MySQL 用了索引还是很慢,可能是什么原因?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
索引原理理解深度:面试官不仅仅是想知道你背过 "索引失效的几种情况",更是想考察你是否真正理解 B+ 树索引的工作原理、索引的选择性、覆盖索引等核心概念,以及为什么这些因素会影响查询性能。
-
生产环境排查能力:考察你是否具备实际的慢查询排查经验,能否通过
EXPLAIN分析执行计划,定位到具体的性能瓶颈(是索引失效、回表次数过多、还是其他原因)。 -
系统性优化思维:面试官想了解你是否具备从多个维度(SQL 写法、索引设计、表结构、数据库配置、硬件资源)来分析和解决性能问题的能力,而不仅仅是知道 "加索引" 这一种手段。
核心答案
即使查询使用了索引,仍然可能很慢,主要原因可以归纳为 6 大类:
| 类别 | 具体原因 | 影响 |
|---|---|---|
| 索引设计问题 | 索引选择性差、索引列顺序不当、索引冗余 | 扫描行数过多 |
| SQL 写法问题 | SELECT *、LIKE '%xxx'、函数操作、类型转换 |
索引失效或回表过多 |
| 数据分布问题 | 数据量过大、数据倾斜严重、热点数据集中 | 即使走索引也慢 |
| 表结构问题 | 字段过大、行过长、未分区 | I/O 开销大 |
| 数据库配置问题 | 缓冲池过小、连接数不足、参数配置不当 | 整体性能下降 |
| 硬件资源瓶颈 | 磁盘 I/O、内存不足、CPU 瓶颈 | 物理层面慢 |
一句话总结:索引只是加速查询的必要条件而非充分条件,需要结合索引设计、SQL 优化、表结构设计、数据库配置和硬件资源进行系统性优化。
深度解析
一、索引设计问题
1. 索引选择性差
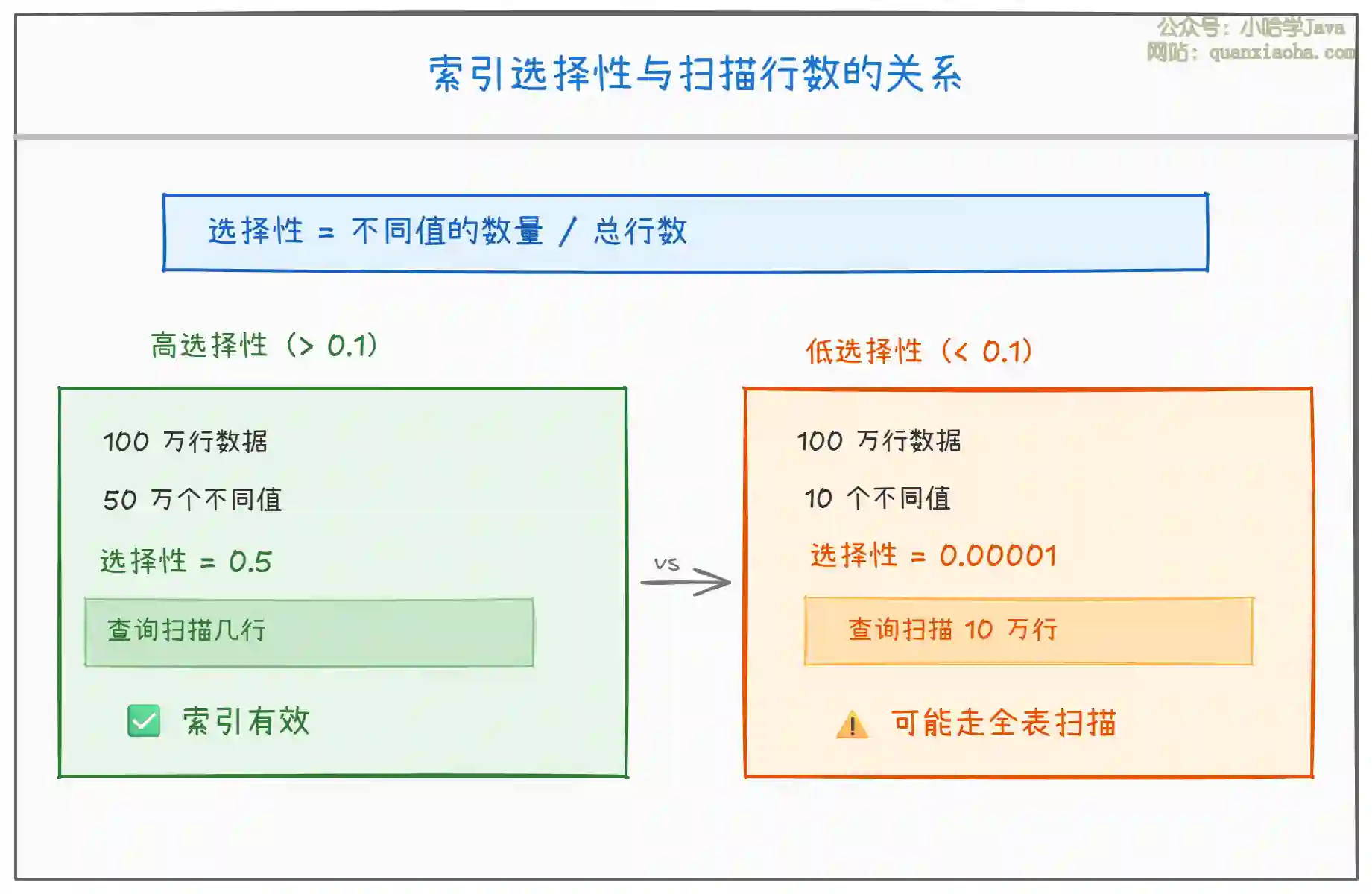
上图展示了索引选择性对查询性能的影响。选择性越高,索引的效果越好;选择性越低,索引的效果越差。
-
高选择性:例如用户表的
user_id字段,100 万用户有 100 万个不同的user_id,选择性为 1.0,查询时可以快速定位到唯一行。 -
低选择性:例如性别字段
gender,只有 "男" 和 "女" 两个值,100 万行数据的选择性仅为 0.000002,查询 "男" 性用户时需要扫描约 50 万行,数据库优化器可能直接选择全表扫描。
判断标准:一般建议索引选择性大于 0.1,可以通过以下 SQL 计算:
-- 计算字段的选择性
SELECT
COUNT(DISTINCT column_name) / COUNT(*) AS selectivity
FROM table_name;
-- 示例:gender 字段的选择性
SELECT
COUNT(DISTINCT gender) / COUNT(*) AS selectivity
FROM users;
-- 结果:0.000002(非常低,不适合单独建索引)
2. 索引列顺序不当(最左前缀原则)
-- 创建联合索引
CREATE INDEX idx_name_age_gender ON users(name, age, gender);
-- ✅ 走索引:符合最左前缀
SELECT * FROM users WHERE name = '张三';
SELECT * FROM users WHERE name = '张三' AND age = 25;
SELECT * FROM users WHERE name = '张三' AND age = 25 AND gender = '男';
-- ❌ 不走索引:违反最左前缀
SELECT * FROM users WHERE age = 25; -- 缺少 name
SELECT * FROM users WHERE gender = '男'; -- 缺少 name 和 age
SELECT * FROM users WHERE age = 25 AND gender = '男'; -- 缺少 name
-- ⚠️ 部分走索引:只有 name 走索引,后面的列无法利用索引排序
SELECT * FROM users WHERE name = '张三' AND gender = '男'; -- age 跳过了
核心原则:联合索引要遵循 "最左前缀原则",索引列的顺序非常重要。将区分度高、经常用于查询条件的列放在左边。
3. 索引冗余
-- ❌ 冗余索引示例
CREATE INDEX idx_name ON users(name); -- 单列索引
CREATE INDEX idx_name_age ON users(name, age); -- 联合索引
-- idx_name 是冗余的,因为 idx_name_age 可以覆盖 name 单列查询
-- ✅ 优化后:删除冗余索引
DROP INDEX idx_name ON users;
-- 只保留联合索引 idx_name_age
二、SQL 写法问题
1. SELECT * 导致大量回表
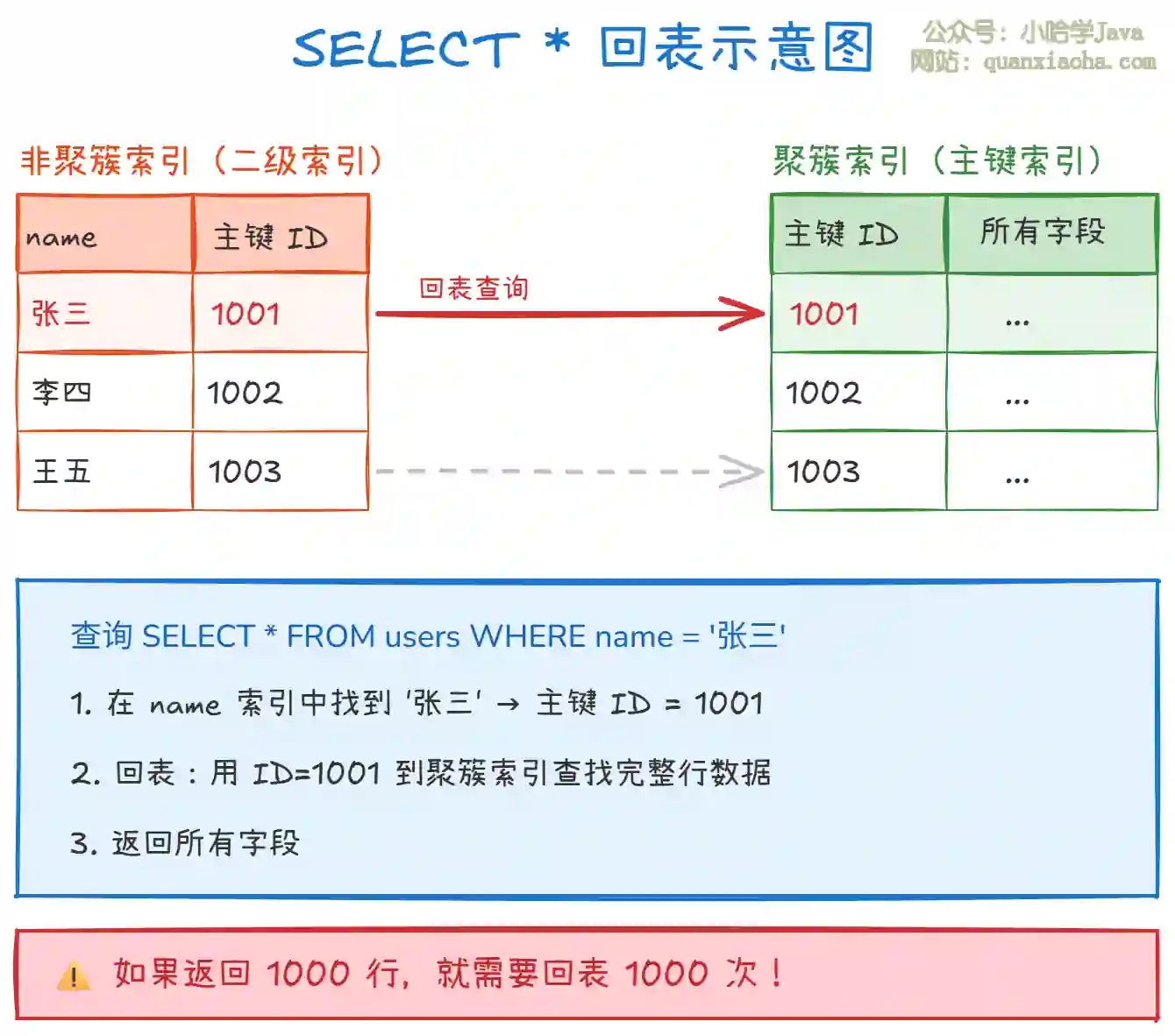
上图展示了 SELECT * 查询的回表过程。如果查询只需要部分字段,但使用了 SELECT *,就会导致不必要的回表操作,严重影响性能。
-
回表过程:先在二级索引(如
name索引)中找到满足条件的主键 ID,然后根据主键 ID 到聚簇索引中查找完整的行数据。 -
性能影响:如果查询返回 1000 行数据,就需要进行 1000 次回表操作,每次回表都是一次随机 I/O,性能开销巨大。
优化方案:使用覆盖索引,只查询索引列,避免回表。
-- ❌ 慢查询:需要回表
SELECT * FROM users WHERE name = '张三';
-- ✅ 优化:使用覆盖索引,无需回表
-- 假设有索引 idx_name_age(name, age)
SELECT name, age FROM users WHERE name = '张三';
2. LIKE 查询导致索引失效
-- ✅ 走索引:前缀匹配
SELECT * FROM users WHERE name LIKE '张%';
-- ❌ 不走索引:后缀匹配或包含匹配
SELECT * FROM users WHERE name LIKE '%张'; -- 后缀匹配
SELECT * FROM users WHERE name LIKE '%张%'; -- 包含匹配
-- ✅ 优化方案 1:使用覆盖索引
-- 即使 LIKE '%张%' 不走索引,如果只查询索引列,可能走索引扫描
SELECT name FROM users WHERE name LIKE '%张%';
-- ✅ 优化方案 2:使用全文索引
ALTER TABLE users ADD FULLTEXT INDEX ft_name(name);
SELECT * FROM users WHERE MATCH(name) AGAINST('张');
-- ✅ 优化方案 3:使用搜索引擎(如 Elasticsearch)
3. 对索引列使用函数或计算
-- ❌ 不走索引:对索引列使用函数
SELECT * FROM users WHERE DATE(create_time) = '2024-01-01';
SELECT * FROM users WHERE YEAR(create_time) = 2024;
SELECT * FROM users WHERE SUBSTRING(name, 1, 1) = '张';
-- ✅ 走索引:使用范围查询或等值查询
SELECT * FROM users WHERE create_time >= '2024-01-01'
AND create_time < '2024-01-02';
-- ❌ 不走索引:索引列参与计算
SELECT * FROM users WHERE age + 1 = 26;
-- ✅ 走索引:调整计算方式
SELECT * FROM users WHERE age = 25;
4. 隐式类型转换
-- 假设 user_id 是 VARCHAR 类型
CREATE INDEX idx_user_id ON users(user_id);
-- ❌ 不走索引:字符串与数字比较,发生隐式类型转换
SELECT * FROM users WHERE user_id = 123;
-- 等价于:SELECT * FROM users WHERE CAST(user_id AS SIGNED) = 123;
-- ✅ 走索引:类型一致
SELECT * FROM users WHERE user_id = '123';
核心原则:索引列的类型必须与查询条件的类型完全一致,否则会发生隐式类型转换,导致索引失效。
三、数据分布问题
1. 数据量过大
-- 查询表的总行数和大小
SELECT
table_name,
table_rows,
ROUND(data_length / 1024 / 1024, 2) AS data_size_mb,
ROUND(index_length / 1024 / 1024, 2) AS index_size_mb
FROM information_schema.tables
WHERE table_schema = 'your_database';
优化方案:
- 分区表:按时间或范围分区,减少单次查询扫描的数据量
- 分表分库:将大表拆分为多个小表
- 归档历史数据:将历史数据迁移到归档表
- 使用覆盖索引:减少回表次数
2. 数据倾斜严重
-- 查看数据分布
SELECT gender, COUNT(*) as count
FROM users
GROUP BY gender;
-- 假设结果:
-- gender | count
-- -------|--------
-- 男 | 999000
-- 女 | 1000
-- 其他 | 0
-- 查询 "男" 性用户时,即使有索引,也可能走全表扫描
-- 因为优化器认为扫描 999000 行和全表扫描差不多
优化方案:
- 对于极端倾斜的数据,考虑不建索引或使用复合索引
- 使用
FORCE INDEX强制走索引(谨慎使用)
-- 强制使用索引
SELECT * FROM users FORCE INDEX(idx_gender) WHERE gender = '男';
四、表结构问题
1. 字段过大
-- ❌ 慢查询:大字段导致行过长
CREATE TABLE articles (
id INT PRIMARY KEY,
title VARCHAR(255),
content TEXT, -- 大字段
author VARCHAR(100),
create_time DATETIME
);
-- ✅ 优化:将大字段拆分到单独的表
CREATE TABLE articles (
id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(100),
create_time DATETIME
);
CREATE TABLE article_contents (
article_id INT PRIMARY KEY,
content LONGTEXT,
FOREIGN KEY (article_id) REFERENCES articles(id)
);
2. 未使用合适的字段类型
-- ❌ 不合理:使用 VARCHAR 存储 IP 地址
CREATE TABLE logs (
id INT PRIMARY KEY,
ip VARCHAR(15)
);
-- ✅ 优化:使用 INT UNSIGNED 存储 IP 地址
CREATE TABLE logs (
id INT PRIMARY KEY,
ip INT UNSIGNED
);
-- 插入时转换
INSERT INTO logs (ip) VALUES (INET_ATON('192.168.1.1'));
-- 查询时转换
SELECT INET_NTOA(ip) FROM logs;
五、数据库配置问题
1. 缓冲池配置不当
-- 查看当前 InnoDB 缓冲池大小
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
-- 建议设置为服务器内存的 70%-80%
-- 例如:16GB 内存的服务器,设置为 12GB
SET GLOBAL innodb_buffer_pool_size = 12884901888; -- 12GB
2. 其他重要参数
-- 查看当前配置
SHOW VARIABLES LIKE 'innodb_io_capacity'; -- 磁盘 I/O 能力
SHOW VARIABLES LIKE 'innodb_read_io_threads'; -- 读线程数
SHOW VARIABLES LIKE 'innodb_write_io_threads'; -- 写线程数
SHOW VARIABLES LIKE 'max_connections'; -- 最大连接数
-- 根据服务器配置调整
-- SSD 硬盘可以设置更高的 innodb_io_capacity
六、使用 EXPLAIN 分析执行计划
-- 查看执行计划
EXPLAIN SELECT * FROM users WHERE name = '张三';
-- 关键字段解读
-- id: 查询标识符
-- select_type: 查询类型(SIMPLE, PRIMARY, SUBQUERY 等)
-- table: 访问的表
-- type: 访问类型(从好到差:system > const > eq_ref > ref > range > index > ALL)
-- possible_keys: 可能使用的索引
-- key: 实际使用的索引
-- key_len: 使用的索引长度
-- rows: 预估扫描的行数
-- Extra: 额外信息(Using index, Using where, Using filesort 等)
重点关注:
type字段:如果是ALL,说明是全表扫描;如果是index,说明是索引扫描rows字段:预估扫描的行数,越大越慢Extra字段:Using filesort(文件排序)、Using temporary(临时表)都是性能杀手
七、完整排查流程
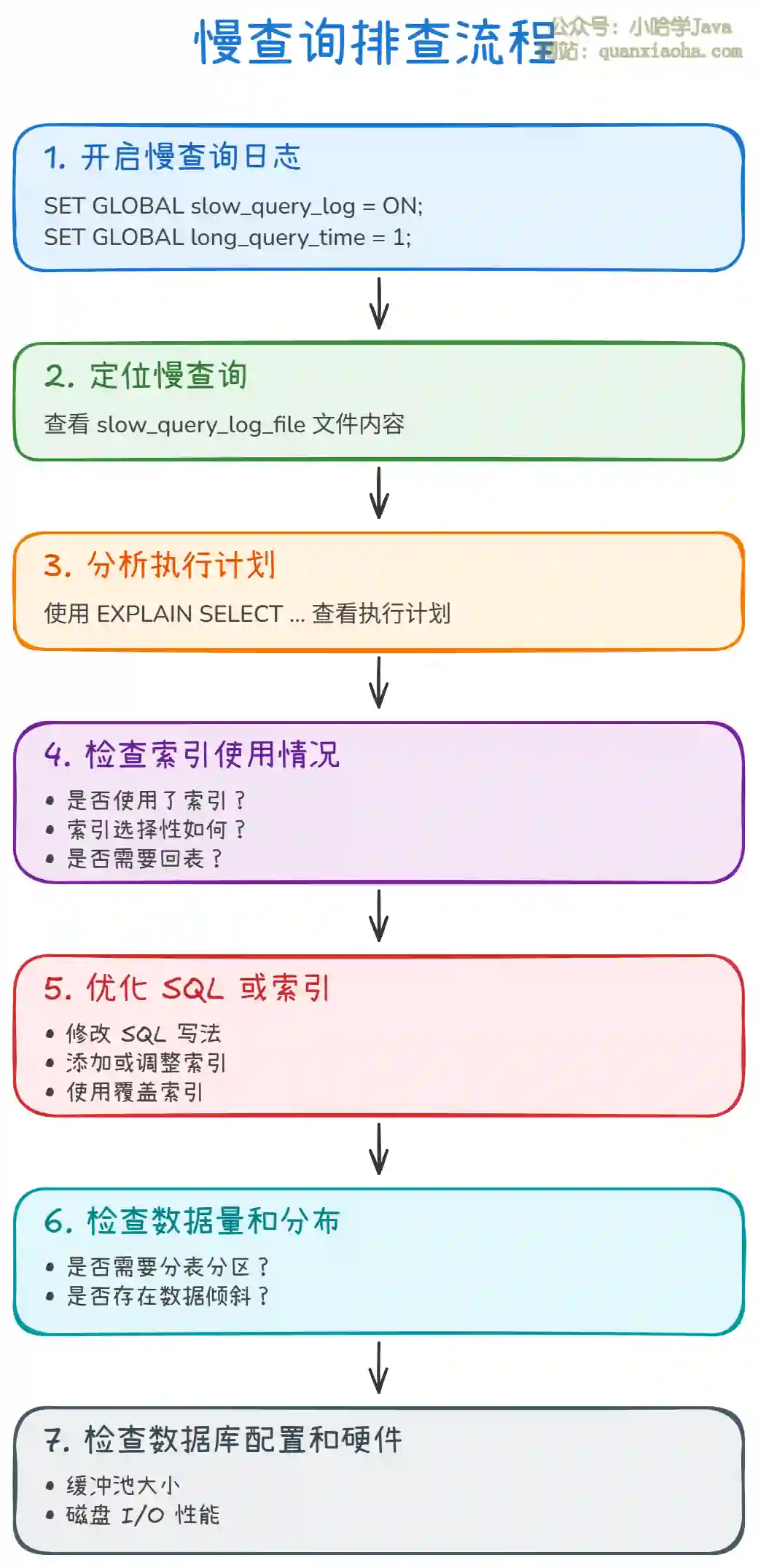
上图展示了完整的慢查询排查流程。从开启慢查询日志开始,到定位慢查询、分析执行计划、优化 SQL 或索引,最后检查数据量和数据库配置,形成闭环。
面试高频追问
-
什么是回表?如何避免回表?
回表是指通过二级索引找到主键 ID 后,再到聚簇索引中查找完整行数据的过程。可以通过覆盖索引(只查询索引列)来避免回表。
-
什么是覆盖索引?
覆盖索引是指查询的所有字段都包含在索引中,无需回表即可获取所有数据。例如:索引
idx_name_age(name, age),查询SELECT name, age FROM users WHERE name = '张三'就是覆盖索引。 -
如何判断索引是否生效?
使用
EXPLAIN查看执行计划,检查key字段(实际使用的索引)和type字段(访问类型)。type为ref、range、const等表示索引生效,ALL表示全表扫描。 -
什么情况下应该使用 FORCE INDEX?
当优化器选择的执行计划不是最优时(例如数据倾斜导致优化器误判),可以使用
FORCE INDEX强制使用特定索引。但要谨慎使用,因为数据分布可能变化。
常见面试变体
- "MySQL 索引失效的常见场景有哪些?"
- "如何优化 MySQL 慢查询?"
- "什么是覆盖索引?它有什么优势?"
- "联合索引的设计原则是什么?"
记忆口诀
索引失效六宗罪:SELECT * 回表多,LIKE % 前缀没,函数计算列上做,类型转换隐式错,最左前缀不能破,选择性差索引弱。
排查四步走:慢查询日志定位,EXPLAIN 看计划,索引设计要合理,配置硬件别忘记。
优化三板斧:覆盖索引减回表,字段类型要选好,分区分表数据少。
总结
即使使用了索引,查询仍然可能很慢,原因包括:索引选择性差、违反最左前缀原则、SELECT * 导致大量回表、LIKE '%xxx' 或函数操作导致索引失效、数据量过大或倾斜、数据库配置不当等。排查时使用 EXPLAIN 分析执行计划,重点关注 type、key、rows、Extra 字段,通过覆盖索引、优化 SQL 写法、调整索引设计、分区分表等手段进行优化。