存失败了怎么办?
最简单的方案是 重试:可以用 MQ 异步重试,也可以用本地消息表 + 定时任务补偿。更高级的方案是引入 Canal 订阅 Binlog 作为兜底,即使业务删缓存失败,Canal 也会异步更新缓存。再加上缓存 TTL 兜底,即使所有重试都失败了,缓存过期后也会从 DB 加载最新值。
-
追问三:Redis 和数据库能实现强一致性吗?
不能。因为 Redis 和 MySQL 是两个独立的存储系统,没有任何分布式事务机制能保证两步操作的原子性。即使在同一个事务里操作,网络延迟、部分失败等因素都会导致不一致。所以业界共识是接受 最终一致性,通过 TTL 兜底 + 重试机制 + Binlog 补偿来逼近一致性。
常见面试变体
- 变体一:"先删缓存还是后删缓存?为什么?"
- 变体二:"缓存和数据库双写不一致怎么解决?"
- 变体三:"什么是 Cache Aside 模式?"
- 变体四:"Canal 订阅 Binlog 更新缓存了解吗?"
记忆口诀
四种方案排序:更新缓存(不推荐) < 先删缓存再更新 DB(延迟双删) < 先更新 DB 再删缓存(Cache Aside,推荐) < Canal Binlog(最可靠)。
核心原则:更新 DB 是源头,缓存只是视图;删缓存比更新缓存更安全;TTL 是最后一道防线。
Cache Aside:写 → 更新 DB + 删缓存;读 → 读缓存 + miss 读 DB + 回写缓存。
总结
保证 Redis 和数据库一致性的 推荐方案 是 Cache Aside 模式:先更新数据库,再删除缓存,配合 TTL 兜底和删除失败重试机制。如果对一致性要求更高,引入 Canal 订阅 MySQL Binlog 异步更新缓存,实现业务代码零侵入的最终一致性。核心原则:不要追求强一致性,接受最终一致性,用 "删缓存 + TTL + 重试" 三重保险来逼近一致。